Библиотека Cheerio для эффективного и удобного веб-скрейпинга

Работа многих специалистов в интернете предлагает сбор данных с веб-сайтов: маркетологов, SEO-специалистов, SMM-менеджеров и пр. Web Scraping может выполняться или путем парсинга или же через готовый API. Но выполнять данные работы самостоятельно не так просто, как может показаться на первый взгляд. Дело в том, что большая часть сайтов крайне негативно реагирует на действия скрейперов, прикладывая много усилий к тому, чтобы заблокировать их работу. О том, как избежать бана и обеспечить стабильный парсинг данных мы уже говорили ранее – предлагаем прочитать статью «Мобильные прокси для Web Scraping».
Сейчас же мы остановимся более подробно на готовых инструментах, которые оптимизируют, ускорят и частично автоматизируют ваши действия. В частности, познакомимся с одной из библиотеки Node.js – Cheerio. Рассмотрим ее функциональные возможности, а также распишем пошагово, как создать свой собственный парсер.
Знакомимся с функциональными возможностями библиотеки Cheerio
Cheerio – одна из библиотек для программного просмотра интернета. Если вы хотите создать с нуля свой собственный парсер на Node.js, то выбор стоит остановить именно на этом инструменте. Итак, речь идет об HTML-парсере, наделенном достаточно широкими функциональными возможностями, что существенно расширит ваши действия и позволит получить желаемый результат с минимальными затратами времени и усилий.
Среди основных моментов, которые стоит знать о библиотеке Cheerio выделим:
- данная библиотека представляет собой анализатор DOM, который может работать с файлами в форматах HTML и XML;
- представляет собой реализацию ядра jQuery, созданной специально для работы с сервером;
- максимальная эффективность при работе в качестве парсера обеспечивается совместной работой с клиентской библиотекой Node.js, как вариант, Axios.
- не предусмотрена возможность загрузки внешних ресурсов, использования CSS, то есть нет такого отображения сайта, как у браузера;
- при необходимости парсинга данных с ресурсов, созданных с использованием технологии React, могут возникнуть сложности: в основном это сайты-одностраничники (SPA).
- эта библиотека не имеет прямого взаимодействия с сайтами: не сможет буквально «нажимать на кнопки», получать доступ к информации, спрятанной за скриптами;
- очень простой и логически понятный синтаксис: гарантирует быстрое и простое освоение;
- быстрая скорость работы.
Теперь перейдем к примеру создания собственного парсера с использованием библиотеки Cheerio.
Последовательность действий по созданию парсера в Cheerio
Чтобы показать, как создается с нуля парсер в Cheerio, в качестве примера возьмем такую задачу, как извлечение ссылок на все блоги из достаточно популярной платформы для программирования In Plain English.
Работу начинаем с создания папки, в котором будет храниться наш код. Назовем ее «Scraper». Внутри самого парсера запускаем команду «npm init», если вы выбрали для работы «npm», либо же «yarn init», если ваш выбор остановился на «yarn». Этими действиями вы создали папку, в которой будут сохраняться соответствующие данные и инициализировали «package.json». Теперь можно переходить к установке пакетов. Выполняем следующие действия:
- Устанавливаем библиотеку Cheerio. Данная работа потребует от вас минимум времени и усилий. Достаточно будет просто запустить команду.

