Скрапинг с LLM в 2026: Firecrawl, Reader API, Crawl4AI и мобильные прокси — пошаговая инструкция
Содержание статьи
- Введение
- Предварительная подготовка
- Базовые понятия
- Шаг 1: планируем пайплайн и выбираем инструмент
- Шаг 2: готовим окружение и зависимости
- Шаг 3: понимаем роль мобильных прокси и ограничения дата-центр ip
- Шаг 4: быстрый старт с reader api (jina)
- Шаг 5: быстрый старт с firecrawl
- Шаг 6: быстрый старт с crawl4ai
- Шаг 7: подключаем ротацию мобильных прокси
- Шаг 8: обработка ошибок, повторные попытки и защита бюджета
- Шаг 9: сравниваем firecrawl, reader api и crawl4ai
- Проверка результата
- Типичные ошибки и решения
- Дополнительные возможности
- Faq
- Заключение
Введение
В этом пошаговом гайде вы научитесь разворачивать современный LLM-скрапинг в 2026 году на трех ключевых инструментах: Firecrawl, Reader API (Jina) и Crawl4AI. Вы сравните их возможности, цены и сценарии применения, подключите мобильные прокси, поймете, почему дата-центр прокси в 2026 часто не дают нужный success rate, и получите готовые примеры кода на Python. В конце у вас будет рабочий конвейер: от запроса к странице — до чистого текста, структурированных данных и устойчивых запросов через ротацию мобильных IP.
Этот гайд для начинающих разработчиков, дата-аналитиков, специалистов по SEO, маркетологов и продвинутых пользователей, которым нужен надежный и воспроизводимый скрапинг. Предварительных знаний немного: базовый Python, понимание HTTP-запросов и токенов API. Время выполнения — 2–6 часов, в зависимости от выбранного пути и объема тестов.
К концу руководства вы получите: устойчивый пайплайн для скрапинга с LLM, подключение к Firecrawl, Reader API и Crawl4AI, примеры кода с HTTP(S) и SOCKS5 через мобильные прокси, план мониторинга и чек-листы стабильности, а также понимание оптимизации стоимости.
Предварительная подготовка
Для работы понадобится: компьютер с Windows, macOS или Linux; установленный Python 3.10+; менеджер пакетов pip; учетные записи в Firecrawl и Jina AI (Reader API), если тестируете эти сервисы; доступ к мобильному прокси-провайдеру, поддерживающему HTTP(S) и SOCKS5, ротацию по таймеру и по API. Важно иметь стабильный интернет и резервное место на диске для логов (минимум 1–2 ГБ).
Системные требования: 4 ГБ ОЗУ минимум (8 ГБ лучше), актуальные сертификаты корневых центров (обычно в системе уже есть), установленные системные зависимости для браузерных движков, если вы пойдете путем Crawl4AI с рендерингом (например, Playwright скачает необходимые компоненты при установке).
Что скачать и установить: Python 3.10+, pip, виртуальное окружение venv (или conda), библиотеки requests, httpx, pydantic (для удобной валидации), а также выбранные клиенты SDK или просто будете вызывать REST API. Для Crawl4AI потребуется установка пакета и движка Playwright. Дополнительно подготовьте текстовый редактор или IDE, например VS Code. Включите журналирование (лог-файлы) в проектах, чтобы можно было быстро понять место ошибки.
Резервные копии: сохраните все ключи API отдельно в менеджере секретов или .env-файле с ограниченным доступом. Для проектов с локальным рендерингом делайте резервные копии конфигураций прокси и файлов с маршрутами краулинга. В случае неудачи вы сможете откатиться к рабочему состоянию.
Базовые понятия
Скрапинг — это автоматический сбор информации со страниц сайтов по заранее заданным правилам. LLM-скрапинг — это подход, где модель или «читалка» на базе нейросетей помогает извлекать чистый текст, сущности, таблицы или даже краткие резюме из страниц, часто обходясь без тяжелой ручной верстки парсеров. Прокси — это сервер-посредник. Дата-центр прокси — IP из дата-центров, которые в 2026 году массово распознаются системами антибот-защиты. Мобильные прокси — IP-адреса операторов сотовой связи (реальные SIM), которые обычно имеют выше доверие и менее предсказуемые паттерны, что дает больший success rate. Антибот-сигналы — это метрики, по которым сайт решает, реальный ли вы пользователь: IP-репутация, ASN и гео, TLS-отпечатки, последовательность запросов, задержки, поведение рендеринга, частота запросов и т. п.
