Cómo construir el núcleo semántico de los competidores por regiones utilizando proxies móviles: guía paso a paso
Contenido del artículo
- Introducción
- Preparación previa
- Conceptos básicos
- Paso 1: definimos consultas objetivo y lista de regiones
- Paso 2: configuramos proxies móviles por ciudades y confirmamos geo
- Paso 3: preparamos el entorno de python y la estructura del proyecto
- Paso 4: recopilamos la lista de competidores directos por cada región
- Paso 5: scrapeamos los 50 principales resultados por consultas y ciudades (google y yandex)
- Paso 6: limpieza, normalización y extracción de dominios
- Paso 7: clustering de la semántica recopilada según intenciones
- Paso 8: unir datos y preparar cortes analíticos
- Paso 9: análisis de las diferencias en los resultados por regiones y localización de consultas
- Verificación del resultado
- Errores típicos y soluciones
- Oportunidades adicionales
- Faq
- Conclusión
Introducción
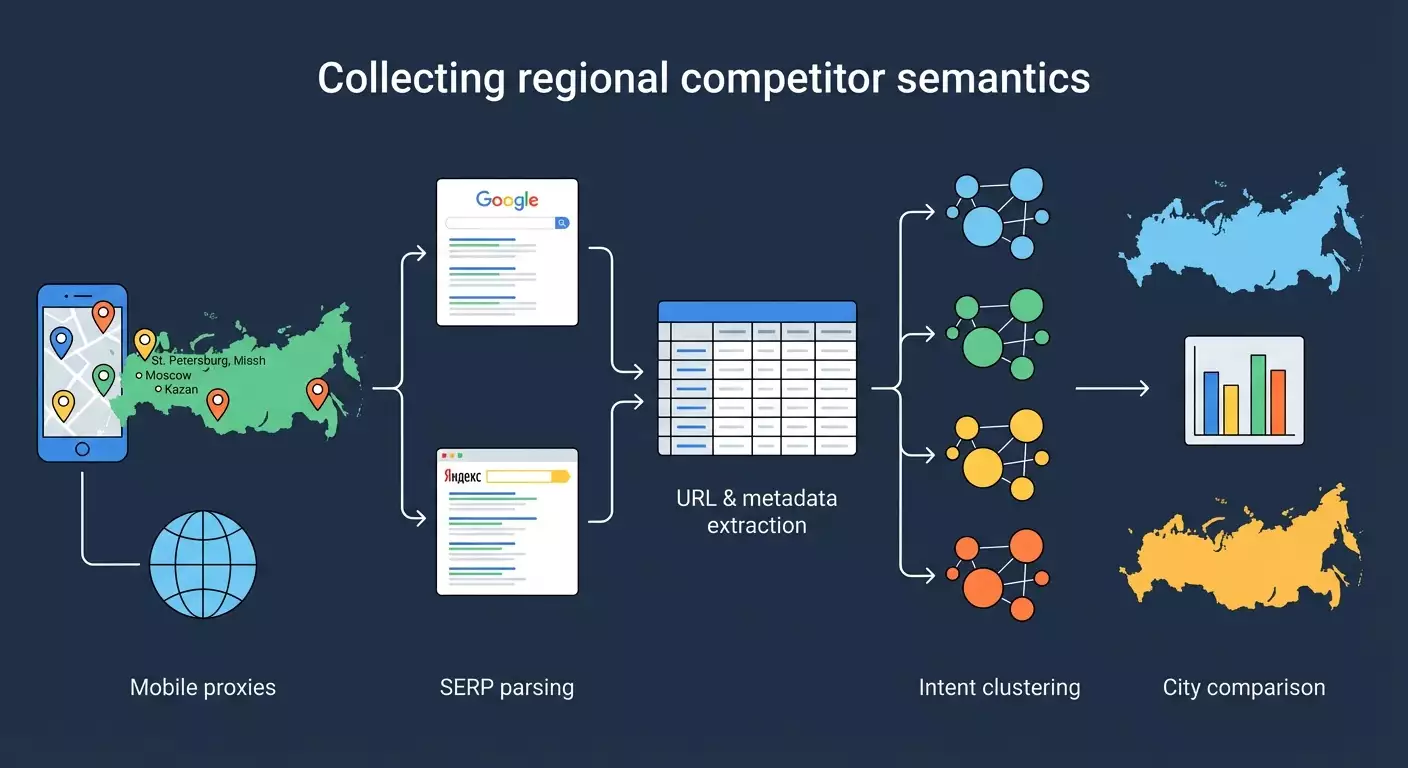
En esta guía paso a paso aprenderás a recopilar el núcleo semántico de los competidores en diferentes regiones de América Latina utilizando proxies móviles, scraping de los resultados de búsqueda de Google y Yandex, así como herramientas para agrupar y analizar. Recorreremos todo el proceso desde cero: preparación del entorno, configuración de proxies por ciudad, scraping de los 50 principales resultados por consultas objetivo, extracción de URL, título, descripción, posiciones, clustering de la semántica recopilada por intenciones (informativa, comercial, navegacional), comparación de resultados por regiones y preparación de un informe práctico para decisiones de SEO.
