Introducing the Playwright library: everything, you need to know about it

Data parsing is effectively used today in various business areas. For Web Scraping, many tools are actively used. Now let's take a closer look at the Playwright library, its features and capabilities, advantages and disadvantages, and popular uses for collecting data from web pages. Let's make a brief comparison of this library and analogues. Let's also dwell on how to ensure efficiency, security and anonymity when parsing data using mobile proxies.
A brief introduction to the Playwright library
Playwright – a library built specifically for browser automation for Node.js. It is designed to provide fast, reliable and efficient data parsing using just a few year strings. Its parameters are quite similar to the Selenium and Puppeteer libraries. Users appreciated the simplicity and ease of use, advanced capabilities for automating data collection, as well as their intellectual analysis. One of the distinguishing features of this – support for so-called headless browsers. Also, the advantages of Playwright include cross-browser support.
Let's start our acquaintance with the new library with a few words about Headless browsers, because they are actively used today in web scraping. Among their distinctive features, it is worth highlighting:
- no graphical user interface;
- minimum resource requirements, fast and easy to run on the server;
- it is possible to create a large number of instances of such a browser at the same time, which will ensure efficient parsing of data from several web pages at once.
Today, more and more websites are built on the basis of – single-page application frameworks; SPA, in particular React.js, Angular, Vue.js, etc. If you access such sites using classic HTTP clients, then in the end you will get an empty HTML page, because it is built on the basis of external Javascript code. Headless browsers are designed to solve this problem and provide efficient web scraping. You can learn more about how the Headless browser works and works here.
Getting started with the Playwright library
Before proceeding directly to working with the Playwright library, you should familiarize yourself with its manual. Next, we try to write our own parser to collect certain data using this library. As an example, consider the option of collecting financial indicators. To do this, you need to follow a series of steps:
- Create a new Node.js project and install the Playwright library in it. To do this, it will be enough to execute only 2 commands: «nmp init –yes» and "npm i playwright".
- We form an index.js file and write the first lines of code. In the example, you can see an instance of the Headless browser. We want to draw your attention to the fact that we used false values in line 4. This will cause the user interface to pop up when the code is run. In the event that you decide to replace false with true, then the Playwright library will work in standalone mode. Following our instructions, we create a new page in the browser, and then go to Yahoo. Literally 5 seconds and close the browser:

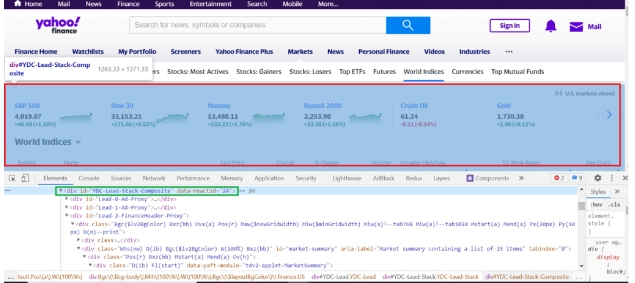
- Go to Yahoo from your browser. First of all, we check the home page for presence on Yahoo.Finance. As an example, consider creating a financial application for which you need to have a sufficient amount of data from the stock markets. Directly from Yahoo's homepage, we can see that the market summary has appeared in the header. Now we need to inspect the DOM node and the header element in the browser inspector. How to do this can be seen in the picture:
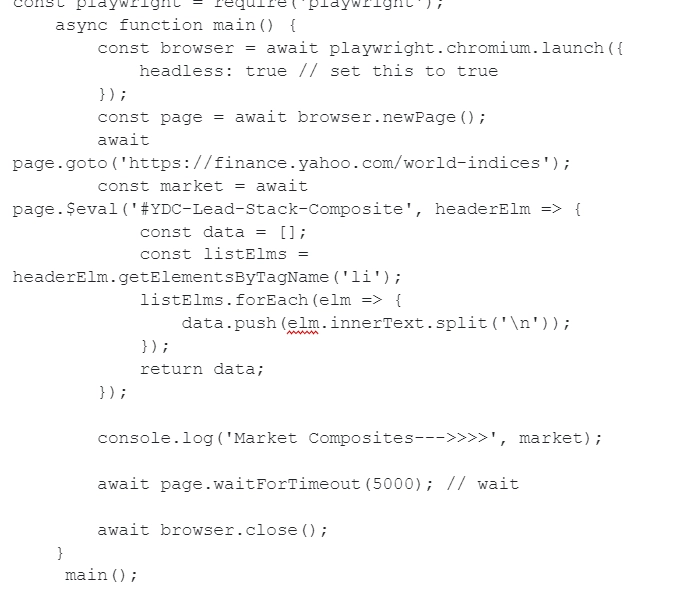
- If you noticed, the header has the extension id=YDC-Lead-Stack-Composite. You can directly target this identifier to extract the necessary data from it. To implement this idea, you need to insert the following lines directly into the code:
- Notice the $eval function. It requires two parameters, specifically a selector ID and an anonymous function. In the script that we are considering, the node ID is passed, which we plan to extract. Using an anonymous function, you can run any client code that is available for use in the browser:
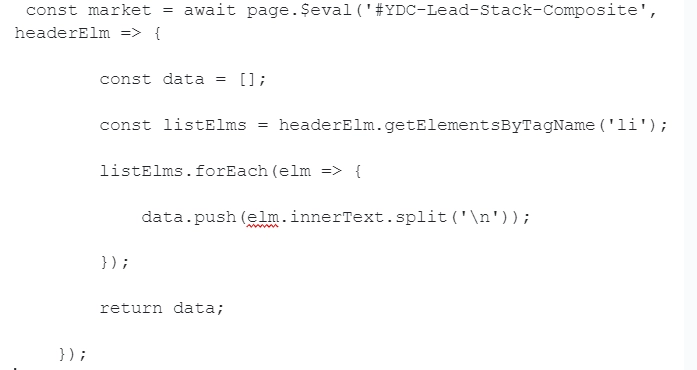
- In the example, we're looking at simple client-side JS code that can capture li elements in a header node. This code is able to output the following data to the terminal:


