Mapa de Latencia: mapa gratuito de latencias de proxy hacia sitios populares y cómo maximizar su uso
Contenido del artículo
- Introducción: ¿por qué la velocidad de respuesta del proxy es crucial y dónde perdemos dinero?
- Revisión del servicio mapa de latencia: funciones clave y ventajas
- Escenario 1. marketing y compra de medios: selección de proxies para plataformas publicitarias
- Escenario 2. seo, scraping y recolección de datos: acelerar resultados y reducir captcha
- Escenario 3. e-commerce y retail: monitoreo de precios sin tiempos de espera
- Escenario 4. qa, producto y localización: verificación de la experiencia real de usuario desde diferentes países
- Escenario 5. soporte y sre: diagnóstico "caliente" de quejas en minutos
- Escenario 6. gestión de riesgos y cumplimiento: pronóstico del perfil de red
- Escenario 7. compra de proxies y optimización de costos: cómo no pagar de más
- Comparación con alternativas: ¿por qué es más conveniente el mapa de latencia?
- Faq: preguntas frecuentes sobre el mapa de latencia
- Conclusiones: quién puede beneficiarse y cómo comenzar ahora mismo
Introducción: ¿por qué la velocidad de respuesta del proxy es crucial y dónde perdemos dinero?
Todos hemos estado en la situación en la que parece que todo está configurado a la perfección, pero el sistema sigue ralentizándose. Los scraping y reportes se interrumpen. Las plataformas publicitarias se vuelven lentas y te expulsan de las sesiones. Los marketplaces responden de manera intermitente, y la lógica de los reintentos en los scripts se vuelve insostenible. ¿La causa? La latencia en la red entre tu proxy y el sitio objetivo. Un servidor rápido por sí solo no significa mucho si el camino hacia el recurso objetivo es largo y los paquetes tienen que rodear medio mundo. En 2026, cuando los sistemas anti-bot verifican más activamente las señales de comportamiento y de red, y HTTP/3 y QUIC cambian la forma de enrutar, las métricas de latencia se vuelven especialmente sensibles a la geografía, la elección del protocolo y la calidad del proveedor de proxies.
La tarea que resolvemos: evaluar rápida, masivamente y visualmente la latencia de un proxy hacia sitios populares, comparar resultados entre geografías y tomar decisiones prácticas — qué proxies adquirir más, cómo redistribuir la carga, dónde cambiar ubicaciones y dónde basta con ajustar los tiempos de espera y los reintentos.
