Jak zebrać semantyczne jądro konkurentów regionalnie za pomocą mobilnych proxy: przewodnik krok po kroku
Spis treści
- Wprowadzenie
- Przygotowanie wstępne
- Podstawowe pojęcia
- Krok 1: określenie celowych zapytań i listy regionów
- Krok 2: konfiguracja mobilnych proxy według miast i potwierdzenie geolokalizacji
- Krok 3: przygotowanie środowiska pythona i struktury projektu
- Krok 4: tworzymy listę bezpośrednich konkurentów dla każdego regionu
- Krok 5: parsowanie top-50 wyników według zapytań i miast (google i yandex)
- Krok 6: czyszczenie, normalizacja i wydobycie domen
- Krok 7: klasteryzacja zebranej semantyki według intencji
- Krok 8: łączenie danych i przygotowanie analiz
- Krok 9: analiza różnic w wynikach według regionów i lokalizacji zapytań
- Weryfikacja rezultatu
- Typowe błędy i rozwiązania
- Dodatkowe możliwości
- Faq
- Podsumowanie
Wprowadzenie
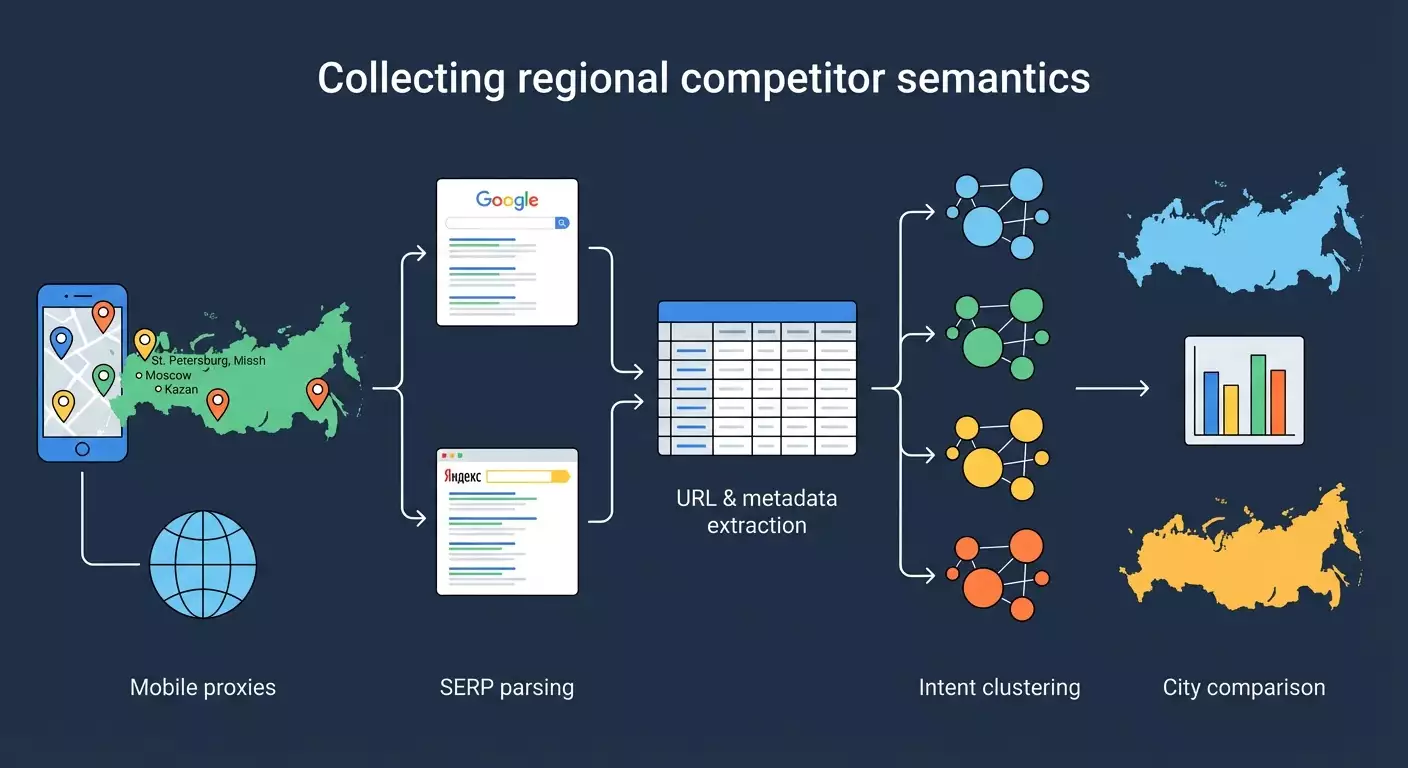
W tym przewodniku krok po kroku nauczysz się, jak zbierać semantyczne jądro konkurentów w różnych regionach Polski, wykorzystując mobilne proxy, parsowanie wyników wyszukiwania Google i Yandex, a także narzędzia do grupowania i analizy. Przejdziemy przez cały proces od podstaw: przygotowanie środowiska, konfiguracja proxy w miastach, parsowanie top-50 wyników dla wybranych zapytań, wydobywanie URL, tytułów, opisów, pozycji, klasteryzacja zebranej semantyki według intencji (informacyjnej, komercyjnej, nawigacyjnej), porównanie wyników według regionów oraz przygotowanie praktycznego raportu do rozwiązań SEO.
