วิธีการสร้างสารสนเทศทางการค้นหาผู้แข่งขันตามภูมิภาคผ่านโปรซี่มือถือ: คู่มือแบบทีละขั้นตอน
บทความ
- บทนำ
- การเตรียมความพร้อมเบื้องต้น
- ความเข้าใจพื้นฐาน
- ขั้นตอนที่ 1: ระบุคำค้นเป้าหมายและรายชื่อภูมิภาค
- ขั้นตอนที่ 2: ตั้งค่าโปรซี่มือถือตามเมืองและตรวจสอบภูมิศาสตร์
- ขั้นตอนที่ 3: เตรียมสภาพแวดล้อม python และโครงสร้างโปรเจ็กต์
- ขั้นตอนที่ 4: สร้างรายชื่อผู้แข่งขันโดยตรงตามภูมิภาค
- ขั้นตอนที่ 5: ดึงข้อมูลผลที่ 50 ตามคำค้นและเมือง (google และ yandex)
- ขั้นตอนที่ 6: ทำความสะอาด ปรับแต่ง และดึงโดเมน
- ขั้นตอนที่ 7: การจัดกลุ่มสารสนเทศที่รวบรวมตามเจตนา
- ขั้นตอนที่ 8: รวมข้อมูลและเตรียมการวิเคราะห์
- ขั้นตอนที่ 9: วิเคราะห์ความแตกต่างของผลลัพธ์ตามภูมิภาคและการปรับแต่งคำค้น
- ตรวจสอบผลที่ได้
- ข้อผิดพลาดที่พบบ่อยและการแก้ไข
- โอกาสเพิ่มเติม
- คำถามที่พบบ่อย
บทนำ
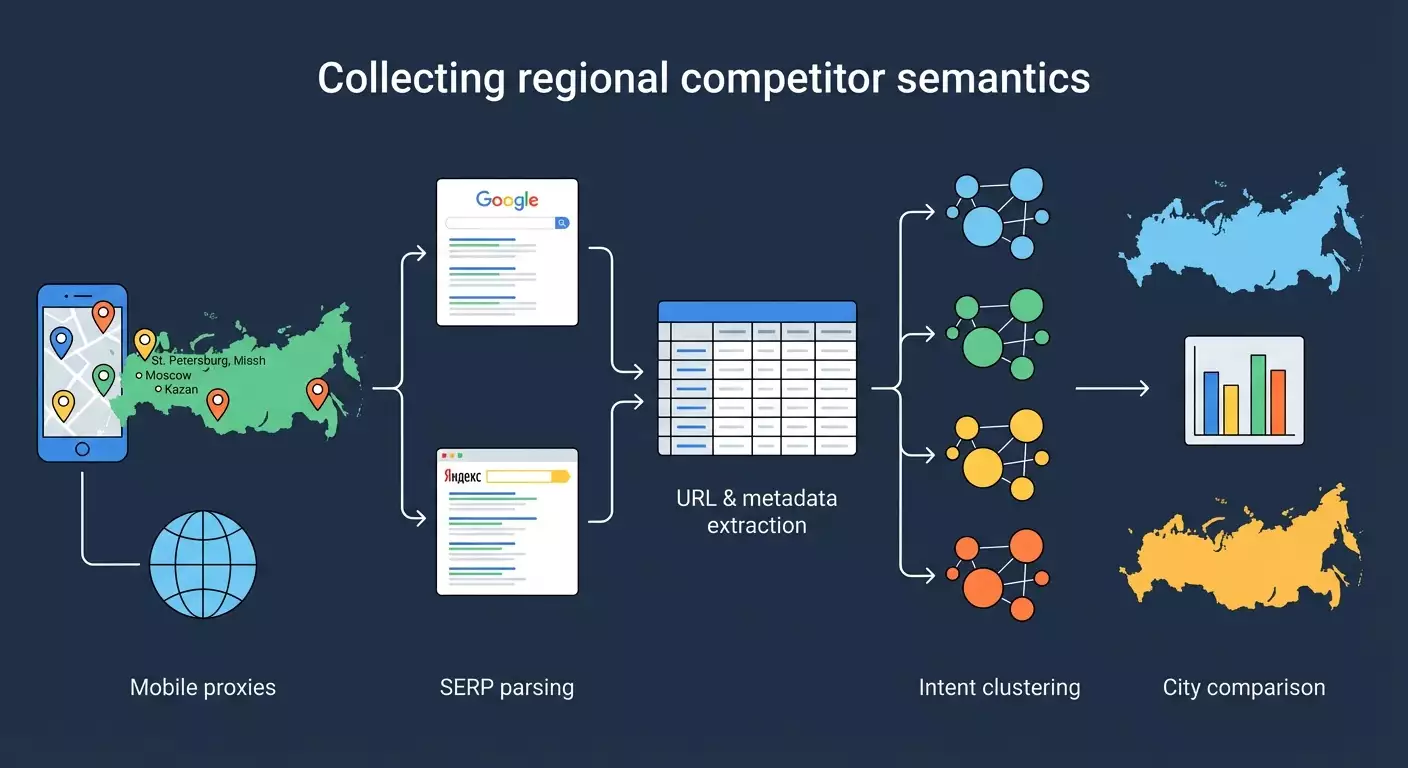
ในคู่มือแบบทีละขั้นตอนนี้ คุณจะได้เรียนรู้วิธีการสร้างสารสนเทศทางการค้นหาผู้แข่งขันในภูมิภาคต่างๆ ของประเทศไทย โดยการใช้โปรซี่มือถือ การดึงข้อมูลจากผลการค้นหา Google และ Yandex รวมถึงเครื่องมือสำหรับการจัดกลุ่มและวิเคราะห์ เราจะผ่านทุกขั้นตอนจากเริ่มต้น: การเตรียมสภาพแวดล้อม การตั้งค่าโปรซี่ตามเมือง การดึงข้อมูล 50 ผลลัพธ์ตามคำค้นเป้าหมาย การดึง URL, title, description, และตำแหน่ง การจัดกลุ่มสารสนเทศที่รวบรวมตามเจตนา (ข้อมูล, การค้า, การเดินทาง) การเปรียบเทียบผลการค้นหาโดยภูมิภาค และการจัดทำรายงานปฏิบัติสำหรับการตัดสินใจ SEO
ผลลัพธ์ที่คุณจะได้คือ: 1) รายชื่อผู้แข่งขันตามแต่ละเมือง 2) ตารางคำสำคัญที่ผู้แข่งขันจัดอันดับในภูมิภาคต่างๆ 3) เมตริกความแตกต่างของผลการค้นหาในภูมิภาคและการปรับแต่งคำค้น 4) กลุ่มเจตนาเพื่อการประหยัดค่าใช้จ่ายและจัดลำดับความสำคัญของเนื้อหา 5) กระบวนการที่สามารถทำซ้ำได้ซึ่งสามารถทำซ้ำได้ทุกเดือน
คู่มือนี้เหมาะสำหรับผู้เชี่ยวชาญด้าน SEO, นักการตลาดออนไลน์, นักวิเคราะห์ และทุกคนที่ต้องการเข้าใจว่าผลการค้นหาในภูมิภาคทำงานอย่างไรและวิธีการรวบรวมข้อมูลที่เป็นประโยชน์เพื่อการตัดสินใจได้เร็วขึ้น ระดับความยากคือสำหรับผู้เริ่มต้นพร้อมกับองค์ประกอบสำหรับผู้ที่มีประสบการณ์ เราจะไม่ต้องการทักษะการเขียนโปรแกรมที่ลึกซึ้ง แต่การทำงานพื้นฐานกับ Python จะมีประโยชน์
ข้อมูลที่จำเป็นต้องทราบล่วงหน้า: ความเข้าใจพื้นฐานเกี่ยวกับ SEO วิธีการสร้างสุนทรียภาพ การแยกแยะระหว่างคำค้นข้อมูลและการค้า และการทำงานกับ CSV/Excel เวลาในการดำเนินการ: เมื่อตั้งคำค้นและรายชื่อเมืองเรียบร้อย — 6–10 ชั่วโมงสำหรับการเรียกใช้ครั้งแรก 1–3 ชั่วโมงสำหรับการดำเนินการซ้ำ
✅ การตรวจสอบ: คุณเข้าใจว่าคุณจะได้รายชื่อผู้แข่งขันที่เฉพาะเจาะจงตามเมือง สารสนเทศทั่วไปและเฉพาะที่ไม่ซ้ำกัน และสามารถอธิบายได้ว่าคำค้นใดถูกปรับแต่งและจะใช้ในการ SEO ภูมิภาคอย่างไร
การเตรียมความพร้อมเบื้องต้น
เครื่องมือที่จำเป็น: 1) บัญชีและการเข้าถึงโปรซี่มือถือที่ mobileproxy.space รวมถึงเมืองต่างๆ ในประเทศไทย (กรุงเทพฯ, เชียงใหม่, ขอนแก่น, ภูเก็ต และอื่นๆ ตามที่คุณต้องการ) 2) Python 3.10+ และตัวจัดการแพ็กเกจ pip 3) ไลบรารี Python: requests, beautifulsoup4, lxml, pandas, urllib3, tldextract (สำหรับการดึงโดเมน) 4) ตัวแก้ไขข้อความ (VS Code หรือทางเลือกอื่น) 5) ตัวแก้ไขตาราง (Excel, Google Sheets หรือ LibreOffice Calc) 6) Key Collector บน Windows สำหรับการจัดกลุ่มและการจัดกลุ่มคำค้น 7) เทอร์มินัลหรือบรรทัดคำสั่ง 8) ตัวเลือก: curl สำหรับการตรวจสอบโปรซี่อย่างรวดเร็ว 9) การเข้าถึงเบราว์เซอร์เพื่อตรวจสอบการตรวจสอบสถานะผ่าน Yandex.Internetometer (เว็บไซต์จาก Yandex สำหรับการตรวจสอบตำแหน่ง IP)
