Индексный файл robots.txt: что это и зачем он нужен

Нередко тем, кто связан с раскруткой и продвижением интернет-ресурсов, кто работает над созданием сайтов, кто контролирует стабильность их работы, приходится сталкиваться с таким понятием, как индексный файл robots.txt. Вместе с xml-картой он несет себе наиболее важную информацию о портале: указывает ботам поисковых систем на то, как правильно читать данный сайт, какие страницы на нем несут наиболее важную информацию, а какие можно пропустить мимо и выбросить из рассмотрения. А еще именно этот файл стоит просматривать специалистам, в том случае, если по какой-то причине резко снизился трафик на ваш интернет-ресурс.
Сейчас познакомимся более подробно с тем, что же представляет собой файл robots.txt, зачем он нужен. Также удели внимание тому, как создать индексный файл максимально корректно. Еще расскажем об основных символах, которые используются в robots.txt, подскажем ошибки, которые нередко допускаются специалистами в процессе работы. А еще остановимся на том, как обеспечить максимально стабильную и безопасную работу в интернете с использованием мобильных прокси.
Знакомимся с файлом robots.txt
Индексный файл robots.txt — это обычный текстовый документ, созданный в кодировке UTF-8. Актуален он для протоколов HTTP, HTTPS, FTP. Предназначен он для того, чтобы предоставлять краулерам рекомендации в процессе сканирования страниц или же файлов. Дело в том, что в случае, когда файл построен не на UTF-8 символах, а какой-то другой кодировке, поисковые боты могут допустить ошибки в их обработке. Поэтому важно понимать, что все эти правила, которые приведены в индексном файле, будут актуальны только по отношению к тем хостам, номерам порта и протоколов, где размещается данный файл.
Располагается этот файл непосредственно в корневом каталоге как обычный текстовый документ. Вне зависимости от того, с какими устройствами и системами вы работаете, он будет доступен по стандартному адресу https://site.com.ua/robots.txt. Если говорить сугубо техническим языком, то индексный файл — это описание в форме Бекуса-Нуара, основанный на правилах RFS 822.
В любых иных файлах следует проставлять такие отметки как Byte Order Mark (ВОМ). Они представляют собой Юникод-символ, предназначенный для определения последовательности в байтах в процессе считывания параметров. Его кодовый символ выглядит как U+FEFF. Обратите внимание: отметка последовательности байтов в начале файла robots.txt — игнорируется. Также важно знать, что поисковая система Google на размер индексного файла выставила собственные ограничения в пределах 500 Кб.
Начиная работу со сканирования вашего сайта для последующей индексации, поисковые боты обрабатывают правила, содержащаяся в файле robots.txt и получают от него одну из трех инструкций:
- Предоставление частичного доступа. Предполагает возможность сканирования только отдельных элементов сайта.
- Предоставление полного запрета. Краулеру запрещено сканировать любое из страниц.
- Предоставление полного доступа. Поисковый робот может сканировать абсолютно все страницы интернет-ресурса.
В процессе сканирования индексного файла краулеры (почитайте здесь, что такое краулинг) могут получить следующий ответы:
- 2ХХ. Указывает на то, что сканирование реализовано удачно.
- 3ХХ. Свидетельствуют о том, что поисковый бот будет следовать по переадресации до того момента, пока не получит какой-либо иной ответ. В основном система выделяет 5 возможных попыток для получения ответа, которые будут отличаться от 3ХХ. По истечению данного лимита регистрируется ошибка 404.
- 4ХХ. В этом случае поисковый робот получает права на сканирование всего содержимого интернет-ресурса.
- 5ХХ. Подобные команды оцениваются как временные ошибки сервера. При этом сканирование полностью запрещается. Периодически робот будет возвращаться к данному индексному файлу до того момента, пока не получит ответ, отличающийся от 5ХХ. Дополнительно здесь поисковый бот Google сможет определить корректность настройки отдачи ответа с тех страниц сайта, которые отсутствуют. То есть страница все равно будет обрабатываться с кодом ответа 404.