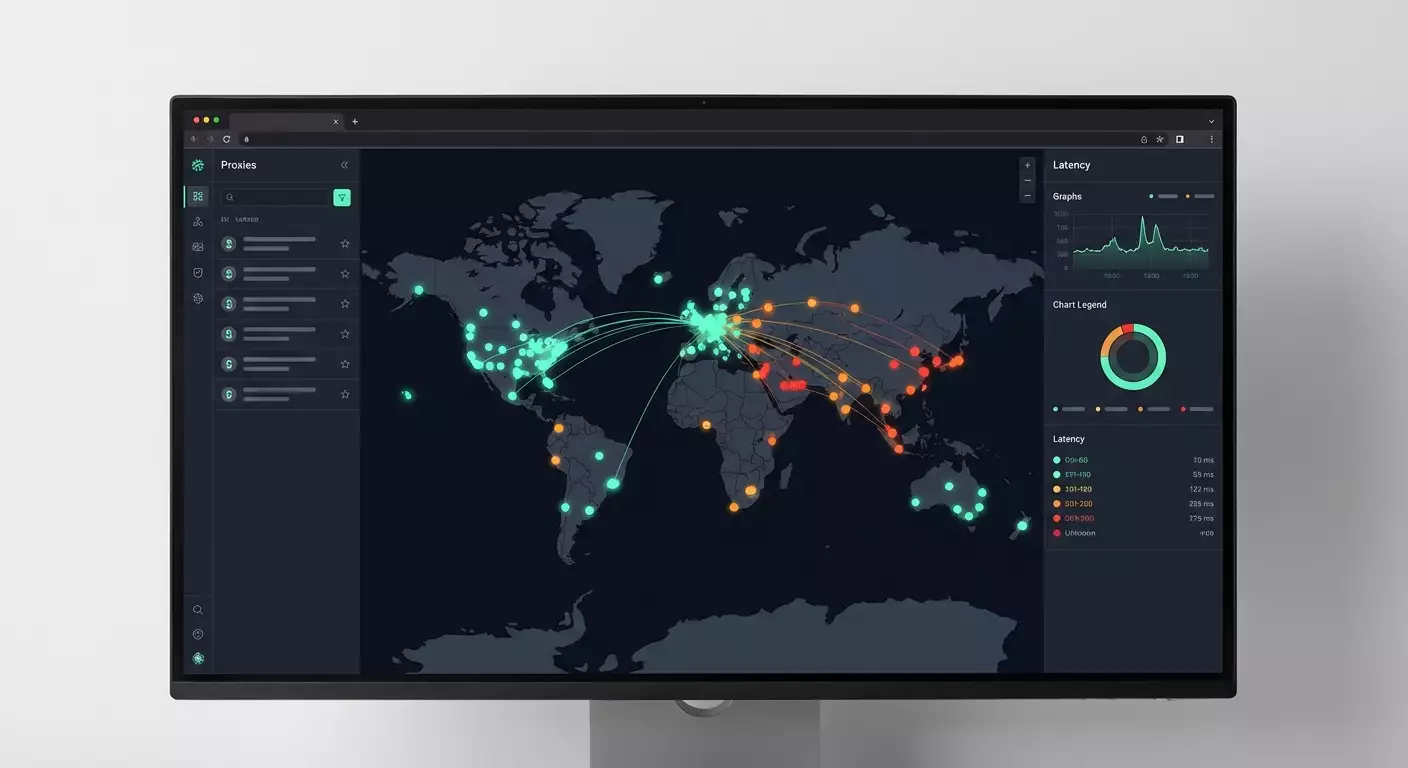
La herramienta gratuita en línea Mapa de Latencia de mobileproxy.space cubre esta necesidad: cargas una lista de proxies, eliges sitios, inicias la prueba y ves todo en un mapa interactivo. Directamente, sin instalaciones, sin scripts complicados, sin medidas manuales de "ping" en una sola dirección. Importante: el servicio mide la verdadera latencia de red a nivel de HTTP(S) o TCP hacia el dominio objetivo (no ICMP ping), lo que se acerca más a la experiencia práctica de tu aplicación o navegador.
Revisión del servicio Mapa de Latencia: funciones clave y ventajas
Qué es: una herramienta gratuita para evaluar la latencia de proxies hacia sitios populares, con visualización en un mapa mundial. Disponible en el navegador en la página Mapa de Latencia (sección del sitio mobileproxy.space). Sin registro ni pago, con enfoque en verificaciones prácticas.
Cómo funciona
- Indicas una lista de proxies en formato host:port, y si es necesario, usuario y contraseña. Soporta esquemas de autorización y formatos de registro comunes.
- Eliges uno o varios sitios populares para la prueba. La lista incluye recursos típicos: motores de búsqueda, redes sociales, marketplaces, CDN y medios.
- Inicias la prueba y observas un mapa interactivo con puntos, codificación de colores de las latencias y estadísticas resumidas por cada sitio y proxy.
Ventajas a destacar
- Inicio rápido. Sin instalaciones ni dependencias. La herramienta funciona en el navegador y está lista para verificaciones masivas.
- Mediciones realistas. Mide la latencia de conexión por el protocolo real al sitio objetivo, no un abstracto ICMP ping, que a menudo es bloqueado.
- Mapa. Inmediatamente ves la geografía y patrones: dónde hay latencias estables y bajas, y dónde hay caídas en la red o rutas inesperadas.
- Comparación de sitios. Comparas proxies hacia diferentes objetivos. Esto ayuda a resaltar proveedores que “se llevan bien” con plataformas específicas.
- Gratis. Para verificaciones rápidas y regulares, este es un argumento importante. Puedes ejecutar pruebas incluso a diario.