Ключевой принцип работы в 2026 году: LLM-экстракция или «читалки» типа Reader API берут на себя разбор контента и нормализацию формата, а краулер (локальный или облачный) обеспечивает устойчивое получение страницы. Прокси — критичный слой надежности. Мобильные прокси повышают успешность за счет реальных ASN операторов, CGNAT, динамики и «похожести» на людей. Чаще всего совет: используйте LLM-пайплайн плюс мобильные прокси там, где нужно стабильно и долго собирать данные с широкого круга доменов.
Важно понимать: юридическая сторона. Изучайте правила сайтов, robots.txt, условия использования и требования к нагрузке. Соблюдайте законодательство вашей юрисдикции и не собирайте персональные данные без законных оснований. Технически вы сможете многое, но этически и юридически — действуйте осознанно.
Шаг 1: Планируем пайплайн и выбираем инструмент
Цель этапа: понять, какой из трех инструментов подходит под вашу задачу, оценить бюджет и составить мини-ПОС (план осуществления скрапинга) с метриками успеха.
- Определите цель: что именно вы хотите извлечь — чистый текст, структурированные сущности, таблицы, резюме страницы, список ссылок, изображения.
- Оцените источники: сколько доменов, какие типы страниц (статические, динамические, SPA), есть ли ограничение на скорость и частоту.
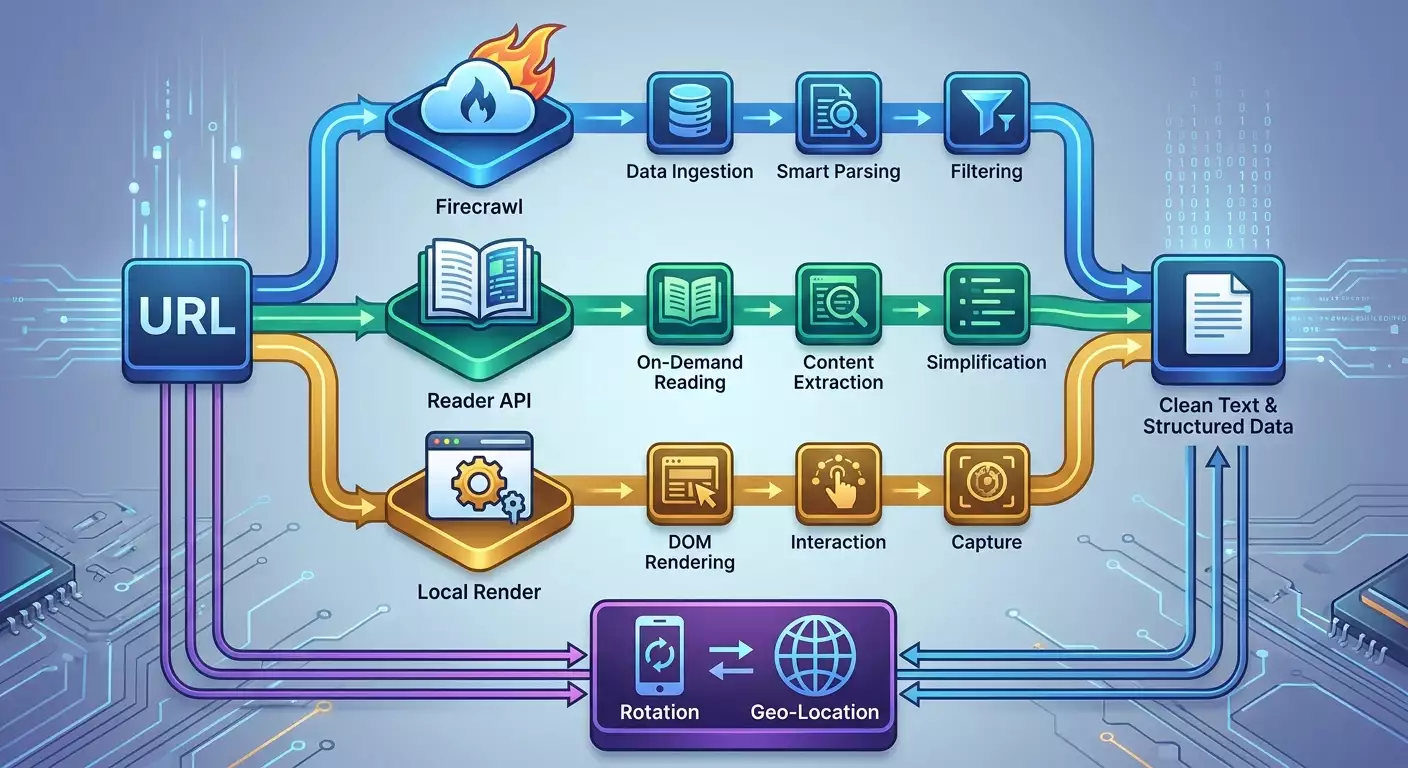
- Выберите инструменты: Firecrawl — управляемый облачный краулер с LLM-конденсацией контента; Reader API (Jina) — легкая «читалка» для преобразования URL в чистый текст или разметку; Crawl4AI — локальный или контейнерный способ с контролем над браузером и сетью.