Информации о том, как будет обрабатываться индексный файл в случае его недоступности ввиду проблем с интернет-соединением, пока еще нет.
Кому и зачем может потребоваться в работе файл robots.txt?
Мы уже говорили выше, что данный индексный файл — это инструмент для работы специалистов, которые следят за работоспособностью сайта и его продвижением в результатах поисковой выдачи. Использовать robots.txt стоит тогда, когда вы хотите запретить караулерам сканирование следующих страниц:
- с личной информацией пользователей, находящихся на сайте;
- с теми или иными формами отправки данных;
- с результатами поиска.
Также вы можете выставить запрет на посещение сайтов-зеркал. Также важно понимать, что даже в том случае, когда страничка будет находиться внутри файла robots.txt, она все равно может появиться в результатах выдачи. Это актуально для случаев, когда на нее присутствует соответствующая ссылка либо же на каком-то внешнем ресурсе, либо же внутри сайта. Получается, что без индексного файла, вся та информация, которую необходимо скрыть от сторонних глаз все же может попасть в выдачу. Это способно нанести существенный вред как вашему ресурсу, так и вам лично.
В работе все выглядит достаточно просто. Как только поисковик Google натыкается на файл robots.txt, то от автоматически понимает, что ему надо найти соответствующие правила и выполнить сканирование сайта в соответствии с ними.
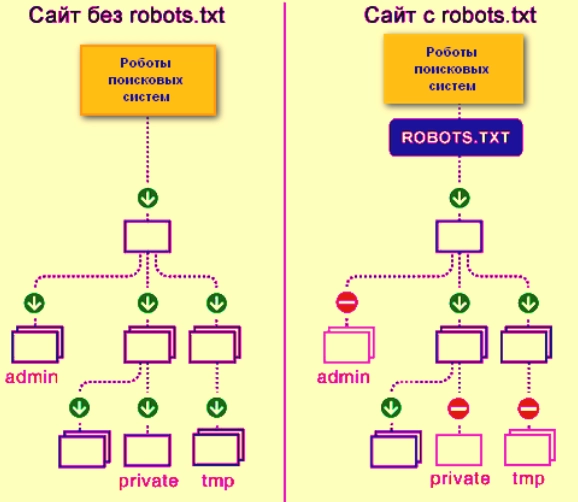
На картинке наглядно видно, как выглядит сканирование сайта без файла robots.txt и с ним:
Создаем индексный файл правильно
Создать файл robots.txt можно при помощи любого текстового редактора, в том числе скопировать. В содержании данного файла должна быть прописана:
- Полная инструкция User-agent.
- Правила Disallow.
- Правила Allow.
- Правила Sitemap.
- Правила к Crawl-delay.
- Правила Clean-param.
Рассмотрим все эти моменты более подробно.
User-agent, как визитка для роботов
User-agent — это правило, указывающая на то, каким именно ботом необходимо смотреть на инструкции, приведенные в файле robots.txt. На сегодня существует свыше 300 поисковых краулеров. Поэтому нет смысла прописывать все их по отдельности. Более простое и надежное решение — использование одной записи для всех. У Гугл есть свой собственный главный бот — Googlebot. На данном этапе вы можете указать то, что правила необходимо просматривать именно данному поисковому роботу. Другие краулеры будут напрямую сканировать сайт, считая, что индексный файл пустой.
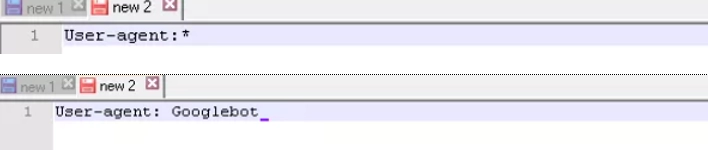
На картинке в верхней строке приведен вариант записи правила User-agent для всех поисковиков, а в нижнее— только для Googlebot.