ความต้องการระบบ: Windows 10/11 หรือ macOS 12+ หรือ Linux (Ubuntu 22.04+), RAM ขั้นต่ำ 8 GB, อินเทอร์เน็ตที่มีเสถียรภาพ 10 Mbps+, พื้นที่ว่างบนดิสก์ 2–5 GB สำหรับข้อมูลและบันทึก
สิ่งที่ต้องติดตั้ง: 1) ติดตั้ง Python เวอร์ชั่นล่าสุด 2) ติดตั้ง Key Collector บน Windows 3) สร้างบัญชีที่ mobileproxy.space เติมเงิน และซื้อโปรซี่ตามเมืองที่ต้องการ (1 โปรซี่ต่อเมือง แนะนำ 2–3 โปรซี่เพื่อความเสถียร) 4) ติดตั้งไลบรารี: ในเทอร์มินัลให้รัน: pip install requests beautifulsoup4 lxml pandas urllib3 tldextract 5) ตั้งค่าตัวแก้ไขข้อความและเทอร์มินัลของคุณ
การสร้างสำเนาสำรอง: สร้างโฟลเดอร์โปรเจ็กต์ที่มีโฟลเดอร์ย่อย data/raw, data/clean, reports, config, logs และคัดลอกไฟล์ CSV ไปยังโฟลเดอร์สำรองหรือคลาวด์เป็นระยะๆ
⚠️ คำเตือน: ตรวจสอบให้แน่ใจว่าการกระทำของคุณสอดคล้องกับกฎหมายและนโยบายบริการ บางเครื่องมือค้นหามีกฎในการจำกัดการรวบรวมข้อมูลอัตโนมัติ ใช้ขีดจำกัดคำค้นอย่างมีสติ อ่าน robots.txt และปฏิบัติตามกฎระเบียบและพิจารณา API อย่างเป็นทางการเป็นวิธีที่ดีที่สุด
เคล็ดลับ: สร้างสภาพแวดล้อมเสมือน Python (python -m venv .venv และจากนั้นเปิดใช้งาน) และล็อกพึ่งพาใน requirements.txt เพื่อให้สามารถย้ายโปรเจกต์ได้อย่างง่ายดาย
✅ การตรวจสอบ: คำสั่ง python --version และ pip --version ในเทอร์มินัลทำงานได้ ไม่มีข้อผิดพลาดในการติดตั้งไลบรารี และคุณมีโปรซี่ที่สามารถใช้งานได้อย่างน้อยหนึ่งตัวสำหรับกรุงเทพฯ และสามารถเปิด Yandex.Internetometer ในเบราว์เซอร์ได้
ความเข้าใจพื้นฐาน
คำศัพท์หลักในภาษาที่เข้าใจง่าย: 1) สารสนเทศทางการค้นหา — รายการคำค้นที่คุณต้องการจัดอันดับหรือวิเคราะห์การแข่งขัน 2) ผลการค้นหาภูมิภาค — ผลการค้นหาที่ได้รับการปรับแต่งตามตำแหน่งที่ตั้งของผู้ใช้ (เมือง, ภูมิภาค) 3) โปรซี่มือถือ — โปรซี่เซิร์ฟเวอร์ของผู้ให้บริการมือถือที่ช่วยให้สามารถเลียนแบบการเข้าชมจาก IP ที่อยู่มือถือจริงๆ และสิ่งที่สำคัญกว่าในกรณีของเรา คือการเลือกเมือง 4) การดึงข้อมูล SERP — การดึงข้อมูลจากหน้าแสดงผลการค้นหา (URL, title, snippet, ตำแหน่ง) 5) เจตนา — เป้าหมายที่ผู้ใช้คาดหวัง: ข้อมูล (เรียนรู้), การค้า (ซื้อ/สั่งซื้อ), การเดินทาง (หาสถานที่เฉพาะ) 6) 50 อันดับแรก — 50 ผลการค้นหาที่เป็นธรรมชาติแรกสุดโดยไม่มีโฆษณา
หลักการทำงานสำคัญ: เราจะส่งคำค้นไปยังเครื่องมือค้นหา ระบุโปรซี่เพื่อยืนยันภูมิศาสตร์ รับหน้า HTML ดึงส่วนที่จำเป็นและบันทึกลงในตาราง ทำซ้ำสำหรับแต่ละเมืองและคำค้น จากนั้นจัดกลุ่มและวิเคราะห์
สิ่งสำคัญที่ต้องเข้าใจ: 1) ในเมืองต่างๆ รายการโดเมนและเพจในผลการค้นหาอาจแตกต่างกัน 2) คำค้นที่ปรับแต่งมักจะมีชื่อเมืองหรือมีเจตนาในท้องถิ่น (เช่น บริการส่ง, ใกล้ๆ, ที่อยู่) 3) คำค้นที่ส่งบ่อยเกินไปอาจทำให้เกิด captcha หรือบล็อกได้ 4) การตรวจสอบภูมิศาสตร์อย่างถูกต้องเป็นสิ่งสำคัญ 5) ผลการค้นหาบางส่วนอาจถูกปรับส่วนบุคคล ใช้เซสชั่นที่สะอาด โดยไม่มีการเข้าสู่ระบบ
เคล็ดลับ: เมื่อทำการวิเคราะห์ให้มุ่งเน้นไม่เพียงแค่คำสำคัญ แต่ยังรวมถึงโดเมนของผู้แข่งขันและเนื้อหาประเภทต่างๆ เพื่อเลือกกลยุทธ์ที่ถูกต้อง (หน้าเว็บไซต์ในท้องถิ่น, รายการ, บทความ, หน้าแลนดิ้ง)
ขั้นตอนที่ 1: ระบุคำค้นเป้าหมายและรายชื่อภูมิภาค
เป้าหมายของขั้นตอน
สร้างรายชื่อคำค้นเริ่มต้นและรายชื่อเมืองที่เราจะรวบรวมผลการค้นหา นี่คือพื้นฐานสำหรับการดึงข้อมูลและเปรียบเทียบ
คำแนะนำแบบทีละขั้นตอน
- เปิดตาราง (Excel หรือ Google Sheets) และสร้างชีตชื่อ Seeds
- ในคอลัมน์ A ระบุคำค้นพื้นฐานที่สะท้อนถึงผลิตภัณฑ์หรือกลุ่มเป้าหมายของคุณ เช่น “บริการส่งน้ำ”, “ซ่อมแซมโน้ตบุ๊ค”, “ซื้อเฟอร์นิเจอร์” เป็นต้น
