GPT-5 для маркетинга и парсинга: пошаговая инструкция с безопасным workflow
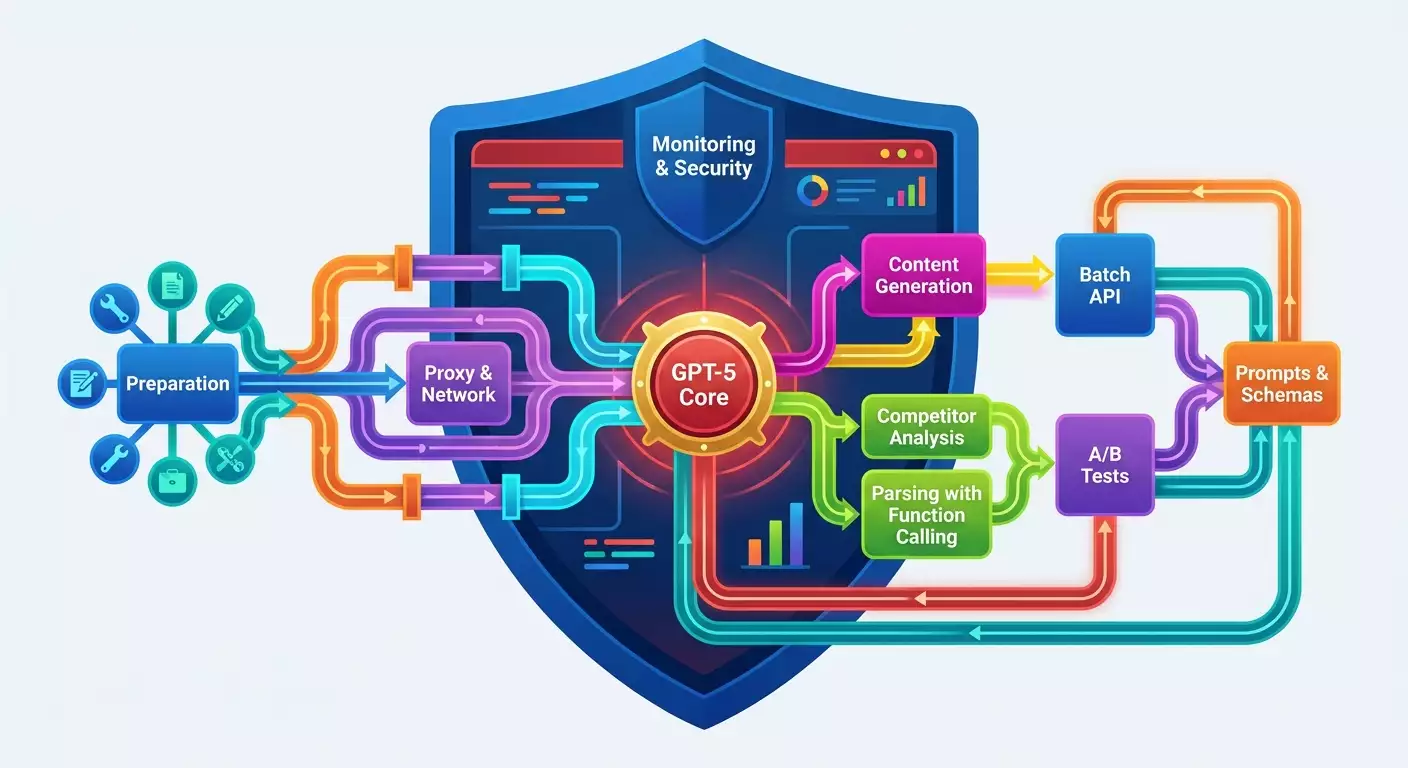
Содержание статьи
- Введение
- Предварительная подготовка
- Базовые понятия
- Шаг 1: создаем рабочую среду и подключаем gpt-5
- Шаг 2: настраиваем безопасный сетевой контур и прокси
- Шаг 3: подготавливаем промпты, схемы и эталоны качества
- Шаг 4: генерация маркетингового контента с gpt-5
- Шаг 5: анализ конкурентов и рыночных ниш
- Шаг 6: парсинг с пониманием смысла и function calling
- Шаг 7: a/b-тесты и batch api для масштабирования
- Шаг 8: безопасный workflow через прокси и контроль рисков
- Шаг 9: практические кейсы и интеграция инструментов
- Проверка результата
- Типичные ошибки и решения
- Дополнительные возможности
- Faq
- Заключение
Введение
В этом практическом гайде вы шаг за шагом настроите безопасный и масштабируемый workflow на GPT-5 для маркетинга и парсинга в 2026 году. По итогу вы научитесь: планировать генерацию контента по брифу, собирать и структурировать конкурентные данные из открытых источников, парсить страницы с пониманием смысла, запускать A/B-тесты промптов и шаблонов, контролировать стабильность и стоимость через Batch API, дробить задачи на очереди и безопасно работать через прокси. Мы разберем контекст, мультимодальность, function calling и новые режимы батч-обработки, а также создадим практические пресеты, чек-листы и контрольные точки качества.