W efekcie otrzymasz: 1) listę konkurentów w każdym mieście, 2) tabelę słów kluczowych, według których konkurenci plasują się w różnych regionach, 3) metryki różnic regionalnych wyników i lokalizacji zapytań, 4) pogrupowane klastry intencji dla oszczędności budżetu i priorytetyzacji treści, 5) powtarzalny proces, który można uruchamiać co miesiąc.
Ten przewodnik jest odpowiedni dla specjalistów SEO, marketerów internetowych, analityków, a także dla wszystkich, którzy chcą zrozumieć, jak działa lokalne wyniki wyszukiwania i jak szybko wydobyć użyteczne dane do podejmowania decyzji. Poziom trudności — dla początkujących z elementami dla zaawansowanych. Nie wymagamy głębokich umiejętności programistycznych, ale minimalna praca z Pythonem będzie przydatna.
Co należy wiedzieć wcześniej: podstawowa wiedza o SEO, jak powstają snippety, czym różnią się zapytania informacyjne i komercyjne, jak pracować z CSV/Excel. Ile czasu to zajmie: przy gotowych zapytaniach i liście miast — 6–10 godzin na pierwszy raz, 1–3 godziny na kolejne iteracje.
✅ Weryfikacja: Rozumiesz, że otrzymasz konkretną listę konkurentów w miastach, ogólną i unikalną semantykę oraz będziesz mógł wyjaśnić, które zapytania są zlokalizowane i jak wykorzystać to w regionalnym SEO.
Przygotowanie wstępne
Potrzebne narzędzia: 1) Konto i dostęp do mobilnych proxy mobileproxy.space z miastami w Polsce (Warszawa, Kraków, Wrocław, Poznań, Gdańsk i inne zgodnie z twoim zadaniem). 2) Python 3.10+ i menedżer pakietów pip. 3) Biblioteki Pythona: requests, beautifulsoup4, lxml, pandas, urllib3, tldextract (do wydobywania domen). 4) Edytor tekstu (VS Code lub jego odpowiednik). 5) Edytor arkuszy kalkulacyjnych (Excel, Google Arkusze lub LibreOffice Calc). 6) Key Collector na Windows do grupowania i klasteryzacji zapytań. 7) Terminal lub wiersz poleceń. 8) Opcjonalnie: curl do szybkiego sprawdzenia proxy. 9) Dostęp do przeglądarki do sprawdzenia geo przez Yandex.Internetometr (strona od Yandexa do sprawdzania geolokalizacji IP).
Wymagania systemowe: Windows 10/11 lub macOS 12+ lub Linux (Ubuntu 22.04+), minimum 8 GB RAM, stabilny internet 10 Mbps+, wolne miejsce na dysku 2–5 GB na dane i logi.
Co należy zainstalować: 1) Zainstaluj najnowszą stabilną wersję Pythona. 2) Zainstaluj Key Collector na Windows. 3) Utwórz konto na mobileproxy.space, zasil konto i zakup proxy dla wymaganych miast (1 proxy na miasto, lepiej 2–3 dla rozłożenia obciążenia). 4) Zainstaluj biblioteki: w terminalu wykonaj: pip install requests beautifulsoup4 lxml pandas urllib3 tldextract. 5) Skonfiguruj edytor tekstu i terminal.
Tworzenie kopii zapasowych: utwórz folder projektu z podfolderami data/raw, data/clean, reports, config, logs i okresowo kopiuj pliki CSV do folderu zapasowego lub do chmury.
⚠️ Uwaga: Upewnij się, że twoje działania są zgodne z przepisami prawnymi i zasadami serwisów. Niektóre wyszukiwarki ograniczają zautomatyzowane zbieranie danych. Używaj rozsądnych ograniczeń zapytań, czytaj robots.txt, przestrzegaj zasad i rozważ oficjalne API jako preferowaną metodę.
Porada: Utwórz wirtualne środowisko Pythona (python -m venv .venv a następnie aktywuj) i zabezpiecz zależności w requirements.txt, aby łatwo przenosić projekt.
✅ Weryfikacja: W terminalu, komendy python --version i pip --version działają, biblioteki zostały zainstalowane bez błędów, masz dostęp do przynajmniej jednego proxy dla Warszawy i możesz otworzyć Yandex.Internetometr w przeglądarce.
Podstawowe pojęcia
Kluczowe terminy prostym językiem: 1) Semantyczne jądro — lista zapytań, z którymi chcesz się plasować lub analizujesz konkurentów. 2) Wyniki regionalne — wyniki wyszukiwania dostosowane do lokalizacji użytkownika (miasto, region). 3) Mobilne proxy — serwery proxy na bazie operatorów mobilnych, które pozwalają na symulowanie ruchu z prawdziwych adresów IP na urządzeniach mobilnych i, co najważniejsze, wybór miasta. 4) Parsowanie SERP — wydobywanie danych z strony wyników wyszukiwania (URL, tytuł, snippet, pozycja). 5) Intencja — przypuszczalny cel użytkownika: informacyjny (dowiedzieć się), komercyjny (kupić/zamówić), nawigacyjny (znaleźć konkretną stronę). 6) Top-50 — pierwsze 50 wyników organicznych, bez reklamy.