- ในคอลัมน์ B เพิ่มการชี้แจงหรือคำพ้องความหมายถ้าจำเป็น
- สร้างชีต Cities ในคอลัมน์ A ระบุเมือง: กรุงเทพฯ, เชียงใหม่, ขอนแก่น, ภูเก็ต, นครราชสีมา, นนทบุรี, สมุทรปราการ, ชลบุรี, อุบลราชธานี, สงขลา และภูมิภาคอื่นๆ ตามเป้าหมายของคุณ
- ระบุความสำคัญ: เลือก 10–15 เมืองหลักที่มีความต้องการสูงสุด
- รวบรวมรายชื่อคำค้นเป้าหมายโดยรวมคำพื้นฐานและการชี้แจง เช่น “บริการส่งน้ำ”, “บริการส่งน้ำถึงบ้าน”, “บริการส่งน้ำดื่ม”, “ซ่อมแซมโน้ตบุ๊ค”, “ซ่อมแซมโน้ตบุ๊ครวดเร็ว”
- บันทึกตารางในโฟลเดอร์ data/raw ในชื่อ seeds_and_cities.xlsx
สิ่งสำคัญ: อย่าเพิ่งเพิ่มชื่อเมืองในคำค้นเพื่อประเมินการปรับแต่งโดยไม่ให้ภูมิศาสตร์ที่ชัดเจน คุณจะตรวจสอบในภายหลังด้วยการปรับแต่งภูมิศาสตร์
เคล็ดลับ: จำกัดรายชื่อไว้ที่ 50–200 คำค้นสำหรับการเรียกใช้ครั้งแรก เพื่อไม่ให้โปรซี่ทำงานหนักเกินไป และไม่ใช้เวลามากเกินไป
✅ การตรวจสอบ: คุณมีไฟล์เดียวที่มี 50–200 คำค้นและ 10–15 เมือง คำค้นเข้าใจได้และสอดคล้องกับเป้าหมายทางธุรกิจ
ปัญหาและแนวทางแก้ไข: หากคุณกำลังสร้างรายชื่อได้ยาก ให้นำข้อมูลมาจากการเสนอราคาค้นหาในเว็บไซต์ของคุณการสนทนากับลูกค้า รายการบริการและหมวดหมู่สินค้า แล้วขยายคำเสนอไปค้นหาด้วยตนเอง
ขั้นตอนที่ 2: ตั้งค่าโปรซี่มือถือตามเมืองและตรวจสอบภูมิศาสตร์
เป้าหมายของขั้นตอน
เชื่อมต่อโปรซี่มือถือจาก mobileproxy.space สำหรับแต่ละเมือง เพื่อตรวจสอบว่า IP ตรงกับเมืองที่ต้องการจริงหรือไม่โดยใช้ Yandex.Internetometer
คำแนะนำแบบทีละขั้นตอน
- เข้าสู่บัญชีผู้ใช้ของคุณที่ mobileproxy.space เลือกแผนที่มีตัวเลือกสำหรับการเลือกเมืองและผู้ให้บริการ เลือกโปรซี่อย่างน้อยหนึ่งตัวสำหรับแต่ละเมืองในรายชื่อของคุณ แนะนำ 2–3 โปรซี่ต่อเมือง
- บันทึกรายละเอียดโปรซี่แต่ละตัว: โฮสต์, พอร์ต, ชื่อผู้ใช้ และรหัสผ่าน เช่น proxy.example.host:12345, user:pass
- ถ้ามีการสนับสนุนการเปลี่ยน IP ผ่านลิงค์หรือ API เก็บลิงค์ไว้สำหรับการเปลี่ยน IP ซึ่งจะมีประโยชน์สำหรับการรีเซ็ตเซสชั่นเมื่อมี captcha
- สร้างไฟล์ config/proxies.csv โดยมีคอลัมน์ city, host, port, user, password, rotation_url (ถ้ามี) และกรอกข้อมูลให้ครบ
- เปิดเบราว์เซอร์ เปิดโปรซี่ระบบหรือโปรซี่เบราว์เซอร์สำหรับกรุงเทพฯ และไปที่บริการตรวจสอบ IP และตำแหน่งจาก Yandex (Yandex.Internetometer) เพื่อยืนยันว่าเมืองที่แสดงคือกรุงเทพฯ
- ทำการตรวจสอบสำหรับเชียงใหม่ ขอนแก่น และเมืองอื่น ๆ โดยการเปลี่ยนการตั้งค่าโปรซี่
- ลบโปรซี่ในเบราว์เซอร์ ในอนาคตเราจะทำการตรวจสอบภูมิศาสตร์โดยโปรแกรม
⚠️ คำเตือน: ใช้โปรซี่ตามข้อกำหนดของบริการและกฎหมายเท่านั้น เป้าหมายการใช้โปรซี่คือเพื่อยืนยันภูมิศาสตร์อย่างถูกต้องและกระจายภาระงานอย่างเท่าเทียม ไม่ใช่หลีกเลี่ยงข้อจำกัด
เคล็ดลับ: สร้างเวลาหยุดที่ไม่ซับซ้อน: หลังจากเปลี่ยนโปรซี่ให้รอ 10–20 วินาทีก่อนที่จะตรวจสอบภูมิศาสตร์ เพื่อลดโอกาสเกิด “แคช” หรือความล่าช้าในเครือข่าย
✅ การตรวจสอบ: สำหรับแต่ละเมืองคุณสามารถเปิดโปรซี่ที่เหมาะสมและเห็นเมืองที่ถูกต้องใน Yandex.Internetometer
ปัญหาและแนวทางแก้ไข: หากเมืองแสดงผลไม่ถูกต้องให้เปลี่ยน IP ผ่านการหมุนเวียน หรือเลือกผู้ให้บริการอื่นในเมืองเดียวกัน หรือสอบถามฝ่ายสนับสนุน หากเบราว์เซอร์ไม่สนใจโปรซี่ให้ตรวจสอบการตั้งค่าและการเข้าถึง
ขั้นตอนที่ 3: เตรียมสภาพแวดล้อม Python และโครงสร้างโปรเจ็กต์
เป้าหมายของขั้นตอน
สร้างสภาพแวดล้อมที่เสถียรสำหรับการดึงข้อมูลและการวิเคราะห์: โครงสร้างของไดเรกทอรี, เพิ่งพิง, ทดสอบการเชื่อมต่อผ่านโปรซี่
คำแนะนำแบบทีละขั้นตอน
- สร้างโฟลเดอร์โปรเจ็กต์ เช่น regional-serp-competitors