Al final, obtendrás: 1) lista de competidores por cada ciudad, 2) tabla de palabras clave por las que los competidores están clasificados en diferentes regiones, 3) métricas sobre las diferencias en los resultados regionales y localización de consultas, 4) clústeres agrupados de intenciones para ahorrar presupuesto y priorizar contenido, 5) un proceso repetible que se puede ejecutar mensualmente.
Esta guía es adecuada para especialistas en SEO, mercadólogos digitales, analistas, y para cualquiera que quiera entender cómo funciona la entrega regional y cómo extraer rápidamente datos útiles para la toma de decisiones. El nivel de dificultad es para principiantes con elementos para avanzados. No requeriremos habilidades profundas de programación, pero se agradecerá un conocimiento mínimo de Python.
Lo que necesitas saber de antemano: comprensión básica de SEO, cómo se forman los snippets, las diferencias entre consultas informativas y comerciales, cómo trabajar con CSV/Excel. ¿Cuánto tiempo se requiere? Con consultas y listas de ciudades listas: 6-10 horas para la primera ejecución, 1-3 horas para iteraciones posteriores.
✅ Verificación: Entiendes que recibirás una lista concreta de competidores por ciudades, semántica general y única, así como podrás explicar qué consultas están localizadas y cómo utilizarlas en SEO regional.
Preparación previa
Herramientas necesarias: 1) Cuenta y acceso a proxies móviles en mobileproxy.space para las ciudades de América Latina (Ciudad de México, Bogotá, Buenos Aires, Santiago, Lima y otros según tu tarea). 2) Python 3.10+ y gestor de paquetes pip. 3) Bibliotecas de Python: requests, beautifulsoup4, lxml, pandas, urllib3, tldextract (para extraer dominios). 4) Editor de texto (VS Code o similar). 5) Editor de hojas de cálculo (Excel, Google Sheets o LibreOffice Calc). 6) Key Collector en Windows para agrupar y clúster consultas. 7) Terminal o línea de comandos. 8) Opcional: curl para pruebas rápidas de proxies. 9) Acceso a un navegador para verificar geolocalización a través de Yandex.Internetometer (sitio de Yandex para comprobar IP-geolocalización).
Requisitos del sistema: Windows 10/11 o macOS 12+ o Linux (Ubuntu 22.04+), al menos 8 GB de RAM, internet estable de 10 Mbps+, espacio libre en disco de 2–5 GB para datos y logs.
Lo que necesitas instalar: 1) Instala Python de la última versión estable. 2) Instala Key Collector en Windows. 3) Crea una cuenta en mobileproxy.space, recarga el balance y compra proxies para las ciudades necesarias (1 proxy por ciudad, mejor 2-3 para distribuir la carga). 4) Instala las bibliotecas: en la terminal ejecuta: pip install requests beautifulsoup4 lxml pandas urllib3 tldextract. 5) Configura el editor de texto y la terminal.
Creación de copias de seguridad: crea una carpeta de proyecto con subcarpetas data/raw, data/clean, reports, config, logs y copia periódicamente archivos CSV en una carpeta de respaldo o en la nube.
⚠️ Atención: Asegúrate de que tus acciones cumplan con la legislación y las reglas de los servicios. Algunos motores de búsqueda limitan la recolección automatizada de datos. Usa un límite razonable de solicitudes, revisa robots.txt, sigue las reglas y considera las API oficiales como método preferido.
Consejo: Crea un entorno virtual de Python (python -m venv .venv y luego actívalo) y fija las dependencias en requirements.txt para facilitar la portabilidad del proyecto.
✅ Verificación: En la terminal, los comandos python --version y pip --version funcionan, las bibliotecas están instaladas sin errores, tienes acceso a al menos un proxy para la Ciudad de México, y puedes abrir Yandex.Internetometer en el navegador.
Conceptos básicos
Términos clave en lenguaje sencillo: 1) Núcleo semántico — lista de consultas de búsqueda por las que deseas clasificarse o analizar a los competidores. 2) Resultados regionales — resultados de búsqueda formados considerando la ubicación del usuario (ciudad, región). 3) Proxies móviles — servidores proxy basados en operadores móviles que permiten simular tráfico de IPs móviles reales y, lo más importante para nuestro caso, elegir ciudad. 4) Parsing SERP — extracción de datos de la página de resultados de búsqueda (URL, título, snippet, posición). 5) Intención — el objetivo presumido del usuario: informativa (saber), comercial (comprar/ordenar), navegacional (encontrar un sitio específico). 6) Top-50 — los primeros 50 resultados orgánicos, sin publicidad.