Также рекомендуем вам обратить внимание на ряд иных специальных ботов, оптимизированных под сканирование тех или иных типов файлов:
- Mediapartners-Google — для сервиса AdSense;
- Googlebot-Image — для работы с изображениями;
- AdsBot-Google — для проверки качества целевой страницы;
- Googlebot-Video — для видео-файлов;
- Googlebot-Mobile — для мобильной версии софтов.
Правила Disallow
Disallow предоставляет поисковым ботам рекомендации относительно того, какие именно параметры им стоит исключить из сканирования.
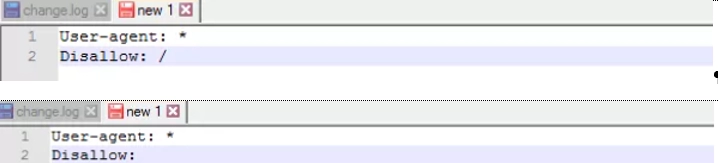
В верхней строке вы видите пример того, как запретить для сканирования весь материал на сайте, а в нижней— дает разрешение на полное сканирование сайта. Первый вариант стоит использовать в том случае, если ваш сайт еще находится на стадии доработок, и вы не хотите, чтобы он в подобном виде отображался в результатах поисковой выдачи. Как только работы по настройке ресурса будут завершены, важно будет исправить данное правило, тем самым сделав свой сайт доступным целевой аудитории. Этот момент обязательно надо учитывать вебмастеру.
Также есть возможность через данное правило предоставить роботам инструкцию, содержащую запрет на просмотр содержимого папки, определенного URL-адреса, того или иного файла и даже файлов определенного расширения.
Правила Allow
Данное правило предполагает предоставление разрешения на сканирование определенного файла, страницы или же директива. Как Allow, так и Disallow сортируются по длине префикса URL, начиная от меньшего и переходя к большим. Применяются они последовательно. В том случае, если для одной и той же страницы могут использоваться несколько правил, поисковый робот будет ориентироваться на то, которое окажется последним в отсортированном списке.
В качестве примера покажем, как дать ботам допуск на просмотр только тех страниц, которые бы начинались с /catalog. При этом весь остальной контент останется закрытым.

Правила Sitemap
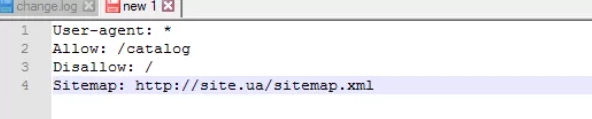
Sitemap — это своего рода медицинская карта сайта. Она сообщает поисковым ботом все те URL-адреса, которые будут обязательными для сканирования. Находятся они по стандартному адресу https://site.ua/sitemap.xml. Каждый раз, выполняя обход, кроулер будет проверять, какие изменения вносились в данный документ, и уже на основании этого будет вносить более свежую и актуальную информацию о сайте в базу данных браузера.
На картинке вы видите пример того, как данная инструкция должна быть вписана в этот файл.
Правила Crawl-delay
Crawl-delay – это параметр, позволяющий задавать интервал, через который будет осуществляться загрузка страниц сайта. Особенно актуальным данное правило будет в том случае, когда вы работаете с достаточно слабого сервера, то есть возможны существенные задержки в процессе обращения бота к страницам ресурса. Обратите внимание: данный параметр следует задавать в секундах. А также важно знать, что на сегодня Google данную директиву уже не поддерживает, но она остается актуальной для других поисковых систем.
Пример задания секундомера для слабых серверов:

Правила Clean-param
Clean-param. Данное правило обеспечивает эффективную борьбу с GET-параметрами с целью избежание дублирование контента. Найти его можно по разным динамическим адресам (присутствует в названии знак вопроса). появляться такие адреса будут в том случае, если на сайте присутствует различные сортировки, в том числе и ID-сессии.
На картинке приведены адреса, по которым будет доступна определенная страница, а также то, как будет выглядеть файл robots.txt для этого случая.
