LLMO и GEO в 2026: как попасть в ответы AI-поисковиков и выиграть трафик
Содержание статьи
- Введение: почему тема актуальна, что узнает читатель
- Основы: фундаментальные концепции (для новичков)
- Глубокое погружение: как устроены ai-ответы и факторы цитирования
- Метод 1. answer-first контент и модульная архитектура страниц
- Метод 2. schema.org и структурированные данные как «язык» для llm
- Метод 3. entity-центричное geo: как синхронизировать знания и регионы
- Метод 4. техническая пригодность для ai-ботов и ускорение ретривала
- Типичные ошибки: что не нужно делать
- Инструменты и ресурсы: что использовать
- Кейсы и результаты: реальные примеры применения
- Faq: 10 глубоких вопросов
- Заключение: резюме и следующие шаги
Введение: почему тема актуальна, что узнает читатель
В 2026 году пользователи все чаще начинают поиск не на классической странице результатов, а внутри AI-помощников и AI-поисковиков: ChatGPT, Perplexity, Claude, Gemini, YandexGPT. Ответ формируется прямо в чате и включает ссылки-цитации на источники, которым модель доверяет. Это не просто «новый тип выдачи». Это новая повестка для органического трафика и брендового присутствия. Вопрос звучит остро: как сделать так, чтобы ваш сайт попадал в цитируемые источники и чтобы ИИ строили ответы на основе вашего контента?
В этом руководстве вы разберете механику работы AI-поисковиков, узнаете, почему LLM-выдача подчиняется другим законам, чем классическое SEO, получите четкие методы оптимизации (LLMO), фреймворки для контента и схем разметки, чек-листы для технической готовности, подходы к геоперсонализации (GEO) и локализации, а также практические инструкции по мониторингу своих позиций в AI-ответах. Мы покажем, как и почему мониторинг требует мобильных прокси из разных регионов, и дадим инструменты для ежедневной работы.
Основы: фундаментальные концепции (для новичков)
Что такое LLMO
LLMO (Large Language Model Optimization) — это набор практик, которые повышают вероятность того, что большой языковой моделью ваш контент будет найден, понят, проверен и процитирован в ответе. В отличие от классического SEO, здесь важно не только ранжирование страницы, а пригодность контента к экстракции фактов, верификации и безопасному включению в консолидированный ответ.
Как действует AI-поиск