- ภายในสร้างโฟลเดอร์ย่อย: config, data/raw, data/clean, logs, reports, scripts
- สร้างสภาพแวดล้อมเสมือน: ในเทอร์มินัลให้รัน “python -m venv .venv” และเปิดใช้งาน (Windows: “.venv\Scripts\activate”, macOS/Linux: “source .venv/bin/activate”)
- ติดตั้งสารพัด: “pip install requests beautifulsoup4 lxml pandas urllib3 tldextract”
- สร้างไฟล์ config/settings.yaml และกรอกข้อมูลพารามิเตอร์หลัก: เวลาอออก, การหน่วง (เช่น delay_min: 3, delay_max: 8), จำนวนครั้งสูงสุดในการทำซ้ำ (retries: 3), user-agent
- สร้างสคริปต์ scripts/test_proxy_geo.py ที่จะโหลดหน้า Yandex.Internetometer ผ่านโปรซี่และพิมพ์เมืองที่ระบุใน HTML
- ในสคริปต์ให้ตั้งค่าโปรซี่เป็นดิกชันนารีในรูปแบบ: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"} และทำการร้องขอ requests.get ต่อหน้าเพื่อตรวจสอบ IP และหาค่าที่อยู่เมือง (ตามเนื้อหาที่แสดงคำว่า “เมือง” หรือองค์ประกอบที่คล้าย)
- รันสคริปต์ในหลายเมืองและตรวจสอบให้แน่ใจว่าผลลัพธ์ตรงกับที่คาดไว้
เคล็ดลับ: กำหนด User-Agent ที่เป็นเอกลักษณ์ เช่น “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0 Safari/537.36” และเปลี่ยนเมื่อจำเป็นช่วง 20–50 คำค้น
✅ การตรวจสอบ: สคริปต์ test_proxy_geo.py แสดงผลเมืองที่แตกต่างกันเมื่อเปลี่ยนโปรซี่ในโปรแกรมประมวลผล ไม่มีการหยุดเวลาหรือข้อผิดพลาดการเข้าถึง
ปัญหาและแนวทางแก้ไข: หาก requests แจ้งว่า 407 Proxy Authentication Required ให้ตรวจสอบชื่อผู้ใช้และรหัสผ่าน ให้ลองใช้การเข้ารหัสตัวอักษร หากได้รับ captcha ให้เพิ่มระยะเวลาหยุดและลดการหมุนเวียน IP ให้น้อยลงและช้าลง
ขั้นตอนที่ 4: สร้างรายชื่อผู้แข่งขันโดยตรงตามภูมิภาค
เป้าหมายของขั้นตอน
ระบุโดเมนของผู้แข่งขันในแต่ละเมืองเพื่อติดตามการจัดอันดับและรวบรวมข้อมูลสารสนเทศ
คำแนะนำแบบทีละขั้นตอน
- เลือก 5–10 คำค้นหลักจากรายชื่อของคุณที่สะท้อนถึงบริการหรือสินค้าที่ไม่มีการปรับแต่งภูมิศาสตร์
- สร้างสคริปต์ scripts/collect_competitors.py สำหรับแต่ละเมืองให้เลือกโปรซี่ที่เกี่ยวข้อง โดยส่งคำค้นแต่ละคำไปยัง Yandex และ Google ตามลำดับ
- สำหรับ Yandex ใช้พารามิเตอร์คำค้นที่เกี่ยวข้องกับภาษาและภูมิภาค เช่น เพิ่ม lr (รหัสภูมิภาค) ถ้าคุณทราบ หากไม่ทราบ ให้พึ่งพาโปรซี่ในการตรวจสอบภูมิศาสตร์
- สำหรับ Google กำหนดพารามิเตอร์ hl=th, gl=th ประเทศไทยจะถูกตั้งค่าตาม IP; เพิ่มเติมคุณสามารถทดสอบพารามิเตอร์การค้นหาที่ปลอดภัยได้
- ดึงข้อมูล 20–30 ผลลัพธ์ตามธรรมชาติแรกสุด ข้ามบล็อกโฆษณา บริการ และฟังก์ชันต่างๆ หากไม่ตรงตามวัตถุประสงค์
- ทำการบันทึกโดเมนด้วย tldextract เพื่อบันทึกการแก้ไขครั้งแรกสำหรับแต่ละเมืองที่มีจํานวนครั้งปรากฏในผลการค้นหา: โดเมน, จำนวนครั้งที่ปรากฏในรายการของที่สูงสุด, และคำค้นที่จัดอันดับ
- สร้างตาราง data/raw/competitors_by_city.csv ด้วยคอลัมน์ city, domain, engine, frequency, queries
สิ่งสำคัญ: บริการเฉพาะบุคคล (แผนที่, ตลาด) อาจมีความโดดเด่น ควบคุมให้มีค่าใช้จ่ายจริง หากคุณทำธุรกิจ B2B ควรฟิลเตอร์บริการข่าวซึ่งเป็นการรวมเว็บไซต์ที่ไม่ควรพิจารณา
เคล็ดลับ: ทำการตรวจสอบด้วยตนเองในเบราว์เซอร์เฉพาะสำหรับ 1–2 คำค้นในแต่ละเมืองภายใต้โปรซี่ที่เหมาะและเปรียบเทียบโดเมนกับผลจากสคริปต์ เพิ่มความมั่นใจในการดึงข้อมูล
✅ การตรวจสอบ: สำหรับแต่ละเมืองจะมีรายชื่อ 10–30 โดเมนพร้อมค่าความถี่ที่ชัดเจน สายจะมีตราประทับทุกเมืองในเมืองและผู้แข่งขันจากด้านอื่นๆ
ปัญหาและแนวทางแก้ไข: หากการเปรียบเทียบไม่ตรงกันกับการตรวจสอบเองอาจมาจากการเคลื่อนไหวในพื้นที่ ผลการค้นหาส่วนตัวหรือการกรองที่ไม่ถูกต้องออกจากบล็อกรีวิวซึ่งเป็นเรื่องที่สำคัญ ความถี่ของความยืดหยุ่น ควรตรวจสอบด้วยการทำตามล่าช้าหรือเชื่อมโยง