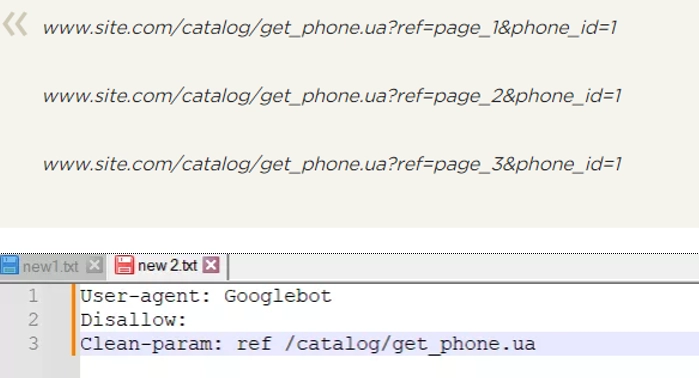
Обратите внимание что опция REF здесь записывается в самом начале, так как она указывает на то, откуда именно идет данная ссылка.
Немного о символах в индексном файле
При работе с индексным файлом в основном используется четыре разных типа символа:
- Слэш. Он используется для того, чтобы поделить то, что мы хотим закрыть от обнаружения поисковыми ботами. Если слэш будет один, то предполагается запрет на полное сканирование сайта от Disallow. Если слэшем вами выделена отдельная директория с двух сторон, это значит, что запрещено именно ее сканирование.
- Звездочка. Указывает на любую последовательность символов файле. Проставляется после каждого правила.
- Знак доллара. Предполагает ограничение действия знака «звездочка». Используется в том случае, когда необходимо запретить сканирование всего содержимого папки, но нельзя запретить URL-адреса, содержащие название этой папки.
- Решетка предназначена для прописания комментариев. С ее помощью веб мастер может оставлять заметки как сам себе, так и своим коллегам. Поисковые роботы при сканировании сайта их учитывать не будут.
Ряд моментов, которые надо учитывать при работе с индексным файлом
После того, как вы заполните файл robots.txt, его необходимо проверить на корректность. Для этого используется специальный онлайн инструмент от в мастеров поисковой системы Гугл. Вам необходимо будет зайти на него и ввести ссылку на проверяемый сайт.
При заполнение индексного файла, нередко специалисты допускают ряд ошибок. Большая часть из них связана со спешкой или невнимательностью. Наиболее часто встречается:
- перепутанные инструкции;
- запись в одной инструкции Disallow нескольких папок либо же директории: должны прописываться каждая в новом ряду;
- правильная запись файла — исключительно robots.txt, а не Robots.txt, ROBOTS.TXT либо же прочие вариации;
- оставление пустым правила User-agent: обязательно надо указать какой именно робот должен учитывать правила, прописанные в вашем файле;
- наличие лишних знаков в файле, в том числе слэшей, звездочек и пр.;
- добавление в файл страниц, которые априори не должны индексироваться.
Как обеспечить стабильную работу вебмастера в интернете?
Работа вебмастеров часто сопряжена с повышенными рисками. Существует высокая вероятность подхватить вирусное программное обеспечение, стать жертвой вредоносного хакерского воздействия и пр. К тому же им важно обеспечить многопоточность действий для того, чтобы разработать максимально комплексную стратегию развития того или иного ресурса. С решением данных задач эффективно справятся мобильные прокси от сервиса MobileProxy.Space. С их помощью вы сможете:
- эффективно обходить региональные блокировки;
- обеспечить себе полную анонимность и конфиденциальность действие сети;
- защититься от любого несанкционированного доступа, в том числе хакерских атак;
- работать в многопоточном режиме, в том числе с использованием программ для автоматизации действий.
Пройдите по ссылке https://mobileproxy.space/user.html?buyproxy, чтобы более подробно познакомиться с его функциональными возможностями и тарифами мобильных прокси, а также воспользоваться бесплатным двухчасовым тестированием продукта еще до его покупки.