Principios básicos de funcionamiento: enviamos una consulta al motor de búsqueda, indicamos proxies para fijar la geo, obtenemos una página HTML, extraemos los elementos necesarios, los guardamos en una tabla. Repetimos para cada ciudad y cada consulta. Luego agrupamos y analizamos.
Lo que es importante entender: 1) En diferentes ciudades, el conjunto de dominios y páginas en el top puede variar. 2) Las consultas localizadas suelen contener nombres de ciudades o implicar intenciones locales (por ejemplo, entrega, cerca, dirección). 3) Consultas demasiado frecuentes sin pausas pueden provocar captchas o bloqueos. 4) La verificación correcta de la ubicación es crítica. 5) Algunos resultados pueden estar personalizados; usa sesiones limpias, sin autenticación.
Consejo: Al analizar, no te limites solo a palabras clave, sino considera también los dominios de los competidores y el tipo de contenido, para elegir la estrategia correcta (páginas locales, catálogos, artículos, landing pages).
Paso 1: Definimos consultas objetivo y lista de regiones
Objetivo de la etapa
Formar una lista inicial de consultas y un listado de ciudades de las cuales recopilaremos resultados. Esto es la base para el scraping y comparación.
Instrucciones paso a paso
- Abre una hoja de cálculo (Excel o Google Sheets) y crea una hoja llamada Seeds.
- En la columna A enumera las consultas básicas que reflejan tu producto o nicho. Por ejemplo: “entrega de agua”, “reparación de laptops”, “comprar muebles”, etc.
- En la columna B añade aclaraciones o sinónimos, si son relevantes. Por ejemplo: “agua potable”, “reparación de MacBook”, “armario ropero”.
- Crea una hoja llamada Cities. En la columna A enumera las ciudades: Ciudad de México, Bogotá, Buenos Aires, Santiago, Lima, Quito y otras regiones objetivo.
- Define prioridades: selecciona 10-15 ciudades clave con mayor demanda.
- Forma la lista de consultas objetivo, combinando las básicas y las aclaraciones. Por ejemplo: “entrega de agua”, “entrega de agua a domicilio”, “entrega de agua potable”, “reparación de laptops”, “reparación urgente de laptops”.
- Guarda la hoja en la carpeta data/raw como seeds_and_cities.xlsx.
Puntos importantes: No incluyas por ahora nombres de ciudades en las consultas, para evaluar la localización sin una geo clara. Lo verificarás más tarde con modificadores geográficos.
Consejo: Limita la lista a 50-200 consultas para la primera ejecución, para no sobrecargar los proxies y no perder tiempo innecesario.
✅ Verificación: Tienes un archivo con 50-200 consultas y 10-15 ciudades. Las consultas son comprensibles y se alinean con los objetivos comerciales.
Posibles problemas y soluciones: si tienes dificultades para formar la lista, toma datos de las sugerencias de búsqueda internas de tu sitio, chats con clientes, lista de servicios y categorías de productos. Luego amplía con sugerencias de búsqueda manualmente.
Paso 2: Configuramos proxies móviles por ciudades y confirmamos geo
Objetivo de la etapa
Conectar proxies móviles de mobileproxy.space para cada ciudad, verificar que la IP realmente corresponde a la ciudad deseada a través de Yandex.Internetometer.
Instrucciones paso a paso
- Ingresa a tu cuenta en mobileproxy.space. Elige un plan que permita seleccionar ciudad y operador. Toma al menos un proxy por cada ciudad de tu lista. La opción óptima es tener 2-3 proxies por ciudad.
- Registra para cada proxy: host, puerto, usuario y contraseña. Por ejemplo: proxy.ejemplo.host:12345, usuario:contraseña.
- Si se admite rotación por enlace o API, guarda el enlace para cambiar IP. Esto será útil para restablecer sesiones al encontrar un captcha.
- Crea un archivo config/proxies.csv con columnas ciudad, host, puerto, usuario, contraseña, rotation_url (si está disponible) y complétalo.
- Abre un navegador, activa el proxy del sistema o del navegador para la Ciudad de México e ingresa al servicio de verificación de IP y geolocalización de Yandex (Yandex.Internetometer). Asegúrate de que la ciudad se determina como Ciudad de México.
- Repite la verificación para Bogotá, Buenos Aires y otras ciudades, cambiando la configuración del proxy.
- Quita el proxy en el navegador. En adelante, haremos la verificación geo de forma programática.
⚠️ Atención: Usa los proxies solo de acuerdo a las condiciones del servicio y la ley. El objetivo del proxy es fijar correctamente la geo y distribuir la carga de manera uniforme, no eludir restricciones.