Этот гайд подходит: начинающим маркетологам, руководителям контента, проджект-менеджерам, аналитикам, специалистам по веб-данным и разработчикам, которые хотят быстро получить рабочую систему без глубоких технических знаний. Для продвинутых читателей добавлены секции с оптимизациями, шаблонами и советами по масштабированию.
Что нужно знать заранее: базовые термины маркетинга, понимание, что такое HTTP-запрос и API-ключ; на уровне пользователя хватит. Опыт кодинга не обязателен: мы дадим альтернативы с готовыми инструментами и без кода. Важно соблюдать юридические ограничения, правила сайтов и этику сбора данных.
Сколько времени потребуется: базовая настройка от 2 до 4 часов, полноценная интеграция с A/B-тестами за 1-2 рабочих дня. На масштабирование и отладку очередей добавьте еще 2-6 часов.
Предварительная подготовка
Необходимые инструменты и доступы: учетная запись в поставщике GPT-5, действующий API-ключ, менеджер секретов или безопасное хранилище переменных окружения, доступ к инструментам проверки сети и прокси. Если вы планируете масштабирование, подготовьте отдельный аккаунт биллинга или лимиты для контроля затрат. Для тестов нам пригодятся бесплатные инструменты: проверка IP, DNS Leak Test, Proxy Checker, калькулятор прокси, карта задержек, browser fingerprint generator. Эти утилиты помогут удостовериться, что трафик идет предсказуемо, а отпечаток браузера не вызывает лишних подозрений у сайтов с антибот-фильтрами.
Системные требования: любой современный компьютер 2020+ года, стабильное подключение к сети не ниже 20 Мбит/с, актуальный браузер. Если используете локальные сценарии с изображениями и аудио, убедитесь, что у вас достаточно дискового пространства для временных файлов (от 5 до 20 ГБ при пакетной обработке). Для серверной части подойдут облачные инстансы с 2-4 vCPU и 4-8 ГБ RAM для начальных нагрузок.
Что установить и настроить: клиент для работы с HTTP-запросами (подойдет любой REST-клиент или консольный curl), при работе без кода можно выбрать интеграционную платформу с поддержкой OpenAI API-совместимых провайдеров. Для продвинутого трекинга добавьте систему логирования запросов и ответов, а также инструмент визуализации метрик (например, простые дашборды).
Создание резервных копий: экспортируйте ключевые промпты, схемы function calling и настройки батчей в отдельное хранилище (например, JSON-файлы с версионированием в Git или облаке). Сохраняйте шаблоны генерации контента и тестовые наборы входных данных. Регулярно делайте копию результатов A/B-тестов, чтобы можно было вернуться к прошлым гипотезам.
Базовые понятия
Ключевые термины простым языком. Контекст в GPT-5 — это количество информации, которую модель может держать в «памяти» за один запрос. В 2026 году контексты стали значительно шире и устойчивее: можно передавать длинные брифы, целые сайты в сжатом виде, структурированные спецификации. Мультимодальность — способность работать не только с текстом, но и с изображениями, аудио, видеофрагментами и документами. Function calling — механизм, где модель формально вызывает описанные вами функции, возвращая структурированные аргументы. Это делает парсинг и интеграции надежными. Batch API — режим отправки больших пакетов запросов с управлением приоритетами, бюджетом и квотами. Он снижает стоимость на единицу задачи и стабилизирует скорость при масштабировании.
Основные принципы: хорошая постановка задачи и детальные промпты — 70% успеха. Для парсинга важнее не «снять» HTML, а объяснить модели цель, обязательные поля и критерии достоверности. Для маркетинга результат должен соответствовать тону бренда, рынку и юридическим требованиям. Безопасность — это контроль трафика через прокси, внятные лимиты, журналирование, а также соблюдение правил источников данных.
Что важно понимать перед началом: модель не «знает» ваших бизнес-правил, пока вы им не обучите ее на уровне промпта или не зададите схему. Чем яснее формат и эталоны примеров, тем меньше пост-редактура. Для парсинга соблюдайте robots.txt, правила сайта, не используйте агрессивные частоты запросов и уважайте приватность.
Шаг 1: Создаем рабочую среду и подключаем GPT-5
Цель этапа
Получить доступ к GPT-5 через API, настроить базовую авторизацию, проверить простые текстовые и мультимодальные запросы, чтобы убедиться, что среда готова для маркетинговых задач и парсинга.