ขั้นตอนที่ 5: ดึงข้อมูลผลที่ 50 ตามคำค้นและเมือง (Google และ Yandex)
เป้าหมายของขั้นตอน
สร้างตารางข้อมูลรายละเอียด: URL, title, description, ตำแหน่ง, เครื่องมือค้นหา, เมือง, คำค้น
คำแนะนำแบบทีละขั้นตอน
- สร้างสคริปต์ scripts/serp_scraper.py โครงสร้าง: ฟังก์ชันสำหรับการค้นหาใน Yandex และ Google ฟังก์ชันสำหรับการดึงข้อมูล HTML การบันทึกข้อมูลลงใน CSV
- ตั้งค่าคอนฟิกสำหรับพารามิเตอร์: จำนวนผลลัพธ์ per_city_per_query_limit: 50, ระยะเวลา delay_min, delay_max, จำนวนครั้งสูงสุดในการทำซ้ำ retries: 3 และรายการ User-Agent
- สร้าง URL การคัดลอกข้อมูล เช่น Google: “https://www.google.com/search?q=คำค้น&num=50&hl=th&gl=th&pws=0” ตัวอย่าง Yandex: “https://yandex.ru/search/?text=คำค้น&lr=รหัสภูมิภาค&numdoc=50” หากไม่ทราบ lr ให้พึ่งพา IP-geolocation
- ตั้งค่าโปรซี่ตามเมือง โปรซี่ - ดิกชันนารี: {"http": "http://user:pass@host:port", "https": "http://user:pass@host:port"}
- ร้องขอหน้าเว็บจับตาดูการให้เวลาระยะเวลาระหว่าง 20–30 วินาที ตรวจสอบข้อผิดพลาด: เวลาหยุด 429, 5xx ให้นำเข้าระยะเวลาหยุด 30–60 วินาทีระหว่างการทำงานกับไฟล์โปรซี่
- การดึงข้อมูล Google: หาอุปกรณ์ที่ดีในบล็อก: บล็อกที่มีแท็ก h3 สำหรับชื่อและลิงค์ซึ่งมีเนื้อหาตรงกับ div/span เลือกเป็นค่าใช้จ่ายหรือไม่ YouTube ว่าเหมาะสมเพียงพอหรือไม่ หากโครงสร้างแตกต่างกันให้ใช้ “a” ที่มีชื่อที่เห็นในบล็อกผลลัพธ์แล้วตั้งข้อกำหนดถึงโดเมน
- การดึงข้อมูล Yandex: ค้นหาการคัดลอกการจัดระเบียบในผลลัพธ์ โดยการดึง “a” เพื่อเข้าถึงข้อมูลและให้ข้อมูลเล็กน้อยที่ไม่ให้ข้อมูลที่โดดเด่นในระดับที่สามารถให้การส่งออกข้อมูล
- บันทึกข้อมูลทั้งหมดลงในคอลัมน์: engine, city, query, position, url, title, snippet, fetched_at (วันที่/เวลา), proxy_id
- เรียกใช้การรวบรวมข้อมูลตามเมืองในลำดับที่ ต้องวนเวียนตามคำค้นสำหรับเมืองแต่ละเมือง เมื่อมีการตั้งคำค้นควรแหน่ง 3–8 วินาที เวลาพัก 10–20 วินาทีในระหว่างเมือง
- บันทึกข้อมูลใน data/raw/serp_results.csv เป็นสำเนาทุกชั่วโมงในรูปแบบที่มีการป้องกันและวัน
⚠️ คำเตือน: รวมไปถึงเครื่องมือค้นหาข้อมูลอัตโนมัติที่ไม่อนุญาตให้ทำการดึงข้อมูลโดยอัตโนมัติมากเกินไป ควรคิดถึง API ที่เป็นทางการ (เช่น Google Custom Search API) หรือบริการเฉพาะ ทำการ 분석เพียงเล็กน้อย โดยไม่ได้ใช้คำมากเกินไปและเพียงแค่สำหรับการวิเคราะห์ก็พอ จะต้องปฏิบัติตามขอบเขตที่ได้ตั้งไว้
เคล็ดลับ: ให้จัดการข้อมูลในตอนเช้าหรือเย็นเพื่อหลีกเลี่ยงการโหลดในขั้นตอนที่สูงขึ้น เพื่อหลีกเลี่ยงปัญหาในการใช้งาน
✅ การตรวจสอบ: ใน CSV สุดท้ายคุณจะต้องมีข้อมูลจากเมืองและคำค้นอย่างน้อย 50 รายการ ผลจะถูกกรองและอยู่ในหลากหลายรูปแบบที่เหมาะสม
ปัญหาและแนวทางแก้ไข: หากเกิดปัญหากับ captcha ให้เพิ่มการใช้บริการที่ชัดเจนให้มากขึ้น ตรวจสอบให้แน่ใจว่าไม่ใช้งานในเวลาเดียวกันโดยใช้เฉพาะคำไม่เกิน 2–5 นาที หากโครงสร้าง HTML มีการปรับเปลี่ยนให้ปรับปรุงและเร็วกว่าด้วยตนเองที่จะตรวจสอบ 2–3 คำค้น
ขั้นตอนที่ 6: ทำความสะอาด ปรับแต่ง และดึงโดเมน
เป้าหมายของขั้นตอน
เตรียมข้อมูลสำหรับการวิเคราะห์: ลบข้อมูลที่ไม่จำเป็น ปรับ URL ให้เป็นแบบสะอาด ดึงโดเมนและลบที่ไม่เกี่ยวข้องออก
คำแนะนำแบบทีละขั้นตอน
- โหลด CSV ใน pandas (สคริปต์ scripts/clean_results.py) แล้วตรวจสอบว่ามี title/snippet ว่างหรือไม่ และกู้หน้าที่เหมาะสมจาก HTML
- แบ่งแยกข้อมูลแถวซ้ำจาก (engine, city, query, url) โดยเก็บแถวแรกไว้