- Считайте бюджет: Firecrawl — план 2026 года обычно включает бесплатный тест и платные уровни (например, Starter около 19–39 USD в месяц для малых проектов, Pro около 99–199 USD, Enterprise по запросу). Reader API — бесплатный уровень на ограниченное число страниц или символов, платные около 0.002–0.01 USD за страницу или 1k токенов. Crawl4AI — open-source, сам по себе бесплатен, но требует оплату инфраструктуры, мобильных прокси и, возможно, ротации IP.
- Спланируйте прокси: дата-центр IP в 2026 дает низкий success rate на крупных сайтах из-за репутации и поведенческих фильтров. Планируйте мобильные прокси с одновременной поддержкой HTTP(S) и SOCKS5, ротацией по таймеру и по API, а также достаточным гео-покрытием.
- Определите метрики успеха: success rate (например, целевые 80–95%), средняя задержка, стоимость за 1000 успешных страниц, частота rotate-IP, доля страниц с корректной экстракцией LLM.
Совет: Если вы делаете только извлечение текста и кратких резюме, начните с Reader API и мобильного прокси. Если вам нужен управляемый краул из коробки — тестируйте Firecrawl. Если вы хотите сложные сценарии клика и рендеринга — идите в Crawl4AI.
✅ Проверка: У вас есть документ с выбором инструмента, предварительный бюджет и целевые метрики успеха.
Шаг 2: Готовим окружение и зависимости
Цель этапа: создать изолированное Python-окружение, установить нужные пакеты и подготовить конфигурацию прокси и секретов.
- Создайте папку проекта: например, llm-scrape-2026.
- Создайте виртуальное окружение: в терминале выполните python -m venv .venv и активируйте его (Windows: .venv\Scripts\activate; macOS/Linux: source .venv/bin/activate).
- Обновите pip: выполните python -m pip install --upgrade pip.
- Установите базовые пакеты: pip install requests httpx pydantic python-dotenv.
- Если планируете Crawl4AI: pip install crawl4ai playwright; затем playwright install chromium.
- Создайте .env-файл: добавьте FIRECRAWL_API_KEY=... и JINA_READER_API_KEY=... если используете эти сервисы; добавьте PROXY_HOST, PROXY_PORT, PROXY_USER, PROXY_PASS.
- Создайте файл config.json с параметрами ротации: таймер в секундах, лимиты запросов на IP, retries и таймауты.
⚠️ Внимание: Не храните ключи API в репозиториях. Используйте .gitignore и менеджеры секретов. Утечка ключа может привести к списанию средств и блокировкам.
Совет: На сайте провайдера мобильных прокси часто есть бесплатные инструменты, например проверка IP, DNS Leak Test, Proxy Checker, калькулятор прокси и карта задержек. Используйте их до запуска, чтобы убедиться, что ваш IP действительно мобильный и отклик из нужного региона стабилен.
✅ Проверка: Все команды устанавливаются без ошибок, окружение активно, ключи и параметры прокси записаны в .env, базовые команды python -c "import requests, httpx" проходят без исключений.
Шаг 3: Понимаем роль мобильных прокси и ограничения дата-центр IP
Цель этапа: разобраться, почему мобильные прокси дают более высокий success rate и когда они критичны.