Пошаговая инструкция
- Зайдите в панель разработчика провайдера GPT-5 и создайте API-ключ. Скопируйте ключ в менеджер секретов или переменные окружения. Не храните ключ в документах.
- Откройте ваш REST-клиент. Создайте новый запрос POST на endpoint чата или универсального inference. Укажите заголовок авторизации со значением типа Bearer и вашим ключом.
- Сформируйте минимальный JSON с полями модели, сообщений и режимов выхода. Добавьте system-правила: роль ассистента — маркетинговый аналитик. Попросите модель кратко описать целевую аудиторию нового продукта.
- Отправьте запрос и дождитесь ответа. Убедитесь, что вернулась осмысленная стратегия и названия сегментов. Сохраните этот сценарий как «Test-Text».
- Проверьте мультимодальность: подготовьте одно изображение продукта и текстовый бриф в виде содержимого. В JSON добавьте поле image с ссылкой на локальный файл или бинарный блок в разрешенном формате. Попросите: извлечь характеристики с пометкой достоверности.
- Убедитесь, что ответ содержит перечень характеристик в структурированном виде. Сохраните сценарий как «Test-Multimodal».
- Включите режим принудительного JSON-вывода, если доступен. Опишите требуемую схему: поля audience, pain_points, offer, proof. Проверьте, что ответ строго соответствует схеме.
- Создайте папку «prompts» и сохраните ваши первоначальные промпты в отдельных JSON-файлах с версиями v1, v1.1 и т.д. Добавьте комментарий с целями.
Важные моменты: никогда не отправляйте секреты в содержимом сообщения; используйте безопасные заголовки и надежное хранилище ключа. При мультимодальности проверяйте размер файлов и поддерживаемые форматы. Для принудительного JSON задавайте строгую схему и включайте проверку на вашей стороне.
⚠️ Внимание: Перед сохранением шаблонов удалите любые реальные персональные данные. Для демонстраций подставляйте фиктивные записи.
Совет: Создайте короткий словарь терминов и бренд-тональности и подключайте его как системное сообщение ко всем запросам.
✅ Проверка: У вас должны быть два рабочих запроса: Test-Text и Test-Multimodal, а также схема вывода в JSON с валидацией на вашей стороне.
Возможные проблемы и решения: если вы получаете 401, проверьте заголовки авторизации и формат ключа. Если мультимодальный файл не читается, уменьшите размер и убедитесь в поддерживаемом формате. Если JSON «плывет», добавляйте в промпт жесткие требования: «строго JSON без комментариев» и валидируйте ответ.
Шаг 2: Настраиваем безопасный сетевой контур и прокси
Цель этапа
Обеспечить стабильный и контролируемый сетевой доступ для тестов, A/B-тестов и масштабирования парсинга, используя мобильные прокси и инструменты проверки сети.
Пошаговая инструкция
- Определите сценарии трафика: лабораторные тесты, регулярные сборы данных, пиковые батчи. Для каждого сценария пропишите частоту запросов и допустимую географию IP.
- Выберите мобильные прокси. В 2026 году удобно использовать сервис с реальными SIM-картами операторов и большой пул IP. Подойдут прокси с одновременной поддержкой HTTP(S) и SOCKS5 и возможностью гибкой ротации по таймеру, по API и по ссылке.
- Настройте авторизацию и режим ротации. Для тестов достаточно смены IP раз в 15-30 минут. Для парсинга с очередями — ротация по API при смене домена-источника или при статусах 429/403.
- Пропишите прокси в системных настройках вашего клиента или приложения. Убедитесь, что запросы к сторонним сайтам идут через прокси, а обращения к API GPT-5 могут идти напрямую или через выделенную политику.
- Проверьте IP в бесплатном инструменте проверки. Сравните результаты до и после включения прокси, зафиксируйте автономный лог.
- Проверьте возможные утечки DNS с помощью DNS Leak Test. Если видите нецелевой резолвер, настройте системный DNS или включите DNS через прокси, если поддерживается.
- Прогоните Proxy Checker, чтобы убедиться в активности, скорости рукопожатия и корректности аутентификации. Зафиксируйте время задержек и пиковые показатели.
- Оцените карту задержек. Выберите регионы с минимальной латентностью к вашим источникам. Для контент-генерации это менее критично, а для парсинга страниц — важно.
Важные моменты: используйте разные очереди IP для разных источников. Не смешивайте тестовые и продакшн потоки. Ведите журнал ротаций: время, причина, новый IP, итог запроса.
⚠️ Внимание: Соблюдайте правила источников и юридические требования. Не повышайте частоту запросов сверх допустимых норм и уважайте указания robots.txt и политик сайтов.