Consejo: Crea un pequeño tiempo de espera: después de cambiar el proxy, espera de 10 a 20 segundos antes de verificar la geo, para evitar el 'cache' o latencias en la red.
✅ Verificación: Para cada ciudad puedes activar el proxy correspondiente y ver la ciudad correcta en Yandex.Internetometer.
Problemas y soluciones: si la ciudad se determina incorrectamente, cambia la IP mediante la rotación, toma otro operador en la misma ciudad o contacta soporte. Si el navegador ignora el proxy, revisa la configuración y la autenticación.
Paso 3: Preparamos el entorno de Python y la estructura del proyecto
Objetivo de la etapa
Crear un entorno estable para scraping y análisis: estructura de carpetas, dependencias, prueba de conexión a través de proxies.
Instrucciones paso a paso
- Crea una carpeta para el proyecto, por ejemplo regional-serp-competitors.
- Dentro de esta carpeta, crea subcarpetas: config, data/raw, data/clean, logs, reports, scripts.
- Crea un entorno virtual: en la terminal ejecuta “python -m venv .venv” y actívalo (Windows: “.venv\Scripts\activate”, macOS/Linux: “source .venv/bin/activate”).
- Instala las dependencias: “pip install requests beautifulsoup4 lxml pandas urllib3 tldextract”.
- Crea un archivo config/settings.yaml. Agrega los parámetros básicos: timeouts, delays (por ejemplo delay_min: 3, delay_max: 8), máximas intenciones de reintentos (retries: 3), user-agent.
- Crea un script scripts/test_proxy_geo.py que cargará la página de Yandex.Internetometer a través de uno de los proxies y mostrará la ciudad determinada en el HTML.
- Configura el proxy en el script como un diccionario del formato: {"http": "http://usuario:contraseña@host:puerto", "https": "http://usuario:contraseña@host:puerto"} y realiza una solicitud requests.get a la página de verificación IP, luego encuentra en el HTML el nodo correspondiente a la ciudad (por el texto “Ciudad” o algún elemento similar).
- Ejecuta el script para varias ciudades y asegúrate de que la salida coincide con lo esperado.
Consejo: Establece un User-Agent unificado, por ejemplo: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0 Safari/537.36”, y si es necesario, cámbialo cada 20-50 solicitudes.
✅ Verificación: El script test_proxy_geo.py muestra correctamente diferentes ciudades al cambiar el proxy. En los logs no hay constantes timeouts y errores de autenticación.
Problemas y soluciones: si 'requests' recibe 407 Proxy Authentication Required, revisa el nombre de usuario y la contraseña, y la escape de caracteres. Si recibes un captcha, aumenta la latencia e incluye la rotación de IP con menos frecuencia y de manera más gradual.
Paso 4: Recopilamos la lista de competidores directos por cada región
Objetivo de la etapa
Identificar los dominios de competidores en cada ciudad, para luego rastrear su ranking y recopilar semántica.
Instrucciones paso a paso
- Selecciona 5-10 consultas clave de tu lista que reflejen con precisión el servicio o producto objetivo sin aclaraciones geográficas.
- Crea un script scripts/collect_competitors.py. Para cada ciudad, toma el proxy correspondiente. Para cada una de las consultas elegidas, envía búsquedas en Yandex y Google de forma secuencial.
- Para Yandex, usa parámetros de consulta que consideren el idioma y la región. Por ejemplo, añade lr (código de región), si lo conoces; de lo contrario, confía en el proxy geo.
- Para Google, especifica los parámetros hl=es, gl=es. La geo se determinará por IP; adicionalmente, puedes formular parámetros seguros de búsqueda.
- Extrae los primeros 20-30 resultados orgánicos. Omite bloques publicitarios, servicios y widgets, si no son relevantes para los objetivos.
- Normaliza los dominios usando tldextract. Guarda para cada ciudad la frecuencia de dominios: dominio, cuántas veces aparece en el top, por qué consultas.
- Forma una tabla data/raw/competitors_by_city.csv con las columnas ciudad, dominio, motor, frecuencia, consultas.
Puntos importantes: Los servicios personales (mapas, marketplaces) pueden dominar. Déjalos, si son competidores reales en los resultados. Si eres B2B, filtra agregadores de noticias.
Consejo: Realiza una “verificación manual” adicional para 1-2 consultas en cada ciudad, en tu navegador bajo el proxy correspondiente, y compara los dominios con los resultados del script. Esto aumentará la confianza en la precisión del scraping.
✅ Verificación: Para cada ciudad hay una lista de 10-30 dominios con la frecuencia especificada. En el top hay sitios locales y actores nacionales. Los datos del script son cercanos a la verificación manual.