- Оцените антибот-факторы в 2026: сайты анализируют IP-репутацию, сигнатуры TLS, последовательность запросов, скорость, HTTP/2 приоритизацию, стабильность заголовков, поведение при редиректах и cookie-менеджмент.
- Дата-центр прокси массово присутствуют в репутационных списках: большое число жалоб, однотипный трафик, всплески активности с одних и тех же ASN. В результате фильтры часто требуют сложных дополнительных проверок и/или выдают блок-страницы.
- Мобильные IP принадлежат реальным операторам связи. За счет CGNAT десятки и сотни реальных пользователей «делят» видимый IP, а антибот-системы применяют щадящие правила, чтобы не ухудшить опыт людей.
- Разнообразие ASN и географий мобильных сетей повышает «похожесть» на реальный трафик и помогает избежать паттернов, характерных для дата-центров.
- Ротация мобильных IP по таймеру и по API позволяет быстро адаптировать стратегию при росте ошибок, снижая риск банов.
Совет: Планируйте ротацию каждые 5–20 минут под нагрузкой и 30–60 минут для медленного скрапинга. При резком росте 403/429 — ротируйте быстрее и уменьшайте частоту запросов.
✅ Проверка: Вы понимаете, зачем вам мобильные прокси и как они повышают success rate в вашей задаче. Вы готовы настроить ротацию и ретраи.
Шаг 4: Быстрый старт с Reader API (Jina)
Цель этапа: получить чистый текст и краткое резюме страницы через простую «читалку» и проверить работу через мобильный прокси.
- Создайте файл reader_quickstart.py в корне проекта.
- Добавьте код для запроса с прокси через httpx. Пример одной строкой: import os, httpx; from dotenv import load_dotenv; load_dotenv(); proxy=f"http://{os.getenv('PROXY_USER')}:{os.getenv('PROXY_PASS')}@{os.getenv('PROXY_HOST')}:{os.getenv('PROXY_PORT')}"; headers={"Authorization":f"Bearer {os.getenv('JINA_READER_API_KEY')}","Accept":"application/json"}; url="https://r.jina.ai/http://example.com"; with httpx.Client(proxies=proxy, timeout=60.0, http2=True) as c: r=c.get(url, headers=headers); print(r.text[:500])
- Замените example.com на реальную тестовую страницу со статьей или документом.
- Запустите файл: python reader_quickstart.py и убедитесь, что вы видите первые 500 символов извлеченного текста.
- Добавьте обработку ошибок и ретраи на 429/5xx. Используйте схему: попытка до 3 раз с экспоненциальной паузой 1–2–4 секунды, при ошибке 403 инициируйте смену IP (см. шаг о ротации ниже).
Совет: Для страниц с динамической подгрузкой Reader API часто уже готов возвращать итоговый собранный текст. Но если контент сильно зависит от интерактивных действий, планируйте Crawl4AI.
✅ Проверка: Получен стабильный текст от Reader API, задержка не превышает 2–5 секунд на страницу, коды ответа в логе в основном 200, при ретраях успех выше 90% на тестовом домене.
Шаг 5: Быстрый старт с Firecrawl
Цель этапа: запустить страницу или небольшой краул через Firecrawl, получить структурированный контент и проверить работу через мобильный прокси.
- Создайте файл firecrawl_quickstart.py.
- Добавьте код с requests через HTTP(S)-прокси. Одна строка: import os, requests, json; from dotenv import load_dotenv; load_dotenv(); proxies={"http":f"http://{os.getenv('PROXY_USER')}:{os.getenv('PROXY_PASS')}@{os.getenv('PROXY_HOST')}:{os.getenv('PROXY_PORT')}","https":f"http://{os.getenv('PROXY_USER')}:{os.getenv('PROXY_PASS')}@{os.getenv('PROXY_HOST')}:{os.getenv('PROXY_PORT')}"}; headers={"Authorization":f"Bearer {os.getenv('FIRECRAWL_API_KEY')}","Content-Type":"application/json"}; payload={"url":"https://example.com","format":"markdown","include_links":True}; r=requests.post("https://api.firecrawl.dev/v1/scrape", headers=headers, proxies=proxies, data=json.dumps(payload), timeout=90); print(r.status_code, str(r.text)[:600])
- Проверьте код ответа 200 и что в тексте есть нужные заголовки или абзацы из целевой страницы.
- Для многократных запусков добавьте ретраи и ограничение частоты запросов. Задайте паузу 2–5 секунд между запросами на один домен.