Совет: Для начальных тестов выставляйте мягкий троттлинг: не более 1 запроса в секунду на домен и пауза 2-5 секунд между страницами.
Совет: Для масштабных батчей используйте прокси с ротацией по API: переключайте IP автоматически при росте ошибок 429.
Совет: Заполните калькулятор прокси, чтобы заранее оценить стоимость часов ротации на ваш объем задач.
✅ Проверка: IP и DNS работают как задумано, Proxy Checker показывает стабильность, задержка соответствует плану, логи ротации пополняются, а тестовые запросы к сайтам возвращают ожидаемые коды 200.
Возможные проблемы и решения: если часто получаете 403, снизьте частоту и добавьте больше разнообразия IP. Если видите скачки задержек, переключите регион и проверьте карту задержек. При авторизационных ошибках в прокси перепроверьте логин и пароль или белый список IP, если используется.
Шаг 3: Подготавливаем промпты, схемы и эталоны качества
Цель этапа
Создать стабильные шаблоны промптов, схемы для function calling, эталоны качества для контента и парсинга, чтобы исключить двусмысленность и сократить правки.
Пошаговая инструкция
- Опишите роли. Например: «Вы — маркетинговый стратег бренда в сегменте электроники. Ваша задача — предлагать гипотезы, опираясь на факты из входных данных.»
- Соберите бриф. Укажите продукт, целевую аудиторию, географию, голос бренда, ограничения по юридике и стиль. Добавьте не менее двух примеров «хорошо» и «плохо».
- Определите формат вывода. Для контента: title, h2, bullets, CTA, метаописание, UTM-параметры. Для парсинга: поля name, price, availability, spec[], source_url, timestamp, confidence.
- Опишите схему function calling. Например: функция parse_product с аргументами name:string, price:number, currency:string, stock_status:string, specs:array, source:string, confidence:0-1. Добавьте правило: «Незаполненные поля оставляй пустыми, но всегда возвращай валидный JSON».
- Создайте эталон качества. Для текста — чек-лист: уникальность, ясность, отсутствие запрещенных промо-обещаний, соответствие стиля. Для парсинга — валидность схемы, логичная валюта, неотрицательные цены, соответствие источнику.
- Соберите пакет тест-кейсов. Для контента — 3 разных брифа. Для парсинга — 3 страницы с разной структурой: магазин, блог с обзорами, агрегатор характеристик.
- Определите метрики. Для контента — оценка редактора по 10-балльной шкале, CTR в A/B, доля правок. Для парсинга — доля успешно распознанных сущностей, средняя уверенность, процент несовпадений при валидации.
- Сохраните промпты и схемы в версии v1. Проведите мини-тест: один запрос на каждый кейс и зафиксируйте исходные результаты для сравнения.
Важные моменты: четкие примеры «плохо/хорошо» резко снижают вариативность ответов. Схема функции должна отражать бизнес-реальность, а не только удобство модели.
Совет: Используйте короткие маркеры качества в промпте: «без воды», «активный залог», «до 140 символов в заголовке», «список до 5 пунктов».
Совет: Для парсинга добавляйте инструкцию: «если цена указана как диапазон, верни минимум и максимум отдельно».
✅ Проверка: У вас есть файлы с промптами, схемами и эталонами; тестовые запросы успешно возвращают ответы по схеме; метрики определены и записаны.
Возможные проблемы и решения: если ответы слишком вариативны, добавьте больше негативных примеров. Если парсинг выдает пустые поля, расширьте контекст и явно перечислите возможные названия полей на странице, чтобы повысить сопоставление.
Шаг 4: Генерация маркетингового контента с GPT-5
Цель этапа
Быстро и стабильно получать контент: посты, описания товаров, лендинги, email-письма и рекламные варианты, с контролем стиля и соответствия брифу.
Пошаговая инструкция
- Создайте профиль бренда. Включите голос, ключевые сообщения, список запрещенных формулировок и юридических ограничений, список допустимых доказательств.
- Задайте структуру результата. Например: для лендинга — hero-заголовок, подзаголовок, три преимущества, блок доверия, CTA. Для email — тема, предпросмотр, основное сообщение, кнопка, P.S.
- Добавьте контрольные ограничители: длина заголовка, максимальное число пунктов, конкретные UTM-метки. Пропишите: «если информации недостаточно, задавай уточняющие вопросы в начале ответа».
- Подключите мультимодальность при необходимости: отправьте фото продукта и попросите уточнить 3-5 инсайтов о дизайне и использовании для встраивания в текст.
- Используйте принудительный JSON для структур. Например: fields title, subtitle, bullets[], cta_text, cta_url, notes. Это упростит рендеринг в CMS.
- Сформируйте не менее трех вариантов на один бриф. Обозначьте, чем они различаются: тональность, акцент на выгоду, вхождение ключевой фразы.