Everything. This completes the collection of the first data. But the work with the Playwright library does not end there. Now let's move on to how to extract lists of elements, pictures, and take screenshots with it.
Retrieving a list of elements from a table using Playwright
Now, with an example, let's look at how to retrieve a list of elements from a table. We continue our financial theme and set ourselves the task of getting the most popular stocks from this page.
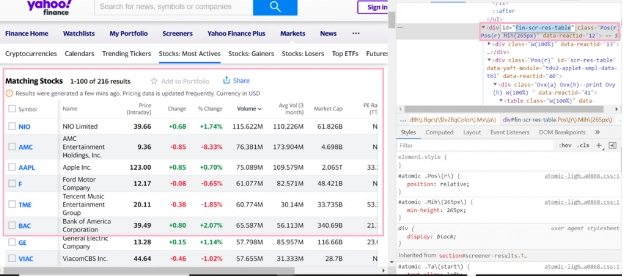
In this case, we are interested in the identifier in the fin-scr-res-table attribute. Optionally, you can also expand the search in the DOM node to a table element. The picture shows an example of solving this problem:
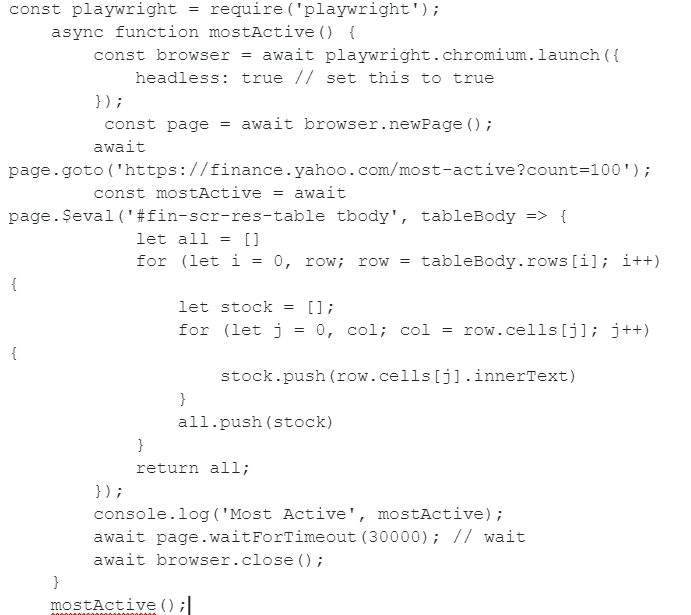
We want to draw your attention to the fact that here page.$eval works like a client-side JavaScript querySelector. If you are faced with the task of extracting tags of a certain type, then you need to use the page.$$(selector) function. This will allow you to return all elements that match a particular selector on your page of choice:

Extract images with Playwright
In order to retrieve images, we initially need to focus on the DOM node dedicated to capturing images. To achieve the desired result, we need the src function. We form an HTTP GET request to the source and load the image. The picture shows how to implement it in practice.