Główne zasady działania: wysyłamy zapytanie do wyszukiwarki, wskazujemy proxy, aby ustalić geo, otrzymujemy stronę HTML, wydobywamy potrzebne elementy, zapisujemy je w tabeli. Powtarzamy dla każdego miasta i każdego zapytania. Następnie grupujemy i analizujemy.
Co ważne zrozumieć: 1) W różnych miastach zestaw domen i stron w topie może się różnić. 2) Zlokalizowane zapytania często zawierają nazwy miast lub sugerują lokalną intencję (np. dostawa, blisko, adres). 3) Zbyt częste zapytania bez przerw mogą wywołać captcha lub blokady. 4) Poprawna weryfikacja geo — kluczowa. 5) Część wyników może być spersonalizowana; używaj czystych sesji, bez autoryzacji.
Porada: Podczas analizy zwracaj uwagę nie tylko na słowa kluczowe, ale i domeny konkurentów oraz typ treści, aby wybrać właściwą strategię (strony lokalne, katalogi, artykuły, landing page).
Krok 1: Określenie celowych zapytań i listy regionów
Cel etapu
Uformować początkową listę zapytań oraz zestaw miast, z których będziemy zbierać wyniki. To baza do parsowania i porównania.
Instrukcja krok po kroku
- Otwórz arkusz kalkulacyjny (Excel lub Google Arkusze) i utwórz arkusz Seeds.
- W kolumnie A wymień podstawowe zapytania, które odzwierciedlają twój produkt lub niszę. Na przykład: „dostawa wody”, „naprawa laptopów”, „zakup mebli” itd.
- W kolumnie B dodaj doprecyzowania lub synonimy, jeśli są istotne. Na przykład: „woda pitna”, „naprawa MacBooka”, „szafa przesuwna”.
- Utwórz arkusz Cities. W kolumnie A wymień miasta: Warszawa, Kraków, Wrocław, Poznań, Gdańsk, Łódź, Katowice, Szczecin, Bydgoszcz, Toruń i inne docelowe regiony.
- Określ priorytet: wybierz 10–15 najważniejszych miast z najwyższym popytem.
- Uformuj listę celowych zapytań, łącząc podstawowe i doprecyzowania. Na przykład: „dostawa wody”, „dostawa wody do domu”, „woda pitna dostawa”, „naprawa laptopów”, „naprawa laptopów na wczoraj”.
- Zapisz arkusz w folderze data/raw jako seeds_and_cities.xlsx.
Ważne punkty: Nie dodawaj jeszcze nazw miast do zapytań, aby ocenić lokalizację bez wyraźnego geo. Później sprawdzisz też z modyfikatorami geo.
Porada: Ogranicz listę do 50–200 zapytań na pierwszy raz, aby nie przeciążać proxy i nie tracić zbędnego czasu.
✅ Weryfikacja: Masz jeden plik z 50–200 zapytaniami oraz 10–15 miastami. Zapytania są zrozumiałe i odpowiadają celom biznesowym.
Możliwe problemy i rozwiązania: jeśli masz trudności w uformowaniu listy, weź dane z wewnętrznych sugestii wyszukiwania na twojej stronie, czaty z klientami, listę usług i kategorii produktów. Następnie rozszerziaj sugestie podczas wyszukiwania ręcznie.
Krok 2: Konfiguracja mobilnych proxy według miast i potwierdzenie geolokalizacji
Cel etapu
Podłączyć mobilne proxy z mobileproxy.space dla każdego miasta, sprawdzić, czy IP rzeczywiście odpowiada potrzebnemu miastu za pomocą Yandex.Internetometr.
Instrukcja krok po kroku
- Wejdź na swoje konto w mobileproxy.space. Wybierz plan z możliwością wyboru miasta i operatora. Weź przynajmniej jedno proxy dla każdego miasta z twojej listy. Optymalnie — 2–3 proxy na miasto.
- Zanotuj dla każdego proxy: host, port, login i hasło. Na przykład: proxy.example.host:12345, user:pass.
- Jeśli obsługiwane jest rotowanie przez link lub API, zapisz link do zmiany IP. To przyda się do resetowania sesji przy captcha.
- Utwórz plik config/proxies.csv z kolumnami city, host, port, user, password, rotation_url (jeśli jest) i wypełnij go.
- Otwórz przeglądarkę, włącz systemowe lub przeglądarkowe proxy dla Warszawy i odwiedź usługę sprawdzania IP i geolokalizacji od Yandexa (Yandex.Internetometr). Upewnij się, że miasto jest rozpoznawane jako Warszawa.
- Powtórz weryfikację dla Krakowa, Wrocławia i innych miast, zmieniając ustawienia proxy.
- Wyłącz proxy w przeglądarce. W dalszej kolejności weryfikacja geolokalizacji będzie odbywać się programowo.
⚠️ Uwaga: Używaj proxy tylko zgodnie z warunkami serwisu i prawem. Celem proxy jest poprawne ustalenie geo i równomierne rozłożenie obciążenia, a nie obchodzenie ograniczeń.