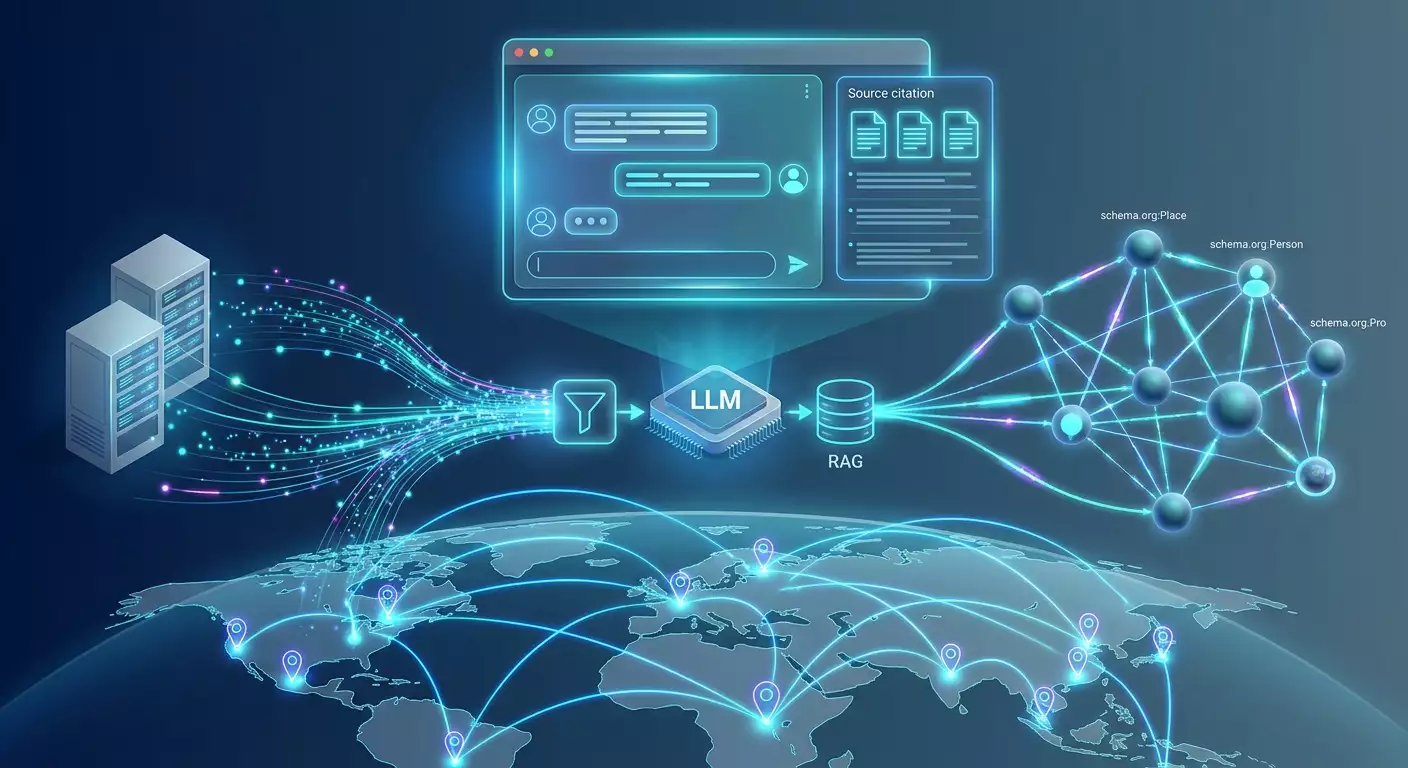
Современные системы используют гибрид: векторный поиск (embeddings) для семантического совпадения и классический индекс для точных совпадений и сигналов авторитетности. Дальше работает RAG-пайплайн (Retrieval-Augmented Generation): запрос интерпретируется, из индекса забираются кандидаты, проводится переоценка, строится план ответа, затем модель генерирует текст и «приземляет» его на источники, формируя блок цитирований.
Почему GEO-аспект критичен
Ответ зависит от страны, языка, валюты, норм и локальных реалий. Один и тот же запрос в разных регионах приводит к разным источникам и формулировкам. Поэтому GEO — это не «перевод страницы», а системная адаптация фактов, структурированных данных и сигналов доверия для конкретного региона.
Отличия LLMO от SEO
- Единица конкуренции — не сниппет и не позиция в SERP, а попадание в набор цитируемых источников внутри ответа.
- Ключевой фактор — верифицируемость фактов и структурированность знания для экстракции.
- Контент должен быть answer-first: четкие ответы, затем доказательная база.
- Пользовательский путь короче: меньше кликов, больше доверия к ответу ИИ. Значение бренда и экспертности возрастает.
Глубокое погружение: как устроены AI-ответы и факторы цитирования
Типовой пайплайн AI-поиска
- Интерпретация запроса: нормализация, выявление намерения, определение языка и региона.
- Кандидаты: гибридный поиск по векторному индексу и классическому индексу.
- Переоценка: модели ранжирования учитывают точность, полноту, свежесть, авторитет, соответствие GEO.
- План ответа: разбиение на подтемы (sub-queries), сопоставление каждому «опорных источников».
- Генерация с приземлением: LLM пишет ответ, ссылается на источники, выполняет проверку фактов (entailment).
- Безопасность и качественные фильтры: отсечение спорного, токсичного, сомнительного контента.
- Кэширование и персонализация по сеансу, региону, языку.
Ключевые факторы, которые повышают шанс цитирования
- Фактуальность и проверяемость: однозначные формулировки, цифры, дата-метки, источники-первички внутри контента.
- Структура и извлекаемость: разделы Q&A, списки, таблицы, HowTo, FAQ, Product-атрибуты; корректная schema.org в JSON-LD.
- Авторитет и профессиональная ответственность: указанные авторы-эксперты, редактор, дата обновления, методология.