- Если у Firecrawl есть режим crawl по сайту, сформируйте список URL или стартовый URL и глубину прохода, убедитесь в корректной пагинации и ограничениях.
Совет: Используйте формат Markdown или JSON в ответе Firecrawl, чтобы сразу подавать результат в вашу LLM-постобработку или индекс. Это экономит шаги преобразования.
✅ Проверка: Вы получаете структурированный контент через Firecrawl, ключевые блоки страницы извлекаются и читаемы, прокси стабилен, success rate близок к целевому уровню.
Шаг 6: Быстрый старт с Crawl4AI
Цель этапа: развернуть локальный краул с рендерингом, подключить мобильный прокси и убедиться, что динамические страницы обрабатываются корректно.
- Создайте файл crawl4ai_quickstart.py.
- Если Crawl4AI предоставляет высокоуровневый интерфейс, используйте его. Пример псевдокода одной строкой с Playwright-прокси: import os, asyncio; from dotenv import load_dotenv; from crawl4ai import Crawler; load_dotenv(); proxy_server=f"http://{os.getenv('PROXY_HOST')}:{os.getenv('PROXY_PORT')}"; proxy_user=os.getenv('PROXY_USER'); proxy_pass=os.getenv('PROXY_PASS'); async def run(): c=Crawler(headless=True, timeout_ms=60000, proxy={"server":proxy_server,"username":proxy_user,"password":proxy_pass}); html, text = await c.get("https://example.com"); print(text[:600]); asyncio.run(run())
- Если в вашей версии Crawl4AI интерфейс отличается, используйте документацию пакета и параметры Playwright: proxy={"server":"http://host:port","username":"user","password":"pass"} при запуске браузера.
- Проверьте, что содержимое, отрисовываемое JavaScript, появляется в тексте. Сравните с тем, что видите в обычном браузере.
- Настройте ограничение частоты, таймауты и количество одновременных вкладок, чтобы не перегружать целевой сайт и ваш прокси.
Совет: Для сложных сайтов используйте стратегию «двух шагов»: сначала Reader API или Firecrawl для простых страниц, затем Crawl4AI для тех, что не удается извлечь без рендеринга.
✅ Проверка: Динамический контент извлекается. Запросы с мобильного прокси стабильны, ошибки 504/429 не накапливаются, при ретраях и ротации достигаете целевого уровня успеха.
Шаг 7: Подключаем ротацию мобильных прокси
Цель этапа: настроить смену IP по таймеру и по событию ошибки, чтобы удерживать высокий success rate.
- Определите стратегию ротации: по таймеру (каждые N минут) и по событию (429/403/5xx подряд).
- Если провайдер предоставляет API ротации, добавьте вызов в ваш код. Пример псевдокода одной строкой: import requests, os; rotate_url=os.getenv('PROXY_ROTATE_URL'); token=os.getenv('PROXY_API_TOKEN'); r=requests.post(rotate_url, headers={"Authorization":f"Bearer {token}"}, timeout=15); print(r.status_code)
- Добавьте счетчик неудач: при 3 последовательных ошибках 429/403 выполните немедленную ротацию и увеличьте паузу между запросами.
- Сделайте границы: не менять IP чаще, чем 1–2 минуты, если игрушечная нагрузка. Для пиковых нагрузок согласуйте с провайдером рекомендуемый интервал.
- Логируйте все ротации, запоминая время, причину и итоговый success rate после смены.
⚠️ Внимание: Чрезмерная ротация без пауз может вызывать подозрение из-за слишком быстрой смены ASN и гео-атрибутов. Соблюдайте естественные задержки.
Совет: Перед масштабированием прогоните пилот на 200–500 страниц, измерьте долю ошибок, подберите интервал ротации, затем масштабируйте на всю выборку.
✅ Проверка: Ротация срабатывает по таймеру и при ошибках, после смены IP success rate повышается, логи фиксируют причины и интервалы.
Шаг 8: Обработка ошибок, повторные попытки и защита бюджета
Цель этапа: внедрить предсказуемую стратегию ретраев и ограничений, чтобы держать стабильные расходы и скорость.
- Ретраи: используйте экспоненциальную задержку 1–2–4–8 секунд с максимумом до 3–4 попыток.