Aspectos técnicos a considerar
- Método de medición. En 2026, muchos sitios envían tráfico a través de CDN y Anycast. La latencia real depende del punto de presencia más cercano, así como del apretón de mano TLS, el protocolo y las políticas del firewall. El Mapa de Latencia tiene en cuenta esto a nivel de aplicación.
- Efectos geo-a-sitio. Para algunos sitios, los proxies en Varsovia y Praga muestran 20–40 ms, mientras que para otros 80–120 ms. Esto es normal: la enrutación y la política de CDN varían.
- Estabilidad vs picos. Una medición única es un corte. Es mejor realizar varias corridas y observar la mediana y distribución para filtrar picos a corto plazo.
Escenario 1. Marketing y compra de medios: selección de proxies para plataformas publicitarias
Para quién: compradores de medios, marketers de rendimiento, agencias que gestionan cuentas publicitarias en diferentes geografías.
Para qué: reducir la probabilidad de tiempos de espera y recargas innecesarias de las cuentas, acelerar la navegación y carga de creatividades, disminuir el estrés en las revisiones anti-bot mediante un perfil de red estable.
Cómo usar
- Prepara de 50 a 200 proxies de ubicaciones objetivo: país y, si es posible, ciudades cercanas a la plataforma que necesites.
- Carga la lista en el Mapa de Latencia, selecciona los sitios de los ecosistemas publicitarios y dominios relacionados (por ejemplo, recursos de análisis y archivos estáticos).
- Inicia la prueba. Registra la latencia para cada proxy en los objetivos clave.
- Forma una lista corta con el 20–30% mejores en latencia mediana y estabilidad (considera no solo el mínimo, sino también la previsibilidad).
- Asigna estos proxies a perfiles de trabajo y observa el comportamiento durante una semana.
Ejemplo con resultados
Un equipo de Europa del Este probó 120 proxies en cuatro dominios del ecosistema publicitario. Inicialmente, la latencia media era de 230–280 ms con picos raros de hasta 600 ms. Después de seleccionar el top 30% por mediana y estabilidad, la mediana bajó a 110–140 ms, los picos se redujeron a 3.2 veces, y la tasa de tiempos de espera al cargar las interfaces de las cuentas disminuyó en un 27% en las horas pico.
Consejos útiles
- No persigas el mínimo absoluto. Es mejor tener latencias estables de 120–140 ms que 70 ms con picos de hasta 900 ms.
- Verifica dominios relacionados. Las plataformas publicitarias a menudo cargan contenido de hosts auxiliares. El eslabón débil puede no ser obvio.
- Divide los destinos. Diferentes cuentas requieren diferentes proxies, incluso si son de la misma geo. Esto reduce la competencia por los recursos y los picos.
Errores comunes
- Prueban sólo el “dominio principal” e ignoran los auxiliares, donde ocurre la latencia.
- Evalúan con un solo recorrido. Realiza 2–3 pruebas y mira la mediana.
- Mezclan proxies con diferentes autorizaciones y protocolos en un mismo conjunto sin etiquetado, lo que lleva al caos en el diagnóstico.
Escenario 2. SEO, scraping y recolección de datos: acelerar resultados y reducir CAPTCHA
Para quién: especialistas en SEO, desarrolladores de scrapers, equipos de inteligencia competitiva.
Para qué: seleccionar proxies que ofrezcan la menor latencia hacia motores de búsqueda y sitios objetivo, para aumentar la velocidad de paso, disminuir la tasa de reintentos y la probabilidad de activar las protecciones anti-bot.
Algoritmo
- Reúne un conjunto de 200–500 proxies, divídelos por regiones (por ejemplo, UE, US Este, US Oeste, APAC).
- En el Mapa de Latencia, selecciona dominios clave de búsqueda y objetivo (motores de búsqueda, espejos, CDN de los sitios objetivo).
- Ejecuta 2–3 rondas de pruebas con intervalos de 10–15 minutos y recoge valores medianos.
- Clasifica los proxies en clústeres: rápidos, medios, lentos. Asigna las tareas críticas a los rápidos, las menos sensibles a los medios, y las de fondo a los lentos.