- ยกเว้นลิงก์ภายในของเครื่องมือค้นหา การลิงก์การเข้าสู่เว็บไซต์พาณิชย์ ลิงก์ไปยังข้อมูลหรือข่าวสาร หากไม่มีความจำเป็นต้องมี เพิ่มธงให้กับ type=organic สำหรับผลการค้นหาที่เพิ่มขึ้น
- ปรับ URL: ลบ anchor, ตั้งให้เป็น https, ลบพารามิเตอร์ติดตาม (utm_*, gclid เป็นต้น) บันทึก URL ที่ปรับแต่งในคอลัมน์ clean_url
- ใช้ tldextract เพื่อเข้าถึงโดเมนระดับสองและเขตจัดเก็บที่มีค่า ตัวอย่างเช่น "site.ru”
- บันทึกไฟล์ที่ปรับแต่งไว้ใน data/clean/serp_results_clean.csv
เคล็ดลับ: ให้เพิ่มคอลัมน์ is_local_feature สำหรับข้อมูลประเภทแผนที่/ผู้อธิบาย/ตลาด เพื่อให้คุณแยกมันออกจากหน้าเพจทั่วไปได้อย่างรวดเร็วในการวิเคราะห์
✅ การตรวจสอบ: จำนวนแถวลดลงจากการลบบันทึกอันซ้ำกันและข้อมูลที่ไม่จำเป็น โดเมนถูกดึงออกมาอย่างถูกต้อง ไม่มีลิงก์ที่ไม่ประโยชน์ คุณสามารถนับจำนวน unik root_domain ตามเมืองและคำค้นได้
ปัญหาและแนวทางแก้ไข: หากจำนวนการระบุข้อมูลมากเกินไปตรวจสอบตัวกรองของคุณให้รับอีกสักหน่อย และระบุการตั้งค่าของคุณให้โปร่งใสมากขึ้น บางครั้งการให้แสดงออกเกี่ยวกับความเห็นในการระบุจะมีประโยชน์ให้เป็นภาพรวม
ขั้นตอนที่ 7: การจัดกลุ่มสารสนเทศที่รวบรวมตามเจตนา
เป้าหมายของขั้นตอน
แบ่งกลุ่มความหมายทางคำพ้องให้จัดเป็นกลุ่มตามเจตนาและกลุ่มหัวข้อเพื่อให้เข้าใจว่าเนื้อหาและเว็บไซต์ประจำการไหนที่จะต้องปรับแต่งในท้องถิ่น
คำแนะนำแบบทีละขั้นตอน
- รวบรวมรายชื่อคำค้นที่ไม่ซ้ำกันจากข้อมูลการดึงข้อมูล: ใช้คอลัมน์ query และลบแถวซ้ำ นำไปสงวนไว้ใน data/clean/unique_queries.csv
- เปิด Key Collector บน Windows และสร้างโปรเจ็คใหม่: ไฟล์ → โปรเจ็คใหม่ ระบุชื่อโปรเจ็ค เช่น “Regional SERP Competitors”
- นำเข้ารายการคำค้น: เมนูนำเข้า → จากไฟล์ → เลือก unique_queries.csv และตรวจสอบการเข้ารหัสเป็น UTF-8
- สร้างกลุ่มตามหัวข้อ ใน Key Collector ใช้เครื่องมือการจัดกลุ่มตามลักษณะหรือคำที่เหมือนกัน เริ่มจากระดับความคล้ายคลึงที่พอประมาณ (เช่น 3 คำทั่วไป) จากนั้นปรับกลุ่มด้วยตนเอง
- ใส่รหัสตัดชิ้นแต่ละกลุ่มตามเจตนา: ข้อมูล การค้า หรือการเดินทาง สำหรับการเพิ่มเติมสามารถสร้างฟิลด์ที่เอาไว้สำหรับผู้ใช้ มีตัวอย่าง: ข้อมูล — “อย่างไรจะแยกการเลือก”, “สิ่งที่ทำ”; การค้า — “ราคา”, “ซื้อ”, “สั่ง”; การเดินทาง — “แบรนด์”, “เว็บไซต์ทางการ”
- ส่งออกรายงานเป็น CSV ที่มีคอลัมน์: query, cluster, intent และบันทึกใน data/clean/queries_clustered.csv
เคล็ดลับ: หากคุณไม่มี Key Collector ทำการทำการวิเคราะห์ใน pandas: สร้างรายการคำหลักสำหรับแต่ละเจตนาและจัดประเภทคำค้นขึ้นอยู่กับว่าตรงตามที่มีคำหรือไม่ จากนั้นตรวจสอบด้วยตนเอง
✅ ตรวจสอบ: แต่ละคำค้นมีคลัสเตอร์และเจตนา ส่วนใหญ่คำค้าที่เกี่ยวกับการค้าจะจัดกลุ่มลงตัว และข้อมูลจะแยกจากคำที่มีการซื้อขาย
ปัญหาและแนวทางแก้ไข: หากกลุ่มมีความกว้างเกินไปให้ลดขอบเขตของได้ หรือหากแคบเกินไปให้ปรับค่าหรือรวมกลุ่มด้วยตนเอง ในเรื่องที่ซับซ้อนควรวางแนวทางแบบผสม: การจัดกลุ่มอัตโนมัติขั้นแรก + การปรับใช้งานด้วยตนเอง
ขั้นตอนที่ 8: รวมข้อมูลและเตรียมการวิเคราะห์
เป้าหมายของขั้นตอน
เชื่อมโยงผล SERP กับการจัดกลุ่ม เพื่อนับค่ามิติที่มีประโยชน์สำหรับการเปรียบเทียบทางภูมิศาสตร์และโดเมนที่แข่งขันกัน
คำแนะนำแบบทีละขั้นตอน
- โหลด data/clean/serp_results_clean.csv และ data/clean/queries_clustered.csv เข้าสู่ pandas (สคริปต์ scripts/analyze_regions.py)
- ทำการ merge ตามคอลัมน์ query เพื่อให้แต่ละผลได้ cluster และ intent
- เพิ่มการคำนวณเพื่อดูตำแหน่งโดเมน: สำหรับการเปรียบเทียบ city + query ให้สร้างรูปแบบการจัดอันดับ มันจะอยู่ใน position ตรวจสอบความถูกต้อง
- คำนวณสัดส่วนของโดเมนในกลุ่มต่างๆ: ตั้งกลุ่มตาม city, cluster, root_domain, เมตริกเฉลี่ยตำแหน่งและสัดส่วนในท็อป 10