- Контроль частоты: ограничьте QPS до 0.2–1 запроса на домен для стартовых тестов. Постепенно увеличивайте, наблюдая коды ошибок.
- Особые коды: 429 — снизьте частоту и ротируйте IP; 403 — немедленная ротация IP и увеличьте задержки; 5xx — ретраи, возможно смена IP при 502/503/504.
- Таймауты: ставьте 60–90 секунд, в медленных регионах 120–180 секунд, но следите за бюджетом.
- Лимиты бюджета: добавьте счетчик успешных страниц и жесткий дневной лимит, чтобы не превысить планируемую сумму.
Совет: В логе храните домен, URL, код ответа, длительность, текущий IP, страну IP, количество ретраев, итоговый статус. Это упростит отладку.
✅ Проверка: Поведение на ошибках предсказуемо, расходы под контролем, доля успешных страниц растет после внедрения ограничений и ротации.
Шаг 9: Сравниваем Firecrawl, Reader API и Crawl4AI
Цель этапа: принять обоснованное решение для продакшена и сервировать разные типы страниц оптимальными инструментами.
- Firecrawl: плюсы — облачный краул, конвертация контента и форматирование, поддержка списков ссылок и, в некоторых планах, извлечение структурированных блоков; минусы — стоимость при больших объемах, зависимость от внешнего SLA.
- Reader API (Jina): плюсы — очень быстрый способ «прочитать» страницу в чистый текст или облегченный формат, простая интеграция; минусы — когда требуется сложное взаимодействие со страницей, может не хватать браузерного рендеринга.
- Crawl4AI: плюсы — полный контроль, рендеринг сложных сайтов, гибкая логика кликов и скриптов; минусы — нужно управлять инфраструктурой, следить за нагрузкой и расходами, тонко настраивать прокси.
- Цены 2026 (проверяйте актуальные на момент чтения): Firecrawl — базовый план для малых проектов около десятков долларов в месяц, Pro — около сотни-двух, Enterprise по запросу; Reader API — бесплатная квота и тарификация за страницу/токены в районе тысячных доллара; Crawl4AI — open-source, оплата за прокси, сервера и поддержку.
- Сценарии: быстрая очистка контента с множества доменов — Reader API; управляемый краул по сайтам — Firecrawl; сложные SPA, авторизация, клики — Crawl4AI. Часто используется комбинация: Reader API как первый проход, Firecrawl для автоматизации больших списков, Crawl4AI — для «тяжелых» страниц.
⚠️ Внимание: Не пытайтесь «универсалом» закрыть все случаи одним инструментом. Комбинация дает устойчивость и лучшую экономику.
Совет: Введите роутер задач: по метаданным URL определяйте, что отправлять в Reader API, что в Firecrawl, а что в Crawl4AI. Это уменьшит расходы.
✅ Проверка: У вас зафиксированы рекомендации по выбору инструмента, рассчитана ориентировочная стоимость и успех на пилоте подтвержден.
Проверка результата
Чек-лист: у вас запускается Python-окружение без ошибок; Reader API возвращает чистый текст на тестовых страницах через мобильный прокси; Firecrawl отдает 200 и структурированный контент; Crawl4AI рендерит динамику; ротация IP работает по таймеру и событиям; логи фиксируют ошибки, задержки и успех; бюджет не превышает план.
Как протестировать: возьмите выборку из 50–100 URL с разных доменов, замерьте успех и задержку по каждому инструменту, убедитесь, что суммарно success rate не ниже цели. Проверьте, что при 403/429 срабатывают ретраи и ротация, и после нее success rate восстанавливается.
Показатели успешного выполнения: success rate 80–95% и выше для Reader API и Firecrawl; для Crawl4AI — 70–90% на сложных страницах при разумной частоте; средняя задержка по странице в пределах 2–10 секунд для «читалок» и 5–20 секунд для рендеринга; бюджет в рамках плана.
Типичные ошибки и решения
- Проблема: массовые 429. Причина: слишком высокая частота. Решение: снизить QPS, включить ротацию, увеличить паузы между доменами.
- Проблема: 403 после 1–2 запросов. Причина: IP в списках или подозрительная последовательность. Решение: немедленная ротация, уменьшение частоты, корректировка заголовков и User-Agent.
- Проблема: таймауты 60–90 сек. Причина: перегруженный маршрут или медленный сайт. Решение: увеличить таймауты до 120–180 сек или сменить гео IP на ближнее к сайту.