- Устанавливаем библиотеку Axios. Это популярное решение, предназначенное для выполнения в Node.js для выполнения HTTP-запросов к сайту, который планируем парсить. К слову, полезно будет почитать, чем отличаются между собой HTTP и SOCKS5-протоколы. Данная библиотека оптимально подходит для совершения вызовов API, получения данных с различных интернет-ресурсов и пр. В качестве ответа от сайта мы будем получать документ в формате HTML, который впоследствии можно анализировать и при помощи Cheerio вытаскивать нужную информацию. Чтобы установить Axios запускаем в терминале следующую команду.
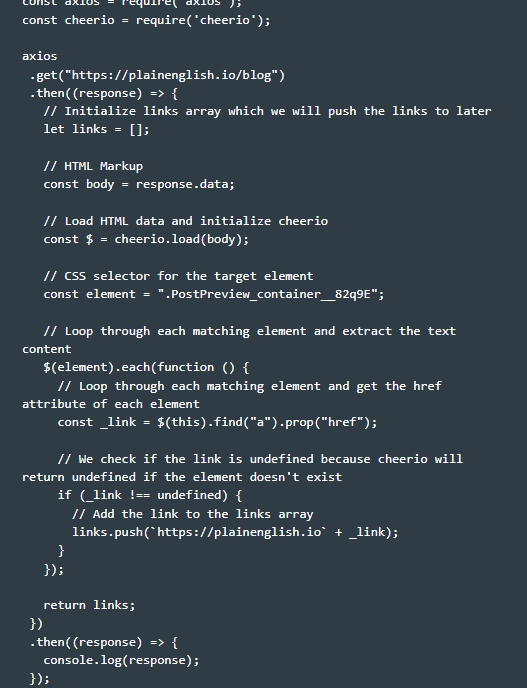
- Готовим парсер к работе. Для этого переходим в ранее созданную нами папку, а уже в ней формируем файл с именем «cheerio.js». На картинке приведена базовая структура кода, воспользовавшись которой вы сможете запустить парсинг страничек с сайтов с использованием библиотек Cheerio и Axios.
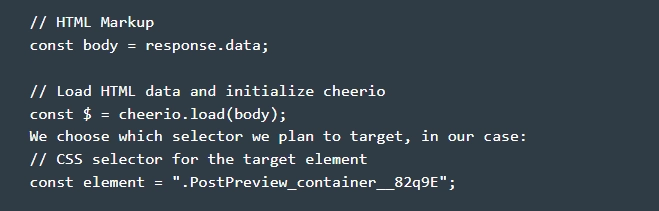
- Запрашиваем данные. Для этого нам необходимо запустить в работу Get-запрос. Отправляем его на сайт plainenglish.io/blog. Обратите внимание: библиотека Axios – асинхронная, поэтому нам необходимо связать функцию Get (…) с Then (…). Этим самым мы инициализируем пустой массив ссылок для того, чтобы собрать все те ссылки, которые планируем в данный момент парсить. Теперь осталось только перетащить файл «response.data» из библиотеки Axios в Cheerio. Для этого выполняем команду.
- Обрабатываем полученные данные. Внимательно просматриваем все элементы, в которых присутствует тег "а" и вытаскиваем из свойств «href» соответствующее значение. Каждое обнаруженное совпадение сразу же перемещаем в наш массив со ссылками. Обратите внимание: после завершения этих действий мы возвращаем ссылки и запускаем на выполнение еще одну цепочку then(…) и console.log ответа. На практике действия на данном этапе будут выглядеть так.
- Получаем конечные результаты. Теперь, после выполнения первых пяти шагов, мы можем непосредственно из папки парсера открыть терминал и запустить «node.js» и «cheerio.js». Этим самым вы выполните полный код из нашего рабочего файла «cheerio.js». Правильность выполненных вами действий подтвердит появление на консоли всех URL-адреса из массива ссылок, который мы использовали в работе. В общем, вы должны увидеть у себя на экране нечто подобное.



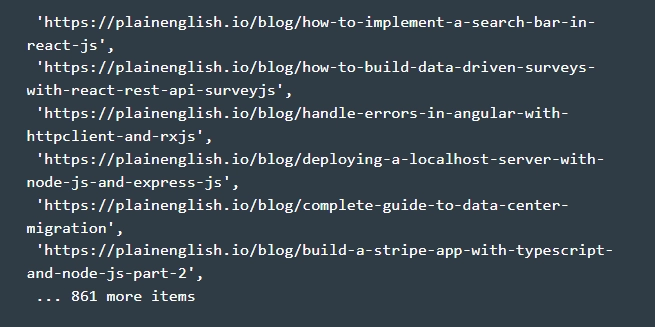
На этом парсинг данных при помощи библиотек Cheerio и Axios с сайта In Plain English завершен. При необходимости, полученные данные можно будет сохранить в виде файла, чтобы в последующем снова возвращаться к работе с ними, не прибегая к повторному парсингу. Как видите, буквально пару строк простого кода, и вы смогли извлечь данные с сайтов, которые станут основой вашей последующей работы. Как альтернативу Axios можно рассмотреть еще один HTTP-клиент – библиотеку Unirest.
Подводим итоги
Так когда стоит использовать в работе библиотеку Cheerio? Она будет оптимальным решением в случае, когда перед вами стоит задача парсинга данных со статических страниц без непосредственного взаимодействия с ними. То есть клики, отправка форм, сбор ссылок – это то, с чем Cheerio справиться быстро и эффективно. Но если предстоит работа с сайтами, использующими для внедрения контента JavaScript, то придется искать другое решение.
Также надо понимать, что максимальной эффективности скрейпинга данных можно достичь благодаря использованию в работе разных IP-адресов. Как это обеспечить? Подключить дополнительно к работе динамические мобильные прокси. Так вы сможете задать автоматическую смену адресов по таймеру или каждый раз пользоваться Get-запросом, чтобы принудительно поменять активный адрес на другой. Если вы остановите выбор на мобильных прокси от сервиса MobileProxy.Space, то получите доступ к практически миллионному пулу реальных адресов, которые операторы сотовых сетей выделяют своим клиентам. Также вы сможете менять по собственному усмотрению геолокацию и оператора, что позволит обходить любые региональные ограничения.
А еще данные мобильные прокси работают одновременно на протоколах соединения HTTP(S) и Socks5, обеспечивая абсолютную анонимность и конфиденциальность действий в сети, защиту от любого несанкционированного доступа. Вы сможете легко автоматизировать свои действия в интернете, не опасаясь получить за это бан. Более подробно об особенностях мобильных прокси MobileProxy.Space, а также актуальных тарифах можно познакомиться по ссылке https://mobileproxy.space/user.html?buyproxy. Также на сервис предусмотрена возможность бесплатного 2-х часового тестирования. Воспользуйтесь ею, чтобы убедиться, насколько удобной и эффективной может быть работа с надежными приватными мобильными прокси.