- GEO-соответствие: локальные единицы измерения, валюта, телефоны, адреса, локальные кейсы.
- Свежесть и история обновлений: явные change logs, дата последнего апдейта, быстрая переиндексация.
- Техническая доступность: скорость, корректный рендер без JS-блокеров, разрешения для AI-ботов, sitemaps.
- Непротиворечивость: отсутствие рассинхрона в одной и той же сущности на разных страницах.
Почему это важно бизнесу
В множестве вертикалей к 2026 году до 35–45% информационных и коммерческих запросов стартуют с AI-ответов. Попадание в цитаты означает приток целевого трафика с высоким доверием и коротким циклом принятия решения. Пропуск — потерю доли внимания, даже если SEO-позиции остаются сильными.
Метод 1. Answer-first контент и модульная архитектура страниц
Принцип
Страницы должны быть собраны из модулей, которые LLM легко распознает и экстрагирует: «Короткий ответ» → «Развернуто» → «Доказательства» → «Шаги/HowTo» → «Частые вопросы» → «Источники/Методология». Эта структура повышает шансы на цитирование разных сегментов под разные сабзапросы.
Пошаговая инструкция
- Опишите целевую сущность и пользовательский интент. Что именно должно быть найдено и процитировано? Факт, сравнение, шаги, стоимость, определение, локальная политика?
- Создайте «Короткий ответ». 40–120 слов, точные формулировки, без рекламных оборотов, с датой актуальности.
- Развернутый блок. 200–400 слов. Уточнения, контекст, границы применимости.
- Доказательная база. Метрики, формулы, исходные данные, методология расчета. Для коммерции — условия, гарантии, параметры.
- HowTo/Steps. Четкие нумерованные шаги с материальными результатами каждого шага.
- FAQ. 6–10 вопросов, начинающихся с «как», «когда», «почему», «сколько», «что делать если».
- Localize. Валюта, номера телефонов, адреса, локальные примеры.
- Дата обновления и владелец. Автор-эксперт, редактор, дата, версия, контакт.
Чек-лист качества модуля
- Есть «короткий ответ» с датой.
- Есть цифры/диапазоны с единицами измерения.
- Есть локальные атрибуты (валюта, законы, адреса).
- Есть HowTo-список в явной структуре.
- Есть FAQ с прямыми вопросами.
- Author, reviewedBy, dateModified размечены в JSON-LD.
Фреймворк APEX
- Answer: сформулируйте ответ в 1 абзаце.
- Proof: приложите цифры и источники-первички.
- Expand: раскройте исключения, сравнения, альтернативы.
- Xecute: добавьте пошаговые действия и чек-листы.
Метод 2. Schema.org и структурированные данные как «язык» для LLM
Почему JSON-LD решает
LLM-поисковики активно используют структурированные данные как сигнал достоверности и «карту» для извлечения фактов. Корректная и богатая schema.org разметка помогает моделям уверенно соотнести факты с сущностями, авторством, временем, географией и правовым статусом.
Ключевые типы schema.org для LLMO
- WebPage и Article: headline, description, datePublished, dateModified, inLanguage, isPartOf.
- Organization: name, legalName, logo, contactPoint, sameAs, foundingDate, address.
- Person (автор/рецензент): name, affiliation, jobTitle, alumniOf, sameAs.
- FAQPage: список вопросов/ответов в явной структуре.
- HowTo: steps, supply, tool, estimatedCost, totalTime.
- Product: name, sku, brand, offers (price, priceCurrency, availability, priceValidUntil), aggregateRating.
- QAPage: для страниц со структурой вопрос-ответ с голосованием/экспертной модерацией.
- BreadcrumbList: контекст в иерархии.
- ClaimReview: для верификации конкретных утверждений, если применимо.
Практические правила
- Используйте JSON-LD на каждой релевантной странице; избегайте конфликтов между разметкой и видимым текстом.
- Указывайте гео-атрибуты: addressLocality, addressCountry, priceCurrency, applicableLocation, areaServed.
- Управляйте авторством: author, reviewedBy, publisher; для экспертных страниц — укажите квалификацию.