Porada: Ustaw prosty czas oczekiwania: po zmianie proxy poczekaj 10–20 sekund przed sprawdzeniem geolokalizacji, aby uniknąć „cache” lub opóźnienia w sieci.
✅ Weryfikacja: Dla każdego miasta możesz włączyć odpowiednie proxy i zobaczyć poprawne miasto w Yandex.Internetometrze.
Problemy i rozwiązania: jeśli miasto rozpoznawane jest nieprawidłowo, zmień IP przez rotację, weź innego operatora w tym samym mieście lub skontaktuj się z pomocą techniczną. Jeśli przeglądarka ignoruje proxy, sprawdź ustawienia i autoryzację.
Krok 3: Przygotowanie środowiska Pythona i struktury projektu
Cel etapu
Stworzyć stabilne środowisko do parsowania i analizy: struktura katalogów, zależności, z testem połączenia przez proxy.
Instrukcja krok po kroku
- Utwórz folder projektu, na przykład regional-serp-competitors.
- Wewnątrz utwórz podfoldery: config, data/raw, data/clean, logs, reports, scripts.
- Utwórz wirtualne środowisko: w terminalu wykonaj “python -m venv .venv” i aktywuj je (Windows: “.venv\Scripts\activate”, macOS/Linux: “source .venv/bin/activate”).
- Zainstaluj zależności: “pip install requests beautifulsoup4 lxml pandas urllib3 tldextract”.
- Stwórz plik config/settings.yaml. Wprowadź tam podstawowe parametry: czasy oczekiwania, opóźnienia (na przykład delay_min: 3, delay_max: 8), maksymalne próby powtórzeń (retries: 3), user-agent.
- Utwórz skrypt scripts/test_proxy_geo.py, który załaduje stronę Yandex.Internetometr przez jedno z proxy i wydrukuje miasto określone w HTML.
- W skrypcie skonfiguruj proxy jako słownik w formacie: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"} i dokonaj żądania requests.get do strony sprawdzania IP, następnie znajdź w HTML węzeł z miastem (po tekście “Miasto” lub podobnym elemencie).
- Uruchom skrypt dla kilku miast i upewnij się, że wynik zgadza się z oczekiwanym.
Porada: Ustal jednolity User-Agent, na przykład “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0 Safari/537.36”, i, jeśli to konieczne, zmieniaj go co 20–50 zapytań.
✅ Weryfikacja: Skrypt test_proxy_geo.py poprawnie wydaje różne miasta przy zmianie proxy. W logach nie ma stałych czasów oczekiwania ani błędów autoryzacji.
Problemy i rozwiązania: jeśli requests uzyskuje 407 Proxy Authentication Required, sprawdź login i hasło, eskalację znaków. Jeśli pojawia się captcha, zwiększ czasy oczekiwania i włącz rotację IP rzadziej i łagodniej.
Krok 4: Tworzymy listę bezpośrednich konkurentów dla każdego regionu
Cel etapu
Określić domeny konkurentów w każdym mieście, aby śledzić ich ranking i zbierać semantykę.
Instrukcja krok po kroku
- Wybierz 5–10 kluczowych zapytań z twojej listy, które dokładnie odzwierciedlają docelową usługę lub produkt bez doprecyzowań geo.
- Utwórz skrypt scripts/collect_competitors.py. Dla każdego miasta wybierz odpowiednie proxy. Dla każdego z wybranych zapytań wyślij wyszukiwanie w Yandex i Google kolejno.
- Dla Yandexa użyj parametrów zapytania uwzględniających język i region. Na przykład dodaj lr (kod regionu), jeśli go znasz, w przeciwnym razie polegaj na geo proxy.
- Dla Google ustaw parametry hl=pl, gl=pl. Geo zostanie określone przez IP; dodatkowo możesz testować bezpieczne parametry wyszukiwania.
- Wydobywaj pierwsze 20–30 wyników organicznych. Pomijaj bloki reklamowe, usługi i magiczne wtyczki, jeśli nie są to cele.
- Normalizuj domeny z pomocą tldextract. Zachowaj dla każdego miasta częstotliwość występowania domen: domena, ile razy występuje w topie, przy jakich zapytaniach.
- Uformuj tabelę data/raw/competitors_by_city.csv z kolumnami city, domain, engine, frequency, queries.
Ważne punkty: Personalizowane usługi (mapy, marketplace) mogą dominować. Zatrzymaj je, jeśli są naprawdę konkurentami w wynikach. Jeśli działasz w B2B, filtruj agregatory wiadomości.
Porada: Dodatkowo stwórz „ręczne sprawdzenie” dla 1–2 zapytań w każdym mieście w twojej przeglądarce przez odpowiednie proxy i porównaj domeny z wynikami skryptu. Zwiększy to pewność co do dokładności parsowania.
✅ Weryfikacja: Dla każdego miasta jest lista 10–30 domen z oznaczeniem częstotliwości. W topie znajdują się strony lokalne oraz federalni gracze. Dane z skryptu są zbliżone do ręcznego sprawdzenia.
Problemy i rozwiązania: rozbieżności w manualnej weryfikacji mogą wynikać z dynamiki wyników, personalizacji lub niewłaściwej filtracji bloków reklamowych. Zwiększ czasy oczekiwania, użyj czystej sesji i dodatkowych weryfikacji.