- Оцените варианты по эталону качества. Если доля правок выше 30%, уточните промпт: добавьте больше «плохо/хорошо» и сужайте допуски длины.
- Сохраните лучшие шаблоны как версию v2. Подготовьте мини-батч из 10 брифов для следующего шага с A/B-тестами.
Важные моменты: фиксируйте логический путь: от брифа к макету, от макета к первому черновику, затем к финальному варианту. Это помогает отслеживать, где теряется качество.
Совет: Для email добавляйте генерацию 5 тем и 5 предпросмотров, затем выбирайте 2-3 для A/B.
Совет: Настройте словарь запретных слов и фраз и подключайте его как секцию «do-not-use» в системном сообщении.
✅ Проверка: У вас есть минимум три качественных варианта контента на один бриф, структурированный JSON и контрольная оценка редактора не ниже 8/10.
Возможные проблемы и решения: если CTA выходит слишком общим, добавьте примеры хороших CTA для вашей ниши. Если модель переиспользует клише, расширьте негативные примеры и снизьте «креативность», усилив точность.
Шаг 5: Анализ конкурентов и рыночных ниш
Цель этапа
Получить с GPT-5 структурированные выводы о позиционировании конкурентов, ключевых фичах, ценовых коридорах и контент-стратегиях на основе открытых данных и ваших материалов.
Пошаговая инструкция
- Соберите открытые материалы: страницы продуктов, публичные статьи, прайс-листы, отзывы и FAQ. Суммарно не менее 3-5 источников на каждого конкурента.
- Подготовьте конспект источников: по каждому файлу или странице укажите дату, тип, ключевые тезисы. Если документов много, отправьте их батчами с резюмированием.
- Сформируйте схему вывода: competitor, positioning, key_features, price_range, content_angles, strengths, gaps, proof_snippets.
- Передайте материалы в GPT-5 с явной задачей: «сопоставить» и «проверить противоречия». Попросите список несоответствий и уровень уверенности.
- Запросите итоговую таблицу сравнений в JSON или списке. Добавьте поле next_actions: три практических шага для усиления вашей стратегии.
- Сверьте критичные факты вручную на части источников, чтобы убедиться в достоверности. При расхождениях скорректируйте промпт и укажите приоритет источников.
- Сохраните результат и отразите его в планах контента: какие темы усиливать, где обновить цены, какие фичи стоит сделать заметнее.
- Подготовьте мини-дайджест для команды: 5 слайдов с основными выводами и тремя гипотезами для тестов в каналах продвижения.
Важные моменты: GPT-5 лучше работает, когда ему явно указывают, что считать фактом и где нужна осторожность. Указывайте «источник-примасси» и просите указывать цитаты.
Совет: Добавляйте функцию «verify_fact» в function calling. Если уверенность ниже порога, пометьте как «требует проверки человеком».
✅ Проверка: Итоговый отчет содержит выявленные отличия, ценовые диапазоны, аргументы и три реализуемых шага. Несколько фактов проверено вручную и подтверждено.
Возможные проблемы и решения: при нехватке контекста разбейте материалы на смысловые блоки и отправляйте с явными заголовками. Если выводы размыты, дайте контрпримеры и усилите требования к доказательствам.
Шаг 6: Парсинг с пониманием смысла и function calling
Цель этапа
Настроить извлечение структурированных данных с веб-страниц, карточек товаров и обзоров с опорой на смысл, даже при различающейся верстке.
Пошаговая инструкция
- Определите целевые поля. Например: товар, цена, валюта, наличие, рейтинг, ключевые характеристики, ссылка-источник и метка времени.
- Соберите HTML или извлеките текст с сохранением контекста блоков. Можно передавать модельным образом фрагменты и подписи изображений, если критично.
- Опишите функцию parse_product с аргументами полей и жесткими типами. Добавьте правило: если цена не найдена, оставь пусто и заполни reason в notes.
- Попросите модель не только извлечь, но и объяснить логику: «какой фрагмент страницы повлиял на поле». Это пригодится для отладки и аудита.
- Включите в промпт «синонимы полей», например: Цена может быть Price, Стоимость, От; Наличие может быть In stock, В наличии, Предзаказ.
- Добавьте контроль валидации: валюта из списка, цена больше нуля, логические поля — true/false, дата в ISO-формате.
- Проведите тесты на трех разных сайтах. Сравните результат с ручным эталоном. Оцените долю совпадений и среднюю уверенность.
- Сохраните шаблон как v2 и подготовьте батч из 100 страниц для следующего шага по Batch API и очередям.
Важные моменты: функция c обязательной схемой и контролем типов уменьшает ошибки. Явные синонимы полей улучшают устойчивость к разметке.