- Храните стабильные идентификаторы: @id для сущностей, чтобы LLM связывали страницы между собой.
- Обновляйте dateModified при значимых изменениях и ведите changelog в человекочитаемом виде.
- Маркируйте таблицы и фактические блоки в виде HowTo/FAQ/QuantitativeValue там, где это возможно.
Проверка корректности
Проверяйте JSON-LD валидаторами, следите за консистентностью с метатегами и контентом. Любая рассинхронизация снижает доверие модели и может выбросить страницу из набора кандидатов.
Метод 3. Entity-центричное GEO: как синхронизировать знания и регионы
Сущности и Knowledge Graph
AI-поисковики мыслят сущностями: компании, продукты, локации, услуги, процессы. Если ваша компания и ключевые предложения не структурированы как сущности с устойчивыми идентификаторами и атрибутами, модель будет «путаться» и подбирать другие источники.
Шаги по внедрению
- Создайте «домашние страницы сущностей» для компании, продуктов, тарифов, методологий. На них должны быть canon-атрибуты: названия, описания, параметры, ограничения, актуальные цены и валюты.
- Свяжите сущности между собой через внутренние ссылки и @id в JSON-LD, чтобы граф был сквозным.
- Добавьте sameAs на официальные внешние профили и каталоги, которые повышают доверие (без избыточности и дублирования).
- Локализуйте атрибуты: используйте hreflang, inLanguage, priceCurrency, areaServed, принимаемые способы оплаты и локальные контактные данные.
- Согласуйте юр-информацию: legalName, регистрационные данные, условия оферты и политики в региональном разрезе.
GEO-стратегия контента
- Язык и терминология: избегайте прямых кальк, используйте местную терминологию и отраслевые стандарты.
- Данные и примеры: кейсы из целевого региона, локальные исследования, диапазоны цен и сроки с учетом локальной логистики.
- Служба поддержки: локальный часовой пояс и каналы связи.
Метод 4. Техническая пригодность для AI-ботов и ускорение ретривала
Доступ и индексация
- Robots и AI-боты: не блокируйте легитимных AI-агентов; обеспечьте корректную подачу кэшируемых версий без динамических барьеров.
- Sitemaps: разнесите контент по типам (статьи, товары, справка), ведите sitemap-index, поддерживайте lastmod.
- HTTP-сигналы: используйте ETag, Last-Modified, корректные коды для сокращения издержек переобхода.
- Рендер: избегайте критически важного контента, загружаемого только JS-постфактом; делайте progressive enhancement.
Микроэндпойнты и документы
Для сущностей с табличными параметрами создайте легковесные «data endpoints» (например, JSON-страницы с ценами и параметрами), доступные для индексации. Для PDF используйте текстовые слои и оглавление; добавьте HTML-версии.
Свежесть и сигнал обновлений
- Публикуйте changelog на страницах.
- Обновляйте dateModified и отражайте точечные апдейты (например, пересчет цен).
- Отдельный фид обновлений, на который указывает robots и sitemaps.
Типичные ошибки: что не нужно делать
- Переоптимизация под ключевые слова без фактов и структуры: LLM это игнорирует.
- Скрытое авторство или отсутствие квалификации эксперта: снижает доверие.
- Дублирование сущностей с разными названиями и параметрами: граф «распадается», модель уходит к консистентным источникам.
- Один и тот же контент на все регионы: не учитывает локальные нормы и стоимость.
- JS-заглушки для ключевых данных, которые боты не видят: нет индексации фактов.
- Отсутствие валидации schema.org: ошибки в JSON-LD ломают извлекаемость.
- Игнорирование мониторинга: сложно управлять тем, чего вы не измеряете.
Инструменты и ресурсы: что использовать
Мониторинг позиций в AI-ответах
Стандартизированного «AI-SERP» еще нет, но мы можем собрать рабочую систему.
Принцип
- Определяем пул запросов (информационные, коммерческие, брендовые).
- Запускаем их в целевых AI-поисковиках через веб-интерфейс или API, если доступно.
- Сохраняем полный ответ и список цитируемых источников, фиксируем порядок и роль (главная опора, вторичная, примечание).