- Проблема: текст пустой у «читалки». Причина: динамический рендеринг. Решение: применить Crawl4AI или включить альтернативный источник данных.
- Проблема: перерасход бюджета. Причина: безлимитные ретраи. Решение: ввести потолки попыток и дневной лимит на успешные страницы.
- Проблема: нестабильная ротация. Причина: слишком частая смена IP. Решение: увеличить интервал ротации и зафиксировать минимальную паузу между сменами.
- Проблема: разный контент в разное время. Причина: A/B или персонализация. Решение: сохранять HTML-снимки, фиксировать время и заголовки, учитывать вариации.
Дополнительные возможности
Продвинутые настройки: включите распределенную очередь задач и балансировку по доменам; используйте разные мобильные гео для региональных сайтов; сохраняйте «сырые» HTML и финальные тексты в отдельные хранилища для аудита; стройте дэшборд метрик.
Оптимизация: объединяйте запросы к близким доменам в пачки; адаптируйте таймауты по среднему времени ответа домена; внедрите интеллектуальный роутер: если Reader API не справился, отправляйте в Crawl4AI с рендерингом.
Что еще можно сделать: подключить пост-обработку LLM для резюме, классификации и извлечения сущностей; кешировать стабильные страницы; строить индексы поиска по извлеченному контенту.
FAQ
- Как понять, что мне хватит одного инструмента? Если ваш контент статичен и легко читается, часто достаточно Reader API. Для краулинга множества страниц — Firecrawl. Для динамики — Crawl4AI.
- Насколько часто менять IP? Для умеренной нагрузки каждые 10–30 минут. При росте 403/429 — ротируйте быстрее и снизьте частоту.
- Нужно ли сразу настраивать рендеринг? Нет. Сначала попытайтесь «прочитать» страницы. Подключайте рендеринг, если видите пустой или неполный текст.
- Почему дата-центр IP не подходят в 2026? Репутационные фильтры, антибот-паттерны и массовые флаги приводят к блокам. Мобильные IP чаще проходят из-за отличающихся признаков трафика.
- Можно ли смешивать HTTP(S) и SOCKS5? Да, многие клиенты поддерживают оба. SOCKS5 иногда дает лучшую стабильность при нестандартных потоках.
- Как снизить стоимость? Ограничьте глубину краула, исключите медиаресурсы, кэшируйте стабильные страницы, правильно настраивайте ретраи и ротацию.
- Что делать при флуктуациях качества? Логируйте все сигналы, сохраняйте примеры HTML, экспериментируйте с интервалами ротации и гео, используйте карту задержек провайдера.
- Как быстро проверить IP и DNS? Воспользуйтесь встроенными тестами провайдера: проверка IP, DNS Leak Test, Proxy Checker — это поможет до запуска.
- Можно ли использовать один прокси-пул на все инструменты? Да, если провайдер поддерживает одновременные протоколы и сессии. Важно контролировать частоту на домен.
- Чем хороши мобильные прокси для LLM-скрапинга? Более высокая репутация, реальный трафик операторов, гибкая ротация — все это повышает success rate и снижает потери на ретраи.
Заключение
Вы прошли полный цикл: спланировали цели, выбрали инструмент, настроили окружение, подключили мобильные прокси, запустили Reader API, Firecrawl и Crawl4AI, внедрили ротацию и ретраи, сравнили результаты и оценили бюджет. Дальше развивайте пайплайн: стройте очередь, масштабируйте гео, добавляйте пост-обработку LLM, автоматизируйте мониторинг метрик и журналов. В 2026 году устойчивый LLM-скрапинг — это грамотная комбинация инструментов и правильная прокси-стратегия. Для практики используйте инструменты вашего прокси-провайдера: проверку IP, DNS Leak Test, Proxy Checker, калькулятор прокси, карту задержек и генератор отпечатков браузера. При необходимости вы можете протестировать мобильные прокси с реальными SIM-картами операторов, одновременной поддержкой HTTP(S) и SOCKS5, гибкой ротацией по таймеру, API и ссылке, круглосуточной поддержкой и бесплатным тестированием в течение 3 часов. Выбирайте решения с обширным пулом IP и широким покрытием стран, чтобы добиться максимально высокого success rate. Если вы делаете первую покупку, используйте промокод YOUTUBE20 на скидку 20%.