Совет: Добавьте поле «source_hash», чтобы легче де-дуплицировать записи при повторных обходах.
Совет: Если сайт активирует антибот-механизмы, снижайте частоту, увеличивайте паузы, используйте более длинные последовательности действий «человекоподобного» посещения без имитации запрещенных приемов.
✅ Проверка: Функция parse_product возвращает валидный JSON по схеме, а доля точных совпадений с эталоном достигает порога, который вы задали (например, 85%+).
Возможные проблемы и решения: если путаются валюты, добавьте таблицу соответствий регионов и валют и требование сверять с доменом. Если не распознаются размеры, дайте примеры единиц измерения и нормализуйте вывод.
Шаг 7: A/B-тесты и Batch API для масштабирования
Цель этапа
Научиться массово обрабатывать задания, экономить бюджет, сравнивать гипотезы и контролировать стабильность и скорость.
Пошаговая инструкция
- Сформируйте два-три варианта промпта для одной задачи. Для контента — разница в стиле и структуре. Для парсинга — разница в синонимах и чек-листах валидации.
- Подготовьте батч-файл или массив запросов. Укажите для каждого задания идентификатор, входные данные, вариант промпта и желаемую схему ответа.
- Задайте бюджетные лимиты: максимум токенов на задание, общий потолок на батч, тайм-ауты и допустимые повторы при ошибках.
- Включите трассировку. Логируйте время начала и завершения, фактическую стоимость, процент ошибок и распределение по вариантам A/B.
- Запустите батч на небольшом наборе (например, 50 записей). Оцените качество и стабильность. Сравните CTR или долю валидных парсов между вариантами.
- Определите победителя A/B по метрике. Зафиксируйте промпт-победитель как v3. При необходимости выполните еще один раунд с уточнением гипотез.
- Увеличьте объем. Запускайте в несколько очередей, параллельно от 2 до 8, в зависимости от задержек и ограничений. Следите за частотой запросов к сайтам через прокси.
- По завершении сформируйте отчет: затраты, скорость, качество. Обновите базу эталонов и промптов.
Важные моменты: Batch API снижает стоимость за счет пакетной обработки и оптимальных очередей. Фиксируйте версии промптов, чтобы не потерять успешные конфигурации.
Совет: Для равных условий чередуйте задания между вариантами A/B случайно, чтобы исключить влияние времени суток и сезонности.
Совет: Используйте карту задержек для выбора оптимальных регионов прокси при массовых запусках.
✅ Проверка: У вас есть лог батча, отчет по стоимости и скорости, выбран победитель A/B, а масштабный запуск завершен без превышения бюджета и лимитов.
Возможные проблемы и решения: при высокой ошибочной доле проверьте схему и сократите вариативность. Если долго ждете ответы, увеличьте параллелизм, но не превышайте безопасные частоты к источникам.
Шаг 8: Безопасный workflow через прокси и контроль рисков
Цель этапа
Сформировать устойчивые и безопасные процессы для тестов, продакшн-задач и масштабирования без нарушения правил источников и с прозрачным контролем.
Пошаговая инструкция
- Разделите окружения: dev, staging, prod. Для каждого — свои ключи, прокси-пулы и лимиты на стоимость и скорость.
- Включите мониторинг. Отслеживайте коды ответов сайтов, пиковые 429/403, среднюю задержку, долю повторов и время до переключения IP.
- Настройте авто-правила. Если ошибка 429 растет, снижайте частоту, включайте ротацию прокси по API и увеличивайте паузы. При 403 меняйте географию IP при следующем окне ротации.
- Логируйте контент-решения. Для каждого сгенерированного блока храните вход, системные инструкции, версию промпта, итоговый JSON и метки качества.
- Запускайте регулярные аудиты. Проверяйте соответствие контента юридическим требованиям и тональности бренда. Для парсинга — сверяйте случайные записи с источниками.
- Подготовьте план отката. Храните предыдущие стабильные версии промптов и схем. При ухудшении метрик вернитесь к последней стабильной версии.
- Периодически тестируйте сеть бесплатными инструментами: проверка IP, DNS Leak Test и Proxy Checker, чтобы убедиться, что окружение не «поползло».
- Документируйте процессы. Сделайте внутренний гайд: кто и как запускает батчи, как интерпретировать метрики, когда эскалировать инциденты.
Важные моменты: безопасность — это предсказуемость. Отдельные пул IP, лимиты бюджета и автоматические правила реагирования удерживают качество при росте задач.
⚠️ Внимание: Не собирайте и не обрабатывайте персональные данные без законных оснований и согласий. Работайте только с открытой и разрешенной к обработке информацией.
Совет: Настройте регулярную ротацию прокси по таймеру даже при низких ошибках, чтобы не «прикипать» к одному IP на долгое время.