- Sincroniza esto con la configuración de tu scraper: canales a proxies, límites de tiempo, reglas de reintentos.
Caso práctico
Un scraper de feeds de noticias funcionaba en 12 hilos con 300 proxies. La velocidad promedio de carga de la página era de 2.3 segundos, con una tasa de reintentos del 9.7%. Tras la clasificación de los resultados del Mapa de Latencia y la reasignación de proxies rápidos a dominios críticos, la velocidad se redujo a 1.6 segundos, los reintentos bajaron al 4.1% y el volumen total de documentos recolectados aumentó en un 38% con los mismos recursos.
Mejores prácticas
- Mira la distribución, no solo la media. ”Las colas” de latencia afectan el SLA del scraper.
- Combina con pruebas locales. Se recomienda comparar con resultados de curl -x y tiempos hasta el primer byte en un GET típico.
- Deja un margen. El conjunto debería tener un 15–25% de exceso de proxies rápidos para picos o bloqueos.
Errores fáciles de evitar
- Elegir proxies rotativos para tareas que requieren cookies y sesiones estables. Para estabilidad, utiliza sesiones “pegajosas”.
- Falta de etiquetado por regiones. Sin esto, es difícil entender dónde surgen los cuellos de botella de latencia.
Escenario 3. E-commerce y retail: monitoreo de precios sin tiempos de espera
Para quién: analistas de e-commerce, especialistas en fijación de precios, equipos de monitoreo competitivo.
Para qué: reducir tiempos de espera al navegar por tarjetas de productos y filtros, alinear la velocidad de extracción de datos y disminuir los intervalos de desactualización de precios.
Pasos a seguir
- Reúne un conjunto de proxies en los principales mercados: dónde están los almacenes y clientes de tus competidores. Esto es importante para la relevancia de los precios y el surtido.
- En el Mapa de Latencia selecciona los marketplaces y dominios estáticos objetivo (imágenes, CDN), que influyen significativamente en el tiempo de carga total.
- Realiza tres corridas en diferentes horas del día, obtén la mediana y el rango intercuartil.
- Selecciona el top 40% en estabilidad y valor promedio de latencia y asígnalos a países críticos.
- Los demás, asigna a tareas de fondo y categorías poco comunes.
Resultados prácticos
Un equipo que monitoreaba 9 marketplaces en 5 regiones redujo el tiempo promedio de pase por el catálogo de 3.1 a 2.0 segundos y disminuyó la tasa de páginas con tiempos de espera del 6.2% al 2.3%. Gracias a esto, la “ventana de frescura de precio” se redujo de 45 a 28 minutos con el mismo parque de servidores. En picos estacionales, el retraso de actualización en SKU críticos se redujo a 12–15 minutos mediante redistribución automática a los proxies más rápidos.
Consejos
- Divide los flujos por dominios. No asignes a un mismo proxy diferentes marketplaces al mismo tiempo si son pesados. Permite que los proxies rápidos se “fijen” a uno o dos dominios clave.
- Atiende a la “estática”. Incluso si el HTML se entrega rápidamente, los recursos estáticos a través de un CDN diferente pueden llevar tiempo y afectar indirectamente los tiempos del scraper/render.
- Estacionalidad. En ventas y festividades, realiza corridas adicionales en el Mapa de Latencia y reajusta la distribución cada 12–24 horas.
Escenario 4. QA, producto y localización: verificación de la experiencia real de usuario desde diferentes países
Para quién: ingenieros de QA, gerentes de producto, equipos de localización, gerentes de contenido.
Para qué: asegurarte de que los usuarios de las regiones correctas reciben una rápida respuesta de los recursos, especialmente si usas CDN, redirecciones geográficas y personalización de contenido.
Pasos a seguir
- Prepara una lista de proxies lo más cercana posible a tus ciudades objetivo. Si operas en Madrid, selecciona no solo “España”, sino específicamente Madrid/Valencia/Barcelona.