Krok 5: Parsowanie top-50 wyników według zapytań i miast (Google i Yandex)
Cel etapu
Zebrać szczegółową tabelę wyników: URL, tytuł, opis, pozycja, wyszukiwarka, miasto, zapytanie.
Instrukcja krok po kroku
- Utwórz skrypt scripts/serp_scraper.py. Struktura: funkcje do zapytań do Yandexa i Google, funkcja do parsowania HTML, zapisywanie linii w CSV.
- Stwórz konfigurację z parametrami: liczba wyników per_city_per_query_limit: 50, czasy oczekiwania delay_min, delay_max, maksymalne powtórzenia retries: 3, lista User-Agentów.
- Formuj URL wyszukiwania. Przykład Google: “https://www.google.com/search?q=zapytanie&num=50&hl=pl&gl=pl&pws=0”. Przykład Yandexa: “https://yandex.pl/search/?text=zapytanie&lr=kod_regionu&numdoc=50”, jeśli lr jest nieznane, polegaj na IP geo.
- Ustaw proxy przez miasto. Słownik proxy: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"}.
- Żądaj strony z czasem oczekiwania 20–30 sekund. Obsługuj błędy: czasy oczekiwania, 429, 5xx. W przypadku błędów zrób przerwę 30–60 sekund i powtarzaj to samo z tym samym proxy.
- Parsowanie Google: znajdź kontenery wyników: bloki z tagami h3 dla nagłówków i linkami, snippety w sąsiednich div/span. Wykluczaj linki do pamięci podręcznej, obrazy, filmy, reklamy. Jeśli struktura się różni, używaj wszystkich znalezionych “a” z widocznym tytułem w bloku wyników i filtruj według domen.
- Parsowanie Yandexa: szukaj organicznych kart wyników. Wydobądź “a” z linkiem do wyniku, tytuł, tekst podpowiedzi. Wykluczaj magiczne wtyczki (mapy, katalog), jeśli nie są brane pod uwagę w analizy, w przeciwnym razie oznacz je jako type=feature.
- Numeruj pozycje od 1 do 50 w kolejności pojawiania się wyników. Dla wyników Yandexa i Google, pozycja jest liczona wśród organicznych kart.
- Zapisuj linie z kolumnami: engine, city, query, position, url, title, snippet, fetched_at (data/czas), proxy_id.
- Uruchamiaj zbieranie kolejno według miast. Dla każdego miasta przetestuj wszystkie zapytania. Między zapytaniami rób przerwę 3–8 sekund, między miastami 10–20 sekund.
- Zapisz dane w data/raw/serp_results.csv. Duplikuj co godzinę kopię z prefiksem daty w folderze kopii zapasowej.
⚠️ Uwaga: Niektóre wyszukiwarki nie zezwalają na zautomatyzowane zbieranie. Rozważ oficjalne API (np. Google Custom Search API) lub wyspecjalizowane serwisy. Jeśli mimo to parsujesz HTML, rób to oszczędnie i minimalnie, tylko do celów analitycznych, przestrzegając limitów.
Porada: Rozłóż parsowanie na wczesny poranek lub późny wieczór, kiedy obciążenie jest mniejsze. Losowe przerwy i zmiany User-Agent zmniejszają prawdopodobieństwo captcha.
✅ Weryfikacja: W końcowym CSV powinny być wpisy dla każdego miasta i zapytania, po 50 wyników dla kombinacji. Pola powinny być wypełnione, URL poprawne, pozycje powinny być w kolejności.
Problemy i rozwiązania: jeśli pojawia się captcha, zwiększ przerwy, zmniejsz liczbę równoczesnych zapytań, używaj rotacji IP nie częściej niż co 2–5 minut. Jeśli struktura HTML się zmieniła, zaktualizuj selektory i przyspiesz ręczne sprawdzenie na 2–3 zapytaniach.
Krok 6: Czyszczenie, normalizacja i wydobycie domen
Cel etapu
Przygotować dane do analizy: usunąć śmieci, znormalizować URL, wydobyć domeny, wykluczyć nieistotne elementy.
Instrukcja krok po kroku
- Załaduj CSV do pandas (skrypt scripts/clean_results.py). Sprawdź obecność pustych tytułów/snippetów i w razie potrzeby przywróć z alternatywnych węzłów HTML.
- Filtruj duplikaty wierszy według (engine, city, query, url). Zostaw pierwsze wystąpienie.
- Wyklucz wewnętrzne linki wyszukiwarek, przekierowania do pamięci podręcznej, linki do map lub wiadomości, jeśli nie są potrzebne. Dodaj flagę type=organic dla czystych organicznych wyników.
- Normalizuj URL: usuń kotwice, przekształć schemat na https, usuń parametry śledzenia (utm_*, gclid itp.). Zapisz oczyszczony URL w osobnej kolumnie clean_url.
- Za pomocą tldextract uzyskaj domenę drugiego poziomu i strefę. Zapisz w kolumnie root_domain, na przykład “site.pl”.
- Zapisz oczyszczony plik w data/clean/serp_results_clean.csv.