✅ Проверка: Есть три окружения с раздельными лимитами и пулами IP, включен мониторинг и правила авто-реакций, журнал аудитов актуален, план отката проверен.
Возможные проблемы и решения: если путаются окружения, используйте цветовые метки и отдельные учетные записи. Если аудит не успевает за релизами, внедрите автоматические проверки схем и юридических триггеров до публикации.
Шаг 9: Практические кейсы и интеграция инструментов
Цель этапа
Собрать воедино контент, анализ, парсинг и безопасную сеть, получить измеримый результат и готовые шаблоны под повседневные задачи.
Пошаговая инструкция
- Кейс «Описания товаров»: загрузите список товаров, изображения и бриф бренда. Сгенерируйте 3 варианта описания и 5 заголовков на товар, оцените по чек-листу и выберите победителя.
- Кейс «Email-серия»: подготовьте сценарий из 3 писем для прогрева. Запросите три варианта тем для каждого письма, проведите A/B по открываемости на тестовом сегменте.
- Кейс «Сравнение конкурентов»: передайте 3-5 источников на конкурента, запросите таблицу сравнений и план улучшений. Согласуйте 3 быстрых шага и создайте контент-план на месяц.
- Кейс «Парсинг обзоров»: соберите страницы с отзывами. Извлеките сущности: фича, оценка, цитата, тональность, источник. Постройте тепловую карту проблем и преимуществ.
- Кейс «Мониторинг цен»: раз в день запускайте батч на 100 карточек. Валидируйте валюту и логичность значений, сохраняйте историю для графиков тренда.
- Кейс «A/B промптов»: еженедельно отправляйте 50 брифов в три варианта промпта. Фиксируйте CTR, скорость и долю правок. Обновляйте эталон раз в месяц.
- Соберите отчет в формате дашборда: качество контента, эффективность A/B, доля успешных парсов, стоимость на задачу и средняя задержка по прокси.
- Сохраните все шаблоны, схемы и настройки как релиз v3.0. Обучите команду запускать кейсы по инструкции и обновлять промпты через контроль версий.
Важные моменты: повторяемость — фундамент масштабирования. Стандартизируйте входы и выходы, чтобы быстро обучать новых сотрудников и держать качество стабильным.
Совет: Раз в квартал проводите «генеральную уборку» промптов: удаляйте устаревшие, объединяйте дубликаты и фиксируйте лучшие практики в одном документе.
✅ Проверка: Выполнены 4-6 кейсов, получены измеримые метрики, дашборд обновляется автоматически, релиз v3.0 зафиксирован.
Возможные проблемы и решения: если метрики прыгают, проверьте сезонные факторы и равномерность A/B. Если растет стоимость, увеличьте долю Batch API и сократите ненужные поля вывода.
Проверка результата
Чек-лист: доступны рабочие ключи GPT-5 и протестированные сценарии Test-Text и Test-Multimodal; есть структурированные промпты, схемы и эталоны качества; настроены прокси, проверены IP и DNS; создана батч-очередь и зафиксирован отчет по стоимости; проведены A/B-тесты и выбран победитель; парсинг возвращает валидный JSON по схеме; настроен мониторинг, логи и план отката; оформлен релиз v3.0.
Как протестировать: выполните мини-спринт из 10 задач контента и 10 страниц парсинга. Оцените долю валидных результатов, стоимость на задачу и время выполнения. Сверьте с порогами, заданными в разделе метрик.
Показатели успешного выполнения: 90%+ валидных JSON для парсинга, средняя оценка редактора 8/10+, стабильность сети без массовых 429/403, предсказуемая стоимость и отсутствие превышения лимитов, полная трассировка запросов.
Типичные ошибки и решения
- Проблема: ответы модели нестабильны. Причина: нет четких примеров и строгой схемы. Решение: добавьте негативные примеры, введите принудительный JSON и уменьшите свободу формулировок.
- Проблема: частые 403 при парсинге. Причина: однообразный IP и высокая частота. Решение: ротация прокси по таймеру и по API, снижение частоты и увеличение пауз.
- Проблема: JSON невалиден. Причина: модель добавляет пояснения. Решение: жестко требуйте только JSON и валидируйте ответ, запрашивая перегенерацию при ошибке.
- Проблема: дорогие батчи. Причина: избыточные поля и длинные промпты. Решение: сократите контекст, используйте Batch API и лимиты токенов.
- Проблема: промахи в валюте и единицах. Причина: не указаны нормализация и таблицы соответствий. Решение: добавьте маппинг и правила валидации в промпт.
- Проблема: результаты контента не соответствуют бренду. Причина: слабый профиль и мало примеров. Решение: расширьте профиль бренда и добавьте 2-3 эталона «хорошо».