- En el Mapa de Latencia, prueba la latencia hacia tu dominio, el dominio CDN, así como hacia servicios externos que dependan de la interfaz (fuentes, análisis, widgets).
- Compara latencias entre regiones y proveedores. Presta atención a los países con valores anormales.
- Transmite los resultados a SRE/DevOps para validar la enrutación, configuración de caché en el CDN y políticas TLS.
- Reinicia la prueba después de los cambios, compara con la mediana anterior y los picos.
Caso
El equipo de producto notó que había quejas desde Brasil: las páginas eran “pesadas” y aumentó la frecuencia de desconexiones. La prueba del Mapa de Latencia mostró 350–420 ms hacia el dominio principal y hasta 700 ms hacia el CDN estático. Tras reconfigurar el CDN hacia los PoP más cercanos y optimizar las políticas TLS, la mediana bajó a 150–190 ms, los rechazos de autenticación volvieron a la normalidad, y el NPS en la región aumentó en 0.6 puntos en dos semanas.
Consejos útiles
- Verifica etiquetas externas. Contadores, widgets, fuentes — son fuentes comunes de "pegajosidad" de red. Su mediana en la región no debe ser peor que la de tu dominio principal.
- Combina con análisis sintéticos. Compara el Mapa de Latencia con las mediciones de TTFB, LCP, INP en automatizaciones de navegador.
- Planea cambios A/B. Prueba cambios en red en una región y valida el efecto del Mapa de Latencia antes de un lanzamiento global.
Escenario 5. Soporte y SRE: diagnóstico "caliente" de quejas en minutos
Para quién: soporte técnico, SRE, ingenieros de guardia.
Para qué: confirmar o refutar rápidamente una hipótesis de red ante quejas de usuarios de una región específica y determinar hacia dónde escalar — a CDN, al proveedor de proxy o a servicios internos.
Protocolo de acción
- Recibes quejas de una región o país específico. Abre el Mapa de Latencia.
- Carga un conjunto de proxies “de referencia” desde ese país. Si no tienes propios, utiliza proxies públicos o alquilados que sean confiables.
- Realiza pruebas hacia tus dominios clave. Compara con la mediana base guardada de tus pruebas anteriores.
- Si el aumento de latencia se confirma solo en estáticos — escala a CDN. Si es en general — revisa la enrutación y posibles bloqueos.
- Genera un incidente con una captura de pantalla del mapa y un resumen tabular de la mediana, picos y porcentaje de tiempos de espera.
Ejemplo
Un ingeniero de guardia recibió alertas nocturnas sobre el aumento del tiempo de respuesta desde Singapur. El Mapa de Latencia mostró un aumento de 2 a 3 veces en latencias solo hacia el dominio estático. Tras revisar los PoP cercanos del CDN, se localizó y resolvió el problema en 25 minutos. El MTTR se redujo casi a la mitad con respecto a la media.
Mejores prácticas
- Guarda instantáneas. Fija la mediana y los picos para geos de referencia. Esto es tu punto de referencia para incidentes.
- Segmenta dominios. Realiza pruebas separadas hacia API, archivos estáticos, autenticación, servicios externos.
- Mantén un “kit de emergencia”. Ten a mano una lista de proxies confiables de países clave para no perder tiempo en un incidente.
Escenario 6. Gestión de riesgos y cumplimiento: pronóstico del perfil de red
Para quién: gerentes de riesgos, compliance, ingenieros encargados de la precisión geográfica y los escenarios de usuario según la ubicación.
Para qué: asegurarte de que los parámetros de la red no generen falsos positivos: por ejemplo, la probabilidad de un perfil “atípico” debido a una latencia excesiva entre la geo declarada y los recursos objetivos.
Plan
- Selecciona proxies por países donde es importante la localización correcta y la regulación.
- Mide la latencia hacia los sitios básicos de la región: motores de búsqueda locales, portales de noticias, pasarelas de pago, servicios gubernamentales (si son públicos y no prohíben este tipo de comprobaciones).
- Forma un perfil de rango de latencias aceptables para cada país y ciudad: mediana, IQR, picos raros.