Porada: Od razu dodaj kolumnę is_local_feature dla wyników typu mapy/katalogu/marketplace, aby w analizie szybko oddzielić je od zwykłych stron.
✅ Weryfikacja: Liczba wierszy zmniejszyła się na skutek usunięcia duplikatów i śmieci, domeny zostały prawidłowo wydobyte, nie ma linków służbowych. Możesz policzyć unikalne root_domain według miasta i zapytania.
Problemy i rozwiązania: jeśli zbyt wiele wyników oznaczonych jest jako śmieci, sprawdź filtry i określ zasady. Czasami warto pozostawić duże agregatory dla pełnopsotrzebnej obrazka.
Krok 7: Klasteryzacja zebranej semantyki według intencji
Cel etapu
Podzielić kluczowe frazy na grupy według intencji i tematycznych klastrów, aby zrozumieć, jaki typ treści i strony są potrzebne do regionalnego promowania.
Instrukcja krok po kroku
- Stwórz listę unikalnych zapytań z danych parsowania: weź kolumnę query i usuń duplikaty. Zapisz w data/clean/unique_queries.csv.
- Otwórz Key Collector na Windows i utwórz nowy projekt: Plik → Nowy projekt. Podaj nazwę projektu, na przykład “Regional SERP Competitors”.
- Importuj listę zapytań: menu Import → Z pliku → wybierz unique_queries.csv. Upewnij się, że kodowanie to UTF-8.
- Stwórz grupy tematyczne. W Key Collector użyj narzędzia do klasteryzacji według morfologii lub ogólnych słów. Zacznij od umiarkowanych progów podobieństwa (na przykład 3 wspólne terminy), a następnie ręcznie popraw grupy.
- Oznacz każdą grupę według intencji: informacyjnej, komercyjnej, nawigacyjnej. W tym celu możesz stworzyć pole użytkownika. Przykłady: informacyjny — “jak wybrać”, “co to jest”; komercyjny — “cena”, “kupić”, “zamówić”; nawigacyjny — “marka”, “oficjalna strona”.
- Eksportuj wynik do CSV z kolumnami: query, cluster, intent. Zapisz w data/clean/queries_clustered.csv.
Porada: Jeśli nie masz Key Collector, zrób prostą heurystykę w pandas: stwórz listę tokenów dla każdej intencji i klasyfikuj zapytanie według obecności tych słów. Potem ręcznie sprawdź kontrowersyjne przypadki.
✅ Weryfikacja: Każde zapytanie ma klaster i intencję. Większość zapytań komercyjnych została zgrupowana w logiczny sposób, informacyjne oddzielone od transakcyjnych.
Problemy i rozwiązania: jeśli grupy są zbyt ogólne, obniż progi podobieństwa. Jeśli zbyt wąskie, podnieś progi lub łącz ręcznie. W złożonych tematach pomocne jest hybrydowe podejście: automatyczna wstępna klasteryzacja + ręczne poprawki.
Krok 8: Łączenie danych i przygotowanie analiz
Cel etapu
Połączyć wyniki SERP z klasteryzacją, obliczyć użyteczne metryki do porównawczej analizy według regionów i konkurujących domen.
Instrukcja krok po kroku
- Załaduj data/clean/serp_results_clean.csv i data/clean/queries_clustered.csv do pandas (skrypt scripts/analyze_regions.py).
- Wykonaj merge według kolumny query, aby każdy wynik otrzymał klaster i intencję.
- Dodaj obliczenie pozycji domeny: dla każdej kombinacji city + query stwórz ranking. To już jest w pozycji, upewnij się co do poprawności.
- Policz udział domen według klastrów: grupowanie według city, cluster, root_domain, metryka średnia pozycja i udział w top-10.
- Dodaj flagę top-10: position ≤ 10. Oblicz pokrycie domeny w top-10 według klastrów i intencji.
- Zapisz tablice pośrednie w data/clean/analytics_*.csv: na przykład, coverage_by_city_domain.csv, top10_share_by_intent.csv.
Porada: W raporcie wygodnie jest pokazywać „mapy cieplne” pokrycia: miasta w poziomie, domeny w pionie, kolor — udział zapytań w top-10. To ujawnia silnych graczy w regionach.
✅ Weryfikacja: Tabele są tworzone bez błędów, w nich zrozumiałe liczby: lokalni gracze mają wyższy udział top-10 w swoim mieście, federalni — stabilny udział w wielu miastach.
Problemy i rozwiązania: jeśli w danych mało trafień w top-50, sprawdź poprawność parsowania i filtrów. Rozszerz listę zapytań lub zwiększ wynik do 100, jeśli to możliwe i bezpieczne.
Krok 9: Analiza różnic w wynikach według regionów i lokalizacji zapytań
Cel etapu
Określić, które zapytania są zlokalizowane, a które nie, i jak wpływa to na strategię SEO w różnych miastach. Zidentyfikować klastry i domeny z silną lokalnością.
Instrukcja krok po kroku
- Dla każdego zapytania zbierz zbiory domen w top-10 według miast. Policz przecięcie między miastami (np. Warszawa vs Kraków). Metryka: Jaccard = |przecięcie| / |zjednoczenie|.
- Stwórz tabelę przestawną Jaccard dla wszystkich par miast. Niskie wartości wskazują na silną regionalną zależność wyników.