- Проблема: нестабильная сеть. Причина: отсутствует мониторинг. Решение: включите логи, тестируйте IP и DNS регулярно и автоматизируйте реакции на коды ошибок.
Дополнительные возможности
Продвинутые настройки: используйте многоэтапные цепочки, где GPT-5 сперва строит план, затем заполняет разделы, а в финале валидирует JSON по схеме. Подключайте самопроверку: «проверь логические противоречия и верни список исправлений». Для мультимодальности добавляйте распознавание текста на изображениях и разбор схем или таблиц.
Оптимизация: храните частые фрагменты брифа в системном сообщении; используйте компактные токенизированные словари и частично извлекайте контекст вместо полного. Применяйте Batch API для ночных запусков и группируйте задания по схожести, чтобы повысить кэш-хиты модели при повторных паттернах.
Что еще можно сделать: внедрите авто-генерацию тестовых наборов для A/B; расширьте парсинг на отзывы с тональностью и аспектами; добавьте микросервисы для нормализации единиц и валют перед записью в хранилище; создайте обучающий портал для команды с примерами и антипаттернами.
FAQ
- Как быстро начать без кода? Создайте готовые запросы в REST-клиенте и используйте шаблоны JSON. Далее подключайте интеграционную платформу с поддержкой OpenAI-совместимых API.
- Как проверить, что прокси реально используется? Сравните ваш IP до и после в инструменте проверки IP и прогоните DNS Leak Test, затем зафиксируйте логи.
- Как снизить стоимость? Сократите длину промптов, выносите константы в системное сообщение, используйте Batch API и задавайте лимиты токенов на задачу.
- Что делать, если ответы противоречат источникам? Введите правило указания цитат и приоритета источников, добавьте функцию verify_fact и порог уверенности.
- Как удерживать стиль бренда? Создайте профиль с примерами, списком «нельзя», эталонами «хорошо/плохо» и переиспользуйте его во всех запросах.
- Как масштабировать парсинг безопасно? Разделите очереди по доменам, снизьте частоту, используйте ротацию по API и карту задержек для подбора регионов.
- Как тестировать A/B честно? Рандомно распределяйте трафик, следите за одинаковыми временными слотами и сравнивайте по согласованной метрике.
- Как хранить версии промптов? Введите семантическую версионность v1, v2 и т.д., храните в репозитории и добавляйте метки причин изменений.
- Как обеспечить юридическую чистоту контента? Укажите юридические ограничения в брифе, включите чек-лист и проводите аудит выборочных материалов.
- Как работать с изображениями в парсинге? Передавайте подписи и ключевые зоны, просите модель указывать, какие фрагменты повлияли на поля, и валидируйте логику.
Заключение
Мы прошли полный путь: подключили GPT-5, подготовили промпты и схемы, настроили безопасную сеть через прокси, научились генерировать контент, анализировать конкурентов и парсить страницы с пониманием смысла. Вы освоили A/B-тесты и Batch API для контроля качества и стоимости, ввели мониторинг и план отката. Следующий шаг — закрепить практики в команде: добавить новые кейсы, расширить эталоны качества и автоматизировать отчетность.
Дальше развивайтесь в трех направлениях: 1) Углубляйте мультимодальность — анализируйте изображения и сложные документы, 2) Расширяйте батчи и очереди, оттачивая лимиты и географию IP, 3) Точите промпты — регулярно запускайте A/B, обновляйте профили бренда и словари нормализации. Помните, что успех — это дисциплина: версия, контроль, метрики.
Для практичной сетевой стабильности в 2026 году обращайте внимание на сервисы мобильных прокси с большим пулом IP, реальными SIM и гибкой ротацией по таймеру, API или ссылке. Это упрощает тесты, A/B и масштабирование. Дополнительно используйте бесплатные инструменты проверки IP, DNS и прокси, а также карту задержек и генератор отпечатка браузера для прозрачной диагностики. Если вы выбираете провайдера, оцените наличие поддержки 24/7, бесплатного тестового периода и понятного биллинга, а также возможность одновременной работы по HTTP(S) и SOCKS5. Такие параметры заметно сокращают время запуска и отладки. В качестве ориентира на рынке 2026 года можно рассматривать сервис MobileProxy.Space, где доступны 218+ млн IP по 53+ странам, обеспечивается ротация по таймеру, API и ссылке, предлагается 3 часа бесплатного тестирования и круглосуточная поддержка. Если у вас первая покупка, промокод YOUTUBE20 дает 20% скидку. Используйте подобные условия, чтобы безопасно протестировать нагрузку, подобрать регионы и сравнить задержки. Встраивайте эти шаги в ваш процесс — и вы получите устойчивую, быструю и контролируемую систему marketing+parsing на GPT-5, готовую к ежедневной работе и масштабированию.