- Compara nuevos proxies con la referencia. Latencias sospechosamente altas son motivo para verificar la geolocalización real y la enrutación.
Efecto práctico
El equipo redujo la tasa de falsos positivos por “comportamiento atípico” en un 18% al trasladar a agentes usuarios a proxies que mostraban un perfil de red similar al de la referencia de la región. Al mismo tiempo, las operaciones de rechazo por cumplimiento disminuyeron en un 11% sin comprometer la seguridad.
Observaciones
- Ética y leyes. Usa proxies estrictamente dentro de la ley, condiciones de los sitios y políticas de tu empresa. La herramienta tiene como objetivo medir, no evadir restricciones.
- Compara con ASN y ciudades. Una gran latencia hacia recursos locales es un signo común de no conformidad en la geografía real.
Escenario 7. Compra de proxies y optimización de costos: cómo no pagar de más
Para quién: compradores de proxies, líderes de equipo responsables del presupuesto y SLA.
Para qué: comparar proveedores, elegir ubicaciones óptimas y conjuntos de direcciones, excluir redes “rojas” y ordenar el plan de compra.
Paso a paso
- Reúne una lista de prueba de 3 a 5 proveedores de los mismos países.
- En el Mapa de Latencia, ejecuta pruebas secuenciales en conjuntos idénticos de sitios objetivos, guardando los resultados.
- Compara la mediana, estabilidad, tasa de tiempos de espera para cada proveedor y país.
- Haz una matriz “precio - mediana - estabilidad” y calcula el costo por milisegundo para las direcciones críticas.
- Compra la mayoría de los proxies al proveedor con la mejor relación precio/estabilidad, manteniendo un fondo de un proveedor alternativo.
Resultado final
El equipo redujo costos en un 14% en un trimestre, dando de baja a un proveedor premium en dos países, donde el Mapa de Latencia mostró paridad con un jugador más accesible. Al mismo tiempo, el SLA de latencia se mantuvo en la zona verde, y los tiempos de espera incluso disminuyeron en 0.9 puntos porcentuales gracias a la eliminación de subredes específicas con picos anormales.
Consejos para compradores
- Prueba por lotes. Es importante que diferentes proveedores sean probados al mismo tiempo y en los mismos dominios.
- Mira los picos. Si el percentil 95 se dispara, el rendimiento real de las tareas “se irá al pozo” durante picos.
- No olvides el IPv6. En 2026, más recursos optimizan tráfico hacia IPv6. Compara resultados de v4 vs v6, si tus flujos lo soportan.
Comparación con alternativas: ¿por qué es más conveniente el Mapa de Latencia?
Scripts y utilidades
Enfoques clásicos: ping, curl -x, scripts en Python. Ventajas: flexibilidad y control. Desventajas: requieren tiempo para desarrollar, infraestructura para visualizar y almacenar métricas, y son complejos para no ingenieros. El Mapa de Latencia resuelve el 80% del problema de inmediato, muestra un mapa y no requiere escribir código.
Plataformas comerciales de monitoreo
Ventajas: reportes ricos, alertas, tendencias históricas. Desventajas: son de pago, la configuración toma tiempo y no siempre están diseñadas para proxies o para pruebas masivas de sitios específicos. El Mapa de Latencia es un punto de respuesta rápido y gratuito: dónde está la lentitud específicamente en estos sitios y estos proxies.
ICMP ping y traceroute
Útiles para diagnóstico de red, pero a menudo son bloqueados y no reflejan el comportamiento de HTTPS. El Mapa de Latencia mide la latencia a nivel de aplicación y se acerca más a lo que ve tu usuario o script.
Conclusión
Si necesitas información ahora y clara, el Mapa de Latencia gana: un mapa interactivo, la carga masiva de proxies, la comparación de varios sitios sin código y sin costo. Para monitoreo a largo plazo, puedes combinar la herramienta con tus sistemas de métricas y registros.
FAQ: preguntas frecuentes sobre el Mapa de Latencia
1. ¿Qué mide exactamente el servicio — es un ping?