- Określ zlokalizowane zapytania: te, przy których średni Jaccard dla wszystkich par miast jest niższy niż próg (np. 0.3). Dla niezlokalizowanych — próg wyżej (np. 0.6).
- Porównaj intencje: zazwyczaj zapytania komercyjne są częściej zlokalizowane niż informacyjne. Sprawdź to po średnich wartościach Jaccard w każdym intencji.
- Zidentyfikuj „unikalnych” konkurentów w mieście: domeny, które pojawiają się w top-10 tylko w jednym mieście. Przygotuj listę do lokalnych linków i partnerstw.
- Przygotuj raport: 1) Top zlokalizowanych zapytań, 2) Top niezlokalizowanych zapytań, 3) Domeny unikalne dla miasta, 4) Domeny stabilnie silne w kilku miastach.
- Zapisz raport w reports/regional_differences.csv i przygotuj tekstowe podsumowanie z rekomendacjami.
Porada: Dodaj metrykę „stabilność pozycji” dla domeny: średnia i odchylenie standardowe pozycji według miast. To pomoże zrozumieć, gdzie domena jest silniejsza.
✅ Weryfikacja: W raportach widać, że część zapytań znacznie różni się między miastami, a część niemal nie zmienia. Możesz wymienić przynajmniej 5 zlokalizowanych i 5 niezlokalizowanych zapytań z twojego zestawu.
Problemy i rozwiązania: jeśli różnica jest minimalna, być może temat mało zależy od regionu lub próbka jest zbyt wąska. Dodaj zapytania o lokalnej intencji (“blisko”, “dostawa dziś”, “w moim mieście”) i powtórz analizę.
Weryfikacja rezultatu
Lista kontrolna: 1) Masz działające mobilne proxy dla 10+ miast, geo zweryfikowane. 2) Parser zbiera top-50 dla każdego miasta i zapytania, CSV nie są puste. 3) Czyszczenie i normalizacja wykonane, domeny wydobyte. 4) Klasteryzacja według intencji zakończona, każdemu zapytaniu przypisano intencję. 5) Raporty dotyczące różnic między miastami są przygotowane. 6) W raporcie znajdują się listy zlokalizowanych i niezlokalizowanych zapytań. 7) Są rekomendacje dotyczące regionalnego SEO na podstawie danych.
Jak przetestować: 1) Ręcznie porównaj kilka zapytań w przeglądarce przez odpowiednie proxy. 2) Porównaj 5–10 wierszy CSV z rzeczywistymi wynikami. 3) Sprawdź, czy top-10 według miast rzeczywiście różni się tam, gdzie się tego spodziewasz.
Wskaźniki udanego wykonania: pokrycie danych nie mniejsze niż 80% od planowanej liczby kombinacji miasto × zapytanie; minimalna liczba błędów sieciowych; zrozumiałe, powtarzalne raporty.
Typowe błędy i rozwiązania
- Problem: captcha i blokady. Powód: wysoka częstotliwość zapytań, jednorodne nagłówki, brak przerw. Rozwiązanie: zwiększ opóźnienia, zmniejsz równoległość, rotuj IP rzadziej, zmieniaj User-Agent, rozważ oficjalne API.
- Problem: niepoprawna geolokalizacja. Powód: proxy z niestabilnym geo lub cache. Rozwiązanie: sprawdź geo przez Yandex.Internetometr, zmień IP, weź innego operatora lub miasto.
- Problem: śmieci w danych i duplikaty. Powód: nieoczyszczone URL, bloki reklamowe. Rozwiązanie: dodaj filtry według domen, normalizuj URL, przechowuj tylko organiczne.
- Problem: niestabilne selektory HTML. Powód: zmiany w strukturze SERP. Rozwiązanie: użyj bardziej ogólnych wzorców, sprawdzaj parser na 2–3 zapytaniach, aktualizuj selektory.
- Problem: zbyt wąskie klastry. Powód: wysoki próg podobieństwa. Rozwiązanie: obniż próg, połącz bliskie klastry ręcznie, sprawdź tokenizację.
- Problem: słaba różnorodność regionów. Powód: niewłaściwy wybór zapytań. Rozwiązanie: dodaj lokalne intencje i sprawdzaj Jaccard dla par miast.
- Problem: przeciążenie proxy. Powód: zbyt wiele zapytań z rzędu. Rozwiązanie: rozdziel je w czasie, korzystaj z dodatkowych proxy, dodawaj kolejki i przerwy.
Dodatkowe możliwości
Zaawansowane ustawienia: 1) Buferowanie odpowiedzi HTML według klucza (engine, city, query) dla oszczędności zapytań. 2) Przechowywanie danych w SQLite lub PostgreSQL z indeksami według city, query, domain. 3) Rejestrowanie błędów w osobnych plikach w logs z datami. 4) Dodanie headless przeglądarki (na przykład, za pomocą Selenium) tylko dla problematycznych zapytań, gdzie bez JS nie można zebrać snippetu. 5) Używanie oficjalnych API: Google Custom Search API, Yandex.API (jeśli dostępne są odpowiednie końcówki). To zmniejszy ryzyko i poprawi stabilność.