That is, we initially pay attention to the DOM node that we are interested in, and then on line 11 we specify the src attribute directly from the image tag. Then we form a GET request using axios, and only then we save the image.
Generating screenshots with Playwright
Another feature of the Playwright library – generation of screenshots of the page. The service implements the page.screenshot method, with which you can take any number of screenshots of a web page.

If you want to limit the snapshot to only part of the screen, then you need to set the coordinates of the viewport. You can put it into practice like this:

We would like to draw your attention to the fact that the starting point for the X and Y coordinates will be the upper left corner of the screen.
How to build queries using XPath expression selectors
Querying DOM elements using XPath expressions – this is a powerful yet simple function of the Playwright library. XPath refers to a special pattern designed to form a set of nodes in the DOM.
Let's take one of the blogs as an example and try to get all the navigation links from it. Here we will be extracting the nav element into the DOM. Use the following hierarchy html > body > div > header > nav to find the navigation element we are interested in in the tree:
After that, we form an XPath expression:

In the picture you see the script that XPath will use to extract the nav elements into the DOM.
Submit forms and retrieve authenticated routes
This example is relevant for cases when you are faced with the task of parsing data from web pages protected by authentication. Playwright makes it quick and easy to submit the appropriate form. How to do this is shown in the picture:

Moreover, the Playwright library makes it easy to fire fill events and simulate clicks. The result of executing this script is shown in the picture:
A brief comparison of the Playwright library with Selenium and Puppeteer
Along with Playwright, there are a number of other data parsing libraries. The most popular solutions today – these are Selenium and Puppeteer. And the first thing that distinguishes Playwright from analogues – increased convenience in work for specialists. No wonder this library is in consistently high demand among programmers today. Here are a few highlights we would like to draw your attention to:
- Documentation. Excellent supporting documentation is available in the Playwright and Puppeteer libraries. Selenium also has it, but improvements would not be superfluous.
- Performance. If you run the same script in each of the libraries, then Selenium will run the slowest. If you conduct special performance tests, then most of them will have better results in Playwright than in Puppeteer.
- Community. Today Playwright has a small but active community, which allows you to quickly find professional solutions to a problem that has arisen. Both Puppeteer and Selenium have a fairly large community with active projects.
According to experts working with these libraries, Playwright and Puppeteer deserve the highest ratings. Selenium is rated as a good enough service. All this allows us to conclude that Playwright – this is a fairly powerful, standalone tool, which is at the stage of active development. This library will be a great option for web scraping, especially for those who already have some experience with Node.js.
But what about the safety of working on the Internet?
In any case, regardless of which library you plan to work with, parsing – these are multi-threaded activities that can cause backlash from search engines when making multiple requests from the same IP-address. Anti-fraud systems will simply block your access. To avoid this, we recommend additionally connecting mobile proxies to work, in particular, from the MobileProxy.Space service. In this case you get:
- high speed of interaction with the Internet, which is ensured by the use of the technical capabilities of mobile network operators and data caching;
- absolute confidentiality and security of work on the Internet, protection from any unauthorized access;
- Effectively bypass regional blocking and gain access to sites from any country in the world;
- stability in multi-threaded mode, including using automated software.
To learn more about the features and capabilities of mobile proxies from MobileProxy.Space, we recommend that you follow the link https://mobileproxy.space/ user.html?buyproxy. Among the highlights, I would like to highlight the provision to each user of a personal channel with unlimited traffic, the ability to configure automatic or forced change of IP-addresses, simultaneous work using HTTP (S) and Socks5 protocols. There is also a large selection of geolocations and cellular network operators for them, which can be changed directly in the workflow. The service also offers round-the-clock technical support, which allows you to quickly and professionally solve problems.