Problemas y soluciones: las discrepancias con la verificación manual pueden deberse a la dinámica de los resultados, personalización o filtrado incorrecto de bloques publicitarios. Aumenta la latencia, utiliza una sesión limpia y verifica adicionalmente.
Paso 5: Scrapeamos los 50 principales resultados por consultas y ciudades (Google y Yandex)
Objetivo de la etapa
Recopilar una tabla detallada de resultados: URL, título, descripción, posición, motor de búsqueda, ciudad, consulta.
Instrucciones paso a paso
- Crea un script scripts/serp_scraper.py. Estructura: funciones para realizar consultas a Yandex y Google, función para parsear HTML, guardar filas en CSV.
- Haz un archivo de configuración con los parámetros: número de resultados per_city_per_query_limit: 50, latencias delay_min, delay_max, máximos reintentos retries: 3, lista de cadenas User-Agent.
- Formar URL de búsqueda. Ejemplo en Google: “https://www.google.com/search?q=consulta&num=50&hl=es&gl=es&pws=0”. Ejemplo en Yandex: “https://yandex.ru/search/?text=consulta&lr=código_región&numdoc=50”, si lr es desconocido, confía en el IP-geo.
- Establece proxies por ciudad. Diccionario de proxy: {"http": "http://usuario:contraseña@host:puerto", "https": "http://usuario:contraseña@host:puerto"}.
- Solicita la página con un timeout de 20-30 segundos. Maneja errores: timeout, 429, 5xx. En caso de errores, haz una pausa de 30-60 segundos y repite con el mismo proxy.
- Scraping Google: encuentra contenedores de resultados: bloques con etiquetas h3 para títulos y enlaces, snippets en div/span adyacentes. Excluye enlaces a caché, imágenes, videos, anuncios. Si la estructura es diferente, usa todos los “a” con un título visible dentro del bloque de resultados y filtra por dominios.
- Scraping Yandex: busca tarjetas orgánicas de resultados. Extrae “a” con el enlace al resultado, título, texto sugerido. Excluye widgets (mapas, directorio) si no se analizan; de lo contrario, márcalos como type=feature.
- Número las posiciones del 1 al 50 en el orden que aparecen los resultados. Para resultados de Yandex y Google, la posición se considera entre tarjetas orgánicas.
- Guarda las filas con las columnas: motor, ciudad, consulta, posición, url, título, snippet, fetched_at (fecha/hora), proxy_id.
- Ejecuta la recopilación por ciudades de forma secuencial. Para cada ciudad itera sobre todas las consultas. Entre consultas, haz una pausa de 3-8 segundos; entre ciudades, 10-20 segundos.
- Guarda los datos en data/raw/serp_results.csv. Duplica cada hora una copia con el prefijo de fecha en la carpeta de respaldo.
⚠️ Atención: Algunos motores de búsqueda no permiten la recolección automatizada. Considera la API oficial (por ejemplo, Google Custom Search API) o servicios especializados. Si aún así scrapeas HTML, hazlo de manera cuidadosa y mínima, solo con fines analíticos y respetando los límites.
Consejo: Distribuye el scraping en la mañana temprano o tarde en la noche, cuando la carga es menor. Pausas aleatorias y alternar User-Agent reducen la probabilidad de captchas.
✅ Verificación: En el CSV final debe haber registros para cada ciudad y consulta, con 50 resultados en combinaciones. Los campos están completos, las URL son correctas, las posiciones siguen un orden.
Problemas y soluciones: si llegas a captchas, aumenta las pausas, reduce las solicitudes simultáneas, utiliza la rotación de IP con menor frecuencia, no más de 2-5 minutos. Si la estructura HTML ha cambiado, actualiza selectores y acelera la verificación manual en 2-3 consultas.
Paso 6: Limpieza, normalización y extracción de dominios
Objetivo de la etapa
Preparar los datos para análisis: eliminar ruido, normalizar URL, extraer dominios, eliminar elementos irrelevantes.
Instrucciones paso a paso
- Carga el CSV en pandas (script scripts/clean_results.py). Verifica la existencia de títulos/snippets vacíos y, si es necesario, recupéralos de nodos HTML alternativos.
- Filtra duplicados de filas por (motor, ciudad, consulta, url). Mantén la primera aparición.
- Excluye enlaces internos de motores de búsqueda, redirecciones a cachés, enlaces a mapas o noticias, si no son necesarios. Añade la bandera type=organic para resultados orgánicos limpios.
- Normaliza URL: elimina anclajes, ajusta esquema a https, quita parámetros de seguimiento (utm_*, gclid, etc.). Guarda la URL limpia en una columna separada clean_url.
- Con tldextract, obtén el dominio de segundo nivel y la zona. Guarda en una columna root_domain, por ejemplo, “site.ru”.