- Измеряем долю охвата: процент сессий, где наш домен процитирован, и среднюю позицию среди цитат.
- Повторяем из разных регионов и языков, чтобы увидеть GEO-распределение.
Почему критичны мобильные прокси
AI-ответы зависят от GEO и сетевого контекста. Разные регионы используют разные локальные источники, локальные цены и правовые рамки. Чтобы получать валидные результаты мониторинга, нужны IP-адреса из целевых стран и операторских сетей. Мобильные прокси дают разрешенную сетевую среду реальных SIM-карт, что важно для корректного геоопределения и кэш-слоев AI-сервисов.
Практика с MobileProxy.Space
Для распределенного мониторинга удобно использовать мобильные прокси с возможностью ротации и выбора страны/оператора. Сервис MobileProxy.Space предоставляет 218+ млн IP в 53+ странах на реальных SIM-картах операторов, протоколы HTTP(S) и SOCKS5 одновременно, гибкую ротацию по таймеру, API или ссылке, 3 часа бесплатного тестирования и поддержку 24/7. Это позволяет стабильно собирать срезы AI-ответов по регионам и часам. Промокод YOUTUBE20 дает 20% скидку на первую покупку.
Технический стек мониторинга
- Headless-браузеры с управляемым временем, языком и часовой зоной.
- Единый отпечаток браузера для повторяемости. Для диагностики используйте генератор отпечатков браузера на сайте MobileProxy.Space и карту задержек для выбора оптимальных точек.
- Проверка среды: перед запуском каждого прогона фиксируйте IP и проверьте утечки DNS через встроенные инструменты «Проверка IP», «DNS Leak Test» и «Proxy Checker».
- Хранилище результатов: сохраняйте сырые ответы, нормализуйте цитаты, версионируйте.
- Аналитика: метрики охвата, позиция в цитатах, частота упоминаний сущностей, по регионам и языкам.
Он-сайт инструменты качества
- Валидаторы schema.org и собственные автотесты консистентности JSON-LD и видимого контента.
- Логирование AI-ботов по User-Agent и ASN; анализ глубины обхода, частоты и кода ответа.
- Калькулятор прокси на сайте MobileProxy.Space для планирования прокси-профиля под число запросов и регионов.
Оптимизация сетевой доступности
Используйте карту задержек MobileProxy.Space для выбора регионов выхода, балансируйте пиринговые маршруты, следите за стабильностью RTT — это влияет на вероятность актуального кэша и скорость подгрузки страниц в момент ретривала.
Кейсы и результаты: реальные примеры применения
Кейс 1: B2B SaaS — рост цитируемости с 6% до 34% за 90 дней
Задача: продуктовая страница и центр знаний не попадали в AI-цитаты по ключевым запросам. Действия: внедрили APEX-структуру, добавили HowTo и FAQ, оформили авторство и reviewedBy, расширили JSON-LD (Product+HowTo+FAQPage), создали changelog. GEO: локализация терминологии на 3 языка, валюта по региону. Мониторинг из 8 стран через мобильные прокси. Результат: доля ответов, где домен цитируется, выросла с 6% до 34%, средняя позиция цитаты улучшилась с 3,1 до 1,7; конверсия из AI-трафика +22%.
Кейс 2: E-commerce каталог — достижение «ответов с ценами»
Задача: AI-поисковики называли цены конкурентов, игнорируя наш ассортимент. Действия: Product-разметка с offers, priceCurrency и сроком валидности, микроэндпойнт JSON с ценами, указание applicableLocation, areaServed. Добавили FAQ с доставкой и возвратами. Мониторинг ценовых ответов в 5 регионах. Результат: попадание в блоки ответов с ценами в 3 регионах за 45 дней; возвратность пользователей из AI-ответов +18%.
Кейс 3: Локальный сервис — укрепление регионального доверия
Задача: запросы «рядом со мной» и региональные правила. Действия: локальные landing-страницы с адресами, телефонами, графиком и localBusiness-разметкой; в FAQ — локальные законы и сроки. Результат: цитирование в YandexGPT и Gemini в региональных ответах, лиды из AI-источников +29% за квартал.