- เพิ่มธง top-10: ตำแหน่ง ≤ 10 คำนวณความครอบคลุมของโดเมนใน top-10 ตามกลุ่มและตามเจตนา
- บันทึกตารางกลางใน data/clean/analytics_*.csv: ตัวอย่าง coverage_by_city_domain.csv, top10_share_by_intent.csv
เคล็ดลับ: ในรายงานแสดง “แผนที่ความร้อน” การครอบคลุม: เมืองจะอยู่แนวนอน และโดเมนจะอยู่ในแนวดิ่ง สีจะระบุสัดส่วนคำค้นใน top-10 จะช่วยระบุตัวผู้เล่นที่แข็งแกร่งในภูมิภาค
✅ การตรวจสอบ: ตารางจะถูกสร้างโดยไม่มีข้อผิดพลาด และตัวเลขที่เข้าใจได้: ผู้เล่นท้องถิ่นจะมีสัดส่วนในการจัดอันดับที่สูงขึ้นในเมืองของตัวเอง ขณะที่ผู้เล่นระดับชาติจะมีส่วนแบ่งที่สอดคล้องในหลายเมือง
ปัญหาและแนวทางแก้ไข: หากมีข้อมูลน้อยเกินไปใน top-50 ตรวจสอบการดึงข้อมูลและการกรองของคุณ ปรับเพิ่มคำค้นหรือเพิ่มผลลัพธ์สูงสุดเป็น100 หากทำได้และปลอดภัย
ขั้นตอนที่ 9: วิเคราะห์ความแตกต่างของผลลัพธ์ตามภูมิภาคและการปรับแต่งคำค้น
เป้าหมายของขั้นตอน
ระบุว่าคำค้นไหนปรับแต่งบ้าง อันไหนไม่และมีผลอย่างไรต่อกลยุทธ์ SEO ในเมืองต่าง ๆ ระบุกลุ่มและโดเมนที่มีลักษณะเป็นท้องถิ่น
คำแนะนำแบบทีละขั้นตอน
- สำหรับแต่ละคำค้นรวบรวมโดเมนชุดใน top-10 ของเมือง ด้วยการนับรายการที่ตัดกันระหว่างเมือง (เช่น กรุงเทพฯ vs เชียงใหม่) เมตริก: Jaccard = |intersect| / |union|.
- สร้าง pivot table Jaccard สำหรับทุกคู่เมือง ค่าต่ำหมายถึงผลการค้นหาขึ้นอยู่กับภูมิศาสตร์มาก
- ระบุกคำค้นที่ปรับแต่ง: คำค้นที่มีค่าเฉลี่ย Jaccard ต่ำกว่าขอบเขต (เช่น 0.3) สำหรับคำที่ไม่ได้ปรับแต่ง—ขอบเขตสูงกว่า (เช่น 0.6)
- เปรียบเทียบเจตนา: คำค้นทางการค้ามักจะมีการปรับแต่งบ่อยกว่าคำค้นข้อมูล ตรวจสอบค่าเฉลี่ย Jaccard ภายในแต่ละเจตนา
- ระบุผู้แข่งขัน “เฉพาะบุคคล” ในแต่ละเมือง: โดเมนที่ปรากฏใน top-10 เฉพาะในเมืองหนึ่ง เตรียมรายชื่อสำหรับการเชื่อมโยงท้องถิ่นและความร่วมมือ
- สร้างรายงาน: 1) คำค้นที่ปรับแต่งอันดับสูง 2) คำค้นที่ไม่ได้ปรับแต่งอันดับสูง 3) โดเมนเฉพาะสำหรับเมือง 4) โดเมนที่มีความแข็งแกร่งในหลายเมือง
- บันทกรายงานใน reports/regional_differences.csv และทำสรุปข้อความพร้อมคำแนะนำ
เคล็ดลับ: เพิ่มเมตริก “ความเสถียรของตำแหน่ง” สำหรับโดเมน: ค่าและค่าเบี่ยงเบนมาตรฐานของตำแหน่งในเมืองต่างๆ สิ่งนี้จะช่วยให้เข้าใจว่าโดเมนแข็งแกร่งแค่ไหน
✅ การตรวจสอบ: ในรายงานปรากฏให้เห็นว่าบางคำค้นมีความแตกต่างกันชัดเจนในแต่ละเมือง ขณะที่บางคำค้นแทบไม่มีการเปลี่ยนแปลง คุณสามารถระบุได้ว่า 5 คำค้นที่ปรับแต่งและ 5 คำค้นที่ไม่ได้ปรับแต่งจากกลุ่มงานของคุณ
ปัญหาและแนวทางแก้ไข: หากความแตกต่างน้อยเกินไปอาจเกิดจากแนวเกมที่น้อยจากภูมิภาคหรือการเลือกการค้นหารายการที่มีแนวโน้มที่ต่ำ ให้เพิ่มคำค้นที่มีเจตนาทางภูมิศาสตร์ (“ใกล้ๆ”, “วันส่งสินค้า”, “ในเมืองของฉัน”) และทำการวิเคราะห์ซ้ำ
ตรวจสอบผลที่ได้
รายการตรวจสอบ: 1) คุณมีโปรซี่มือถือที่สามารถทำงานได้สำหรับ 10+ เมือง ตรวจสอบภูมิศาสตร์เรียบร้อยแล้ว 2) โปรแกรมรวบรวมข้อมูลจะดึงข้อมูล top-50 สำหรับแต่ละเมืองและคำค้น CSV จะไม่ว่างเปล่า 3) การทำความสะอาดและปรับแต่งเสร็จสมบูรณ์ โดเมนถูกดึงออก 4) การจัดกลุ่มตามเจตนาเสร็จสมบูรณ์ คำค้นแต่ละคำมีการกำหนดเจตนา 5) รายงานเกี่ยวกับความแตกต่างระหว่างเมืองได้ถูกสร้างขึ้น 6) ในรายงานมีรายการคำค้นที่ปรับแต่งและไม่ได้ปรับแต่ง 7) มีคำแนะนำเกี่ยวกับ SEO ภูมิภาคตามข้อมูลที่ได้
วิธีทดสอบ: 1) เปรียบเทียบคำค้นจำนวนหนึ่งด้วยตนเองในเบราว์เซอร์ผ่านโปรซี่ที่กำหนด 2) ตรวจสอบ 5–10 แถวของ CSV กับผลจริง 3) ตรวจสอบว่า top-10 ในแต่ละเมืองมีความแตกต่างตามที่คาดไว้
ตัวชี้วัดความสำเร็จของการดำเนินการ: ครอบคลุมข้อมูลไม่ต่ำกว่า 80% ของการรวมกันที่ตั้งเป้าหมาย × คำค้น; จำนวนข้อผิดพลาดในเครือข่ายต่ำที่สุด; รายงานที่เข้าใจได้ และสามารถทำซ้ำได้