- Guarda el archivo limpio en data/clean/serp_results_clean.csv.
Consejo: Agrega desde el inicio la columna is_local_feature para resultados tipo mapa/directorio/marketplace, para separar rápidamente en el análisis de páginas normales.
✅ Verificación: El número de filas ha disminuido debido a la eliminación de duplicados y ruido, y los dominios se han extraído correctamente, sin enlaces de servicio. Puedes contar dominios únicos root_domain por ciudad y consulta.
Problemas y soluciones: si hay demasiados resultados marcados como ruido, revisa los filtros y especifica las reglas. A veces, es útil dejar grandes agregadores para completar la imagen.
Paso 7: Clustering de la semántica recopilada según intenciones
Objetivo de la etapa
Dividir frases clave en grupos según intenciones y clústeres temáticos, para entender qué tipo de contenido y páginas son necesarios para el posicionamiento regional.
Instrucciones paso a paso
- Forma una lista de consultas únicas de los datos de scraping: toma la columna consulta y elimina duplicados. Guarda en data/clean/unique_queries.csv.
- Abre Key Collector en Windows y crea un nuevo proyecto: Archivo → Nuevo proyecto. Asigna un nombre al proyecto, por ejemplo “Competidores SERP Regionales”.
- Importa la lista de consultas: menú Importar → Desde archivo → selecciona unique_queries.csv. Asegúrate de que la codificación sea UTF-8.
- Crea grupos por temas. En Key Collector usa la herramienta de clustering por morfología o por palabras comunes. Comienza con umbrales moderados de similitud (por ejemplo, 3 términos comunes) y luego ajusta manualmente los grupos.
- Marca cada grupo por intención: informativa, comercial, navegacional. Para esto puedes crear un campo personalizado. Ejemplos: informativa – “cómo elegir”, “qué es”; comercial – “precio”, “comprar”, “pedir”; navegacional – “marca”, “sitio oficial”.
- Exporta el resultado en CSV con columnas: consulta, clúster, intencionalidad. Guarda en data/clean/queries_clustered.csv.
Consejo: Si no tienes Key Collector, realiza una heurística simple en pandas: crea una lista de tokens para cada intención y clasifica la consulta según la presencia de estas palabras. Luego revisa manualmente casos discutibles.
✅ Verificación: Cada consulta tiene un clúster e intención. La mayoría de las consultas comerciales están agrupadas lógicamente, las informativas están separadas de las transaccionales.
Problemas y soluciones: si los grupos son demasiado amplios, baja los umbrales de similitud. Si son demasiado estrechos, aumenta los umbrales o fusiona manualmente. En temas complejos, un enfoque híbrido es útil: clustering automático inicial + ajuste manual.
Paso 8: Unir datos y preparar cortes analíticos
Objetivo de la etapa
Unir resultados SERP con clustering, calcular métricas útiles para análisis comparativo entre regiones y dominios competidores.
Instrucciones paso a paso
- Carga data/clean/serp_results_clean.csv y data/clean/queries_clustered.csv en pandas (script scripts/analyze_regions.py).
- Realiza un merge por la columna consulta, para que cada resultado obtenga clúster e intención.
- Agrega el cálculo de la posición de dominio: para cada combinación ciudad + consulta, crea un ranking. Esto ya está en posición, asegúrate de su corrección.
- Calcula la cuota de dominios por clúster: agrupando por ciudad, clúster, root_domain, y la métrica de posición media y cuota en el top-10.
- Agrega la bandera top-10: posición ≤ 10. Calcula la cobertura del dominio en el top-10 por clústeres e intenciones.
- Guarda tablas intermedias en data/clean/analytics_*.csv: por ejemplo, coverage_by_city_domain.csv, top10_share_by_intent.csv.
Consejo: En el informe, es conveniente mostrar “mapas de calor” de cobertura: ciudades en horizontal, dominios en vertical, color — proporción de consultas en el top-10. Esto revela actores fuertes en las regiones.
✅ Verificación: Las tablas se crean sin errores, con cifras comprensibles: los jugadores locales tienen una mayor cuota en el top-10 en sus ciudades, mientras que los federales tienen una cuota estable en varias ciudades.
Problemas y soluciones: si hay pocas entradas en el top-50, verifica la corrección del scraping y filtros. Ampliar la lista de consultas o aumentar los resultados a 100, si es seguro y permitido.
Paso 9: Análisis de las diferencias en los resultados por regiones y localización de consultas
Objetivo de la etapa
Definir qué consultas están localizadas, cuáles no, y cómo esto afecta la estrategia de SEO en diferentes ciudades. Identificar clústeres y dominios con fuerte localización.