No, no es ICMP ping. La herramienta se centra en el nivel de aplicación: mide la latencia en establecer conexión y respuesta desde el sitio objetivo por el protocolo real. Esto se asemeja más a lo que ve el navegador o tu scraper.
2. ¿Se soportan HTTP y SOCKS?
Se apoyan los formatos estándar de proxies con y sin autorización. Para la mayoría de los casos, HTTP(S) y SOCKS funcionan de manera inmediata. Consulta el protocolo con tu proveedor de proxies y utiliza el formato correcto.
3. ¿Por qué la latencia hacia diferentes sitios es tan variable desde el mismo proxy?
Debido a CDN, Anycast, políticas de caché y enrutación. Diferentes sitios pueden ser servidos desde diferentes PoP. Esta es la situación normal para el año 2026.
4. ¿Se pueden probar muchos proxies a la vez?
Sí, la herramienta admite carga masiva. Para la precisión de los resultados, haz varias corridas y observa las restricciones de tiempo de espera.
5. ¿Qué significan los colores en el mapa?
La escala de colores refleja los rangos de latencias: verde condicional — baja, amarillo — media, rojo — alta. Los umbrales exactos dependen de la escala seleccionada en la interfaz y pueden ser ajustados.
6. ¿Dónde se guardan los resultados?
Utilizas la herramienta en el navegador. Se recomienda exportar o registrar los resultados después de la prueba para un análisis posterior. Los mecanismos internos de almacenamiento pueden cambiar, así que orienta tu análisis en la funcionalidad actual de la página del Mapa de Latencia.
7. ¿Cómo probar proxies rotativos?
Ejecuta varias corridas en el mismo host para captar la distribución. Si es necesario, usa sesiones “pegajosas” si el proveedor lo admite, para evaluar la estabilidad.
8. ¿Por qué en algunos sitios hay tiempos de espera o ceros?
El sitio puede haber limitado la frecuencia de solicitudes, bloqueado una IP de salida específica o aplicado políticas que no permiten finalizar correctamente la medición. Repite la prueba, verifica el formato del proxy y la autorización, y compáralo con un proxy alternativo.
9. ¿Funciona con IPv6 y HTTP/3?
En 2026, muchos sitios están migrando a IPv6 y HTTP/3. Los resultados pueden variar por protocolos. Si tu proveedor de proxies y el sitio objetivo soportan IPv6, compara indicadores para v4 y v6. En cuanto a HTTP/3, considera las características de QUIC y el comportamiento de CDN.
10. ¿Puedo probar mis dominios internos?
Si los dominios son accesibles desde internet a través de tus proxies, sí. Para redes internas sin acceso externo, la medición no será posible.
Conclusiones: quién puede beneficiarse y cómo comenzar ahora mismo
Quién lo necesita: marketeros y compradores de medios, equipos de SEO y scraping, analistas de e-commerce, QA y product managers, SRE y soporte, compradores de proxies. Todos aquellos que toman decisiones donde cada milisegundo cuenta para la estabilidad, SLA y conversiones.
Qué obtienes: una representación real de las latencias entre tus proxies y sitios reales, un mapa interactivo para visualización, selección rápida de los mejores direcciones y control de estabilidad. La herramienta es gratuita y funciona en el navegador, así que ahorras tiempo y presupuesto en diagnóstico.
Cómo empezar:
- Reúne una lista de proxies por países y ciudades objetivo. Indica el protocolo y autorización.
- Abre la página del Mapa de Latencia en el sitio mobileproxy.space en la sección latency-map.
- Carga los proxies, selecciona los sitios deseados y ejecuta la prueba.
- Haz 2–3 corridas, guarda la mediana y distribución. Forma una lista corta con los mejores proxies para tareas críticas.
- Incorpora en la configuración de tus herramientas, revisa límites, reintentos y distribución de carga. Repite las pruebas cada 1–2 semanas o antes de picos de tráfico.
Y por último: usa el Mapa de Latencia junto con tu analítica de rendimiento y registros. Donde necesitas visibilidad instantánea y pruebas masivas, el mapa de latencias proxy es una herramienta rápida, gratuita y clara que ayuda a tomar decisiones basadas en datos, no en impresiones.