FAQ: 10 глубоких вопросов
Какая минимальная структура страницы, чтобы LLM начала нас цитировать?
Короткий ответ с датой, HowTo со 2–7 шагами, FAQ из 6–10 вопросов, явное авторство и reviewedBy, актуальная дата обновления, JSON-LD (WebPage+FAQPage+HowTo или Product). Плюс стабильные @id и локальные атрибуты.
Если у меня уже сильный SEO-трафик, нужно ли LLMO?
Да. AI-ответы укорачивают путь пользователя и перераспределяют клики. Даже при сильном SEO отсутствие цитирования в AI-поиске снижает долю внимания и узнаваемость бренда.
Как часто обновлять «короткие ответы»?
При изменении фактов: 1) новые цифры, 2) новые сроки или цены, 3) обновление норм. В противном случае — квартальный аудит с фиксацией dateModified и changelog.
Мешают ли paywall и авторизация ретривалу?
Частично. Ключевые факты и справочную часть держите в открытом доступе. Глубокую аналитику можно оставлять под авторизацией, но снабжать публичным резюме и структурированными данными.
Нужны ли отдельные страницы под каждую страну?
Если различаются правила, цены, сроки или язык — да. Используйте hreflang, inLanguage, priceCurrency, localBusiness, applicableLocation, areaServed и локальные контакты.
Как поступать с противоречивыми данными в отрасли?
Опишите диапазоны и условия, укажите источники, явно обозначьте методологию расчета. Такая прозрачность повышает доверие и шанс цитирования.
Что важнее: ссылки или структурированные данные?
В LLMO важнее извлекаемость и проверяемость фактов. Ссылки и упоминания по-прежнему значимы как общие сигналы авторитета, но без структуры модель не возьмет контент в ответ.
Как ускорить попадание обновлений в AI-ответы?
Поддерживайте свежие sitemaps и фид изменений, указывайте dateModified, используйте микроэндпойнты с важными параметрами, следите за корректными кодами ответов и ETag/Last-Modified.
Почему мониторинг требует прокси из разных регионов?
Потому что AI-поисковики персонализируют ответы по GEO: источники, цены, единицы, правовые ограничения. Результаты из одной страны не репрезентативны для другой. Мобильные прокси обеспечивают нужный сетевой контекст реальных операторских подсетей.
Как контролировать стабильность мониторинга?
Фиксируйте IP и регион в начале прогона, проверяйте среду инструментами «Проверка IP», «DNS Leak Test» и «Proxy Checker», используйте единый браузерный отпечаток (генератор на сайте), выбирайте регионы выхода по карте задержек. Ротуйте IP по расписанию или через API, как в MobileProxy.Space.
Заключение: резюме и следующие шаги
LLMO — это новый рабочий стол для контент- и продуктовых команд. Чтобы стабильно попадать в цитаты AI-поисковиков в 2026 году, нам нужно: 1) перейти на answer-first и модульную структуру страниц, 2) говорить с моделями на языке schema.org и устойчивых сущностей, 3) обеспечить техническую пригодность и свежесть, 4) локализовать факты и атрибуты под GEO, 5) выстроить мониторинг из разных регионов на базе мобильных прокси. Практически: возьмите приоритетный кластер запросов, упакуйте страницы по фреймворку APEX, внедрите JSON-LD с авторством и GEO-атрибутами, наладьте фид изменений и анализ логов ботов, запустите мониторинг ответов в ChatGPT, Perplexity, Claude, Gemini, YandexGPT через headless-браузер. Для достоверных региональных срезов используйте мобильные прокси с ротацией по таймеру, API или ссылке. Сервис MobileProxy.Space дает широкий выбор IP и стран, одновременные HTTP(S) и SOCKS5, 3 часа бесплатного тестирования и поддержку 24/7; промокод YOUTUBE20 — минус 20% на первую покупку. Не гонитесь за «магическими» приемами: выигрывают системность, факты, прозрачность и локальный контекст. Чем легче модель может проверить вашу страницу и извлечь из нее точный ответ, тем выше шанс увидеть свой домен среди цитат AI-поисковиков.