Instrucciones paso a paso
- Para cada consulta, recopila conjuntos de dominios en el top-10 por ciudades. Calcula la intersección entre ciudades (por ejemplo, Ciudad de México vs Bogotá). Métrica: Jaccard = |intersección| / |unión|.
- Construye una tabla pivotante de Jaccard para todas las parejas de ciudades. Valores bajos indican una fuerte dependencia regional de los resultados.
- Identifica las consultas localizadas: aquellas con un Jaccard promedio por todas las parejas de ciudades por debajo de un umbral (por ejemplo, 0.3). Para las no localizadas — umbral por encima (por ejemplo, 0.6).
- Compara intenciones: generalmente, las consultas comerciales están más localizadas que las informativas. Verifícalo por los promedios de Jaccard dentro de cada intención.
- Identifica competidores “únicos” por ciudad: dominios que solo aparecen en el top-10 en una ciudad. Prepara una lista para enlaces locales y asociaciones.
- Genera un informe: 1) Top de consultas localizadas, 2) Top de consultas no localizadas, 3) Dominios únicos de la ciudad, 4) Dominios que son consistentemente fuertes en varias ciudades.
- Guarda el informe en reports/regional_differences.csv y crea un resumen textual con recomendaciones.
Consejo: Agrega la métrica “estabilidad de posición” para el dominio: promedio y desviación estándar de la posición por ciudades. Esto ayudará a entender dónde el dominio es más fuerte.
✅ Verificación: En los informes se puede ver que algunas consultas varían notablemente entre ciudades, mientras que otras prácticamente no cambian. Puedes nombrar al menos 5 consultas localizadas y 5 no localizadas de tu muestra.
Problemas y soluciones: si la diferencia es mínima, puede que el tema dependa poco de la región o que la muestra sea demasiado estrecha. Agrega consultas con intención local (como “cerca”, “entrega hoy”, “en mi ciudad”) y repite el análisis.
Verificación del resultado
Lista de verificación: 1) Tienes proxies móviles funcionales para 10+ ciudades, geo verificada. 2) El scraper recopila los 50 principales para cada ciudad y consulta, los CSV no están vacíos. 3) La limpieza y normalización se han realizado, los dominios se han extraído. 4) El clustering por intenciones está completo, cada consulta tiene asignada una intención. 5) Se han formado informes sobre las diferencias entre ciudades. 6) En el informe hay listas de consultas localizadas y no localizadas. 7) Hay recomendaciones sobre SEO regional basadas en los datos.
Cómo probar: 1) Compara varias consultas manualmente en el navegador a través del proxy correspondiente. 2) Verifica 5-10 filas de los CSV con resultados reales. 3) Revisa que el top-10 por ciudades realmente se diferencie donde se espera.
Métricas de éxito: cobertura de datos no menor al 80% de la cantidad planificada de combinaciones ciudad × consulta; número mínimo de errores de red; informes claros y reproducibles.
Errores típicos y soluciones
- Problema: captcha y bloqueos. Causa: alta frecuencia de solicitudes, encabezados similares, ausencia de pausas. Solución: aumenta las latencias, reduce el paralelismo, rota IP con menor frecuencia, cambia User-Agent, considera las API oficiales.
- Problema: geolocalización incorrecta. Causa: proxies con geo inestable o caché. Solución: verifica la geo a través de Yandex.Internetometer, cambia la IP, selecciona otro operador o ciudad.
- Problema: ruido en los datos y duplicados. Causa: URL no limpias, bloques publicitarios. Solución: agrega filtros por dominios, normaliza URL, guarda solo datos orgánicos.
- Problema: selectores HTML inestables. Causa: cambios en la estructura SERP. Solución: usa patrones más generales, prueba el scraper en 2-3 consultas, actualiza selectores.
- Problema: clústeres demasiado estrechos. Causa: umbral de similitud alto. Solución: baja el umbral, fusiona clústeres cercanos manualmente, revisa la tokenización.
- Problema: baja diferenciación entre regiones. Causa: elección incorrecta de consultas. Solución: agrega intenciones locales y verifica Jaccard entre pares de ciudades.
- Problema: sobrecarga de proxies. Causa: demasiadas solicitudes consecutivas. Solución: distribúyelas en el tiempo, usa proxies adicionales, añade colas y pausas.
Oportunidades adicionales
Ajustes avanzados: 1) Caché de respuestas HTML por clave (motor, ciudad, consulta) para ahorrar solicitudes. 2) Almacenamiento de datos en SQLite o PostgreSQL con índices por ciudad, consulta, dominio. 3) Registro de errores en archivos separados en logs con marcas de tiempo. 4) Integración de un navegador 'headless' (por ejemplo, utilizando Selenium) solo para consultas problemáticas donde no se recoge el snippet sin JS. 5) Uso de APIs oficiales: Google Custom Search API, Yandex.API (si están disponibles endpoint relevantes). Esto reducirá riesgos y aumentará estabilidad.