Optymalizacja: 1) Losowy czas oczekiwania i User-Agent. 2) Inteligentne powtarzanie: powtarzaj tylko nieudane zapytania. 3) Wydzielenie „ciężkich” zapytań do osobnej kolejki i obróbka później. 4) Cotygodniowe lub comiesięczne uruchamianie dla monitorowania dynamiki.
Co jeszcze można zrobić: 1) Obliczanie Rank-Biased Overlap między miastami dla dokładniejszej oceny podobieństwa wyników. 2) Automatyczne generowanie rekomendacji: jakie strony warto stworzyć dla konkretnego miasta. 3) Używanie morfologicznego analizatora do polskiego języka dla lepszej klasteryzacji. 4) Przygotowanie dashboardu (na przykład w Power BI) do wizualizacji pokrycia domen i intencji według miast.
Porada: Włącz „czarną listę” domen, które zawsze należy wykluczać z analizy (na przykład, niezwiązane usługi), ale przechowuj kopię surowych danych, aby w razie potrzeby przywrócić.
FAQ
Pytanie 1: Czy można obejść się bez mobilnych proxy? Odpowiedź: Tak, jeśli masz oficjalne API z parametrami regionu lub jeśli korzystasz z miejskich centrów danych. Ale mobilne proxy często lepiej odzwierciedlają rzeczywiste lokalne wyniki.
Pytanie 2: Jak zmniejszyć prawdopodobieństwo captcha? Odpowiedź: Zwiększ czasy oczekiwania, zmniejsz równoległość, zmieniaj User-Agent, używaj rotacji IP niezbyt często, oraz korzystaj z oficjalnych API gdy to możliwe.
Pytanie 3: Jak zrozumieć, że zapytanie jest zlokalizowane? Odpowiedź: Jeśli skład domen w top-10 znacznie zmienia się między miastami (niski Jaccard), a także w wynikach często obecne są lokalne katalogi i mapy, zapytanie jest zlokalizowane.
Pytanie 4: Co robić, jeśli struktury HTML w Google i Yandex zmieniają się? Odpowiedź: Keep your parser modular, add unit tests for 2–3 reference queries. Update only the parsing module when changes occur.
Pytanie 5: Jak poprawnie oznaczać intencje? Odpowiedź: Łącz automatyczne heurystyki (listy słów podpowiedzi) z ręcznym sprawdzeniem kontrowersyjnych przypadków. Intencje precyzuj według danych o konwersjach.
Pytanie 6: Co zrobić, jeśli w mieście jest mało danych? Odpowiedź: Rozszerz listę zapytań, dodaj leksykę LSI i długie ogony, uruchom w innym czasie doby, korzystaj z alternatywnych źródeł semantyki.
Pytanie 7: Jak traktować agregatory i marketplace? Odpowiedź: Nie usuwaj ich całkowicie. Oznaczaj jako osobny typ i analizuj wpływ na swoją niszę. To konkurenci o ruch.
Pytanie 8: Czy można połączyć dane Google i Yandex? Odpowiedź: Tak. W raportach zachowuj oznaczenie engine. Porównuj je osobno i razem, aby zobaczyć cross-searchową odporność domen.
Pytanie 9: Jak często aktualizować dane? Odpowiedź: Co 2–4 tygodnie dla dynamicznych nisz, co 1–2 miesiące dla stabilnych. Przechowuj wersje raportów, aby śledzić trendy.
Pytanie 10: Jakie metryki są najprzydatniejsze? Odpowiedź: Udział w top-10 według domen i klastrów, średnia pozycja, stabilność pozycji, Jaccard między miastami, pokrycie intencji.
Podsumowanie
Podsumowanie wykonanych działań: przygotowałeś proxy według miast, sprawdziłeś geo, skonfigurowałeś środowisko Pythona, zebrałeś top-50 wyników w Google i Yandexie dla wybranych zapytań i regionów, oczyściłeś i znormalizowałeś dane, sklasteryzowałeś semantykę według intencji oraz przeprowadziłeś analizę różnic w wynikach między miastami. W rezultacie masz praktyczny raport, który pokazuje, w jakich zapytaniach konkurenci są silni w każdym regionie i jakie zapytania są zlokalizowane.
Co robić dalej: 1) Twórz i optymalizuj lokalne strony docelowe pod zlokalizowane klastry z komercyjną intencją. 2) Wzmacniaj sygnały E-E-A-T w miastach, gdzie pozycja jest niestabilna. 3) Skonfiguruj regularne zbieranie danych i monitorowanie zmian. 4) Dostosuj treści do informacji poszukiwanych w konkretnych miastach.
Gdzie rozwijać: 1) Integracja z CRM do oceny konwersji według regionów. 2) Dodawanie sygnałów behawioralnych i lokalnych linków. 3) Rozszerzenie liczby miast i tematyki zapytań. 4) Automatyzacja raportowania i wizualizacja w narzędziach BI.
Porada: Dokumentuj każdy etap i przechowuj konfiguracje. Dzięki temu twój proces będzie łatwy do skalowania na nowe miasta i nisze.
Porada: Trzymaj szablon raportu i listę kontrolną uruchamiania. To zaoszczędzi 30–40% czasu podczas kolejnych iteracji.