ข้อผิดพลาดที่พบบ่อยและการแก้ไข
- ปัญหา: captcha และการบล็อกเหตุผล: การจับคู่คำค้นที่สูงเกินไป หัวข้อเดียวกัน ขาดการหยุดพัก แก้ปัญหา: เพิ่มระยะเวลาหยุด ลดจำนวนการใช้งานร่วมกันและหมุนเวียน IP ให้น้อย อาจต้องพิจารณา API ที่เป็นทางการ
- ปัญหา: เจอการระบุตำแหน่งภูมิศาสตร์ไม่ถูกต้องสาเหตุ: โปรซี่ที่มีการระบุตำแหน่งอยู่ไม่เสถียรหรือแคช แก้ไข: ตรวจสอบภูมิศาสตร์ผ่าน Yandex.Internetometer เปลี่ยน IP หรือเลือกผู้ให้บริการหรือเมืองใหม่
- ปัญหา: ข้อมูลที่ไม่เหมาะสมและซ้ำซ้อนเหตุผล: URL ที่ไม่ถูกต้อง ป้ายโฆษณา แก้ปัญหา: เพิ่มตัวกรองตามโดเมน ปรับปรุง URL ไว้ให้เคลียร์ กล่าวเท่านั้นที่รวมผลการวิจัยมีประสิทธิภาพ
- ปัญหา: ป้าย HTML ไม่เสถียร สาเหตุ: การปรับเปลี่ยนโครงสร้าง SERP แก้ไข: ใช้รูปแบบที่เป็นกลางมากยิ่งขึ้น ตรวจสอบโปรเซสซิ่งตรงตามคำค้น 2-3 ประเภท อัปเดตการเลือกที่มีการปรับปรุง
- ปัญหา: กลุ่มแคบเกินไป เหตุผล: ขอบเขตความคล้ายคลึงกันสูงเกินไป แก้ไข: ลดขอบเขตรวมกลุ่ม่อยไปกันเอง ถ้าเป็นไปได้ให้ทดสอบการใส่ข้อมูลกับการระบุที่ใช้
- ปัญหา: ความแตกต่างของภูมิภาคต่ำ เหตุผล: การเลือกคำค้นไม่ถูกต้อง แก้ไข: เพิ่มคำค้นที่มีเจตนาและลองตรวจสอบ Jaccard ตามคู่เมือง
- ปัญหา: บล็อกโปรซี่เป็นจำนวนมากเหตุผล: คำค้นที่มากเหลือเกินในเวลาเดียวกัน แก้ปัญหา: กระจายระหว่างเวลา ใช้โปรซี่เพิ่มเติม และหยุดพักให้เพียงพอ
โอกาสเพิ่มเติม
การตั้งค่าอันทันสมัย: 1) การเก็บข้อมูล HTML เป็นคีย์ (engine, city, query) เพื่อประหยัดว่า 2) การจัดเก็บข้อมูลใน SQLite หรือ PostgreSQL โดยมีดัชนีอยู่ที่ city, query, domain 3) การตรวจสอบข้อผิดพลาดในไฟล์แยกต่างหากที่บันทึกที่ logs เวลา 4) การใช้งานเบราว์เซอร์ headless (เช่น ด้วยการใช้ Selenium) เฉพาะคำค้นที่ต้องการซึ่งต้องการ JS ไม่ให้มีตัวประมวลผล 5) การใช้ API อย่างเป็นทางการ: Google Custom Search API, Yandex.API (ถ้ามีเอนด์พอยต์ที่จำเป็น) ซึ่งจะช่วยลดความเสี่ยงและเพิ่มความมั่นคง
การปรับปรุง: 1) การล็อกระยะเวลาและ User-Agent อย่างเป็นเอกสาร 2) การหมุนเวียนที่ชาญฉลาด: หมุนการทำซ้ำเพียงคำค้นที่อาจจะไม่มีประสิทธิภาพ 3) การแยกคำที่ใช้สำหรับการดึงข้อมูลที่ซับซ้อนในขั้นตอนการดำเนินการช่วงหลัง 4) ทำการตรวจสอบเป็นระยะเพื่อประเมินแนวโน้ม
สิ่งที่เพิ่มเติม: 1) การตรวจสอบความคล้ายคลึงกันระหว่างเมืองด้วย Rank-Biased Overlap สำหรับการประเมินที่เจาะจงขึ้น 2) การสร้างคำแนะนำอัตโนมัติ ว่าต้องทำหน้าไหนเพื่อช่วยให้เหมาะสมในเมืองเฉพาะ 3) การใช้เครื่องวิเคราะห์ทางมอลฟอลิกเพื่อช่วยในการจัดกลุ่มข้อมูล เนื่องจากมีการพูดถึงในยุคค้นข้อมูลที่ทำให้การวิเคราะห์รู้ลึกขึ้น 4) การจัดเตรียมแดชบอร์ด (เช่นใน Power BI) เพื่อแสดงข้อมูลค่าภูมิภาคและเจตนา
เคล็ดลับ: ให้รวม “รายชื่อสีดำ” ของโดเมนที่ต้องการยกเว้นทั้งหมดจากการวิเคราะห์ (เช่น บริการที่ไม่เกี่ยวข้อง) แต่ให้สำรองข้อมูลโดยมีสำเนาข้อมูลที่ยังไม่ได้ดึงข้อมูลไว้ที่สำรองจึงจะได้ไม่ต้องกังวล
คำถามที่พบบ่อย
คำถาม 1: สามารถทำโดยไม่ต้องใช้โปรซี่มือถือได้หรือไม่? คำตอบ: ได้ถ้าคุณมี API ทางการพร้อมกับพารามิเตอร์ภูมิศาสตร์หรือใช้ศูนย์ข้อมูลในเมือง แต่อย่างไรก็ตามโปรซี่มือถือจะสะท้อนให้เห็นได้ชัดว่าผลการค้นหากระทบกับการค้นหาท้องถิ่นได้อย่างดี
คำถาม 2: จะลดความน่าจะเป็นของการถูกจดจำอย่างไร? คำตอบ: เพียงแค่เพิ่มระยะเวลาหยุดพัก ลดความน่าจะเป็นของการหยุดพักให้ดีที่สุดให้ท่านเปลี่ยน User-Agent และให้คงบำรุงรักษา IP ให้น้อยที่สุด รวมถึงข้อกำหนดที่เป็นทางการ
คำถาม 3: จะเข้าใจได้อย่างไรว่าเป็นคำค้นที่ปรับแต่ง? คำตอบ: หา