Optimización: 1) Randomización de latencias y User-Agent. 2) Reintentos inteligentes: repite solo solicitudes fallidas. 3) Destaca “consultas difíciles” en cola separada y trátalas después. 4) Lleva a cabo la recolección de datos de forma semanal o mensual para monitorear cambios.
Qué más se puede hacer: 1) Calculo de Rank-Biased Overlap entre ciudades para una evaluación más precisa de la similitud de los resultados. 2) Generación automática de recomendaciones: qué páginas crear para una ciudad específica. 3) Uso de un analizador morfológico para el español para mejorar el clustering. 4) Preparación de dashboards (por ejemplo, en Power BI) para visualizar la cobertura de dominios e intenciones por ciudad.
Consejo: Incluir una “lista negra” de dominios que siempre deben ser excluidos del análisis (por ejemplo, servicios no relevantes), pero guarda una copia de los datos crudos, para restaurar si es necesario.
FAQ
Pregunta 1: ¿Se puede optar por no usar proxies móviles? Respuesta: Sí, si hay APIs oficiales con parámetros regionales o usas centros de datos en ciudades. Pero los proxies móviles a menudo reflejan mejor los resultados de búsqueda locales reales.
Pregunta 2: ¿Cómo reducir la probabilidad de captchas? Respuesta: Aumenta las latencias, reduce el paralelismo, alterna User-Agent, usa rotación de IP no demasiado frecuente, y usa APIs oficiales si es posible.
Pregunta 3: ¿Cómo entender si una consulta está localizada? Respuesta: Si la composición de dominios en el top-10 cambia significativamente entre ciudades (bajo Jaccard), y en los resultados aparecen frecuentemente directorios locales y mapas, la consulta está localizada.
Pregunta 4: ¿Qué hacer si cambian las estructuras HTML en Google y Yandex? Respuesta: Mantén el scraper modular, añade auto-tests para 2-3 consultas estándar. Al cambiar, actualiza solo el módulo de scraping.
Pregunta 5: ¿Cómo etiquetar correctamente las intenciones? Respuesta: Combina heurísticas automáticas (listas de palabras clave) con revisiones manuales de casos discutibles. Aclara las intenciones con datos de conversiones.
Pregunta 6: ¿Qué hacer si hay pocos datos en la ciudad? Respuesta: Amplía la lista de consultas, añade lexemas LSI y long tails, ejecuta a diferentes horas del día, usa fuentes alternativas de semántica.
Pregunta 7: ¿Cómo tratar agregadores y marketplaces? Respuesta: No los elimines por completo. Marcalos como un tipo separado y analiza su influencia en tu nicho. Son competidores por tráfico.
Pregunta 8: ¿Se pueden combinar los datos de Google y Yandex? Respuesta: Sí. En los informes mantén la etiqueta motor. Compara por separado y juntos, para ver la estabilidad cruzada de los dominios.
Pregunta 9: ¿Con qué frecuencia actualizar los datos? Respuesta: Cada 2-4 semanas para nichos dinámicos, cada 1-2 meses para estables. Mantén versiones de informes para seguimiento de tendencias.
Pregunta 10: ¿Cuáles métricas son más útiles? Respuesta: Proporción de top-10 por dominios y clústeres, posición media, estabilidad de la posición, Jaccard entre ciudades, cobertura de intenciones.
Conclusión
Resumen de acciones realizadas: has preparado proxies por ciudades, verificado la geo, configurado el entorno Python, recopilado los 50 principales resultados en Google y Yandex para consultas y regiones elegidas, limpiado y normalizado los datos, clústerizado la semántica por intenciones y conducido análisis de diferencias de resultados entre ciudades. Como resultado, tienes un informe prácticamente aplicable que muestra en cuáles consultas los competidores son fuertes en cada región y qué consultas están localizadas.
Próximos pasos: 1) Crea y optimiza páginas locales de destino para clústeres localizados con intención comercial. 2) Refuerza señales de E-E-A-T en ciudades donde la posición es inestable. 3) Configura la recolección regular de datos y monitoreo de cambios. 4) Adapta el contenido a la información requerida en ciudades específicas.
Áreas de desarrollo: 1) Integración con CRM para evaluar conversiones por regiones. 2) Añadir señales de comportamiento y enlaces locales. 3) Ampliar el número de ciudades y temas de consultas. 4) Automatización de informes y visualización en herramientas BI.
Consejo: Documenta cada etapa y guarda configuraciones. Esto hará que tu proceso sea fácilmente escalable a nuevas ciudades y nichos.
Consejo: Mantén una plantilla de informe y una lista de verificación de inicio. Esto ahorra un 30-40% de tiempo en iteraciones repetidas.
