LLMO y GEO en 2026: cómo aparecer en las respuestas de los buscadores AI y ganar tráfico
Contenido del artículo
- Introducción: por qué es relevante el tema y qué aprenderá el lector
- Fundamentos: conceptos fundamentales (para principiantes)
- Profundización: cómo están estructuradas las respuestas ai y los factores de citación
- Método 1. contenido answer-first y arquitectura modular de páginas
- Método 2. schema.org y datos estructurados como "idioma" para llm
- Método 3. entidad centrada en geo: cómo sincronizar conocimientos y regiones
- Método 4. idoneidad técnica para bots ai y aceleración de recuperación
- Errores comunes: qué no hacer
- Herramientas y recursos: qué utilizar
- Casos y resultados: ejemplos reales de aplicación
- Faq: 10 preguntas profundas
- Conclusión: resumen y próximos pasos
Introducción: por qué es relevante el tema y qué aprenderá el lector
En 2026, los usuarios comenzarán a realizar búsquedas no en la clásica página de resultados, sino dentro de asistentes AI y buscadores AI: ChatGPT, Perplexity, Claude, Gemini, YandexGPT. La respuesta se genera directamente en el chat e incluye enlaces a fuentes que el modelo considera confiables. No se trata solo de un "nuevo tipo de resultado". Este es un nuevo enfoque para el tráfico orgánico y la presencia de marca. La pregunta queda clara: ¿cómo hacer que su sitio aparezca en las fuentes citadas y que la IA construya respuestas basadas en su contenido?
En esta guía, analizarás la mecánica de funcionamiento de los buscadores AI, entenderás por qué los resultados LLM siguen otras reglas que el SEO clásico, obtendrás métodos de optimización claros (LLMO), marcos para contenido y esquemas de marcado, listas de verificación para la preparación técnica, enfoques para la geopersonalización (GEO) y la localización, así como instrucciones prácticas para monitorear tus posiciones en las respuestas AI. Te mostraremos cómo y por qué el monitoreo requiere proxies móviles de diferentes regiones y te proporcionaremos herramientas para el trabajo diario.
Fundamentos: conceptos fundamentales (para principiantes)
Qué es LLMO
LLMO (Optimización de Modelos de Lenguaje Amplio) es un conjunto de prácticas que aumentan la probabilidad de que tu contenido sea encontrado, comprendido, verificado y citado en una respuesta por un gran modelo de lenguaje. A diferencia del SEO clásico, aquí no solo importa el ranking de la página, sino la idoneidad del contenido para la extracción de hechos, verificación e inclusión segura en una respuesta consolidada.
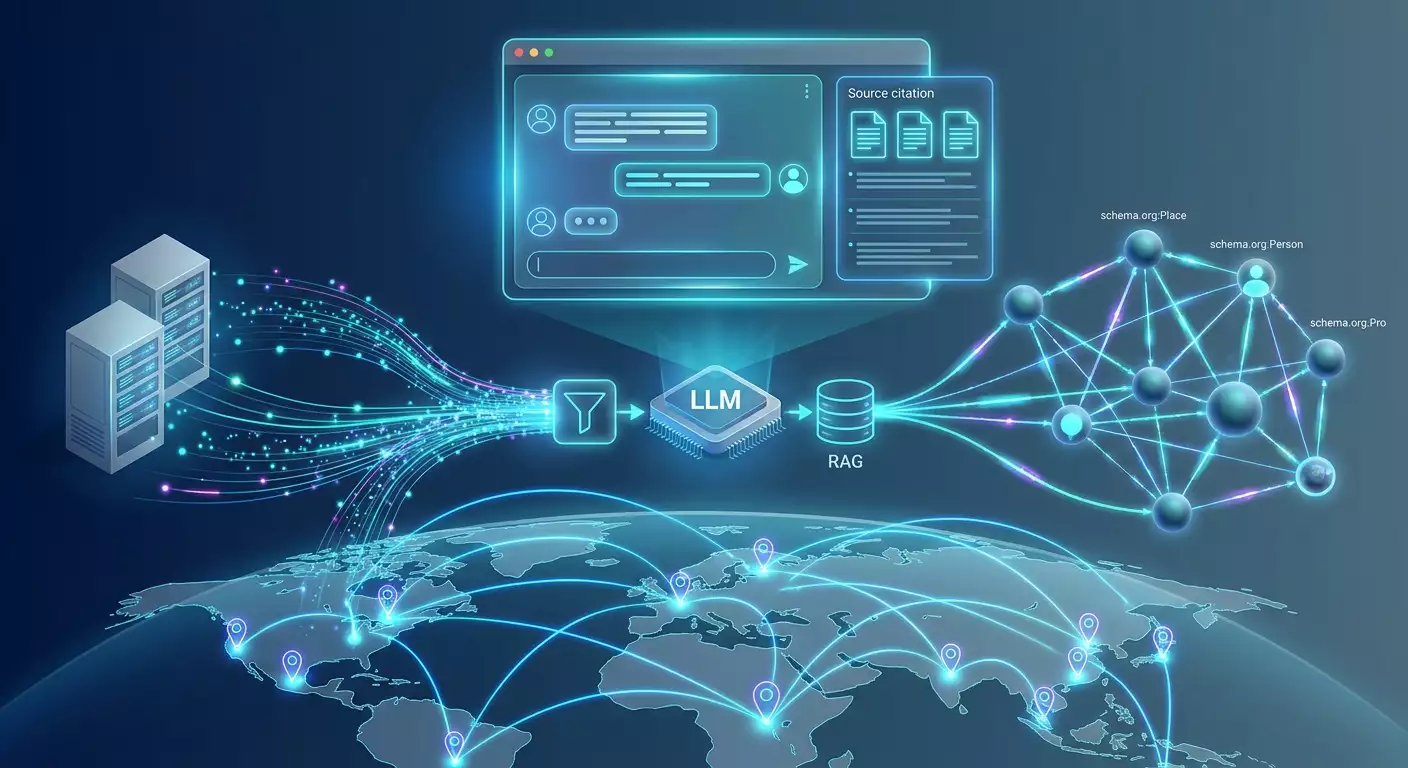
Cómo funciona la búsqueda AI
Los sistemas modernos utilizan un híbrido: búsqueda vectorial (embeddings) para coincidencias semánticas y índice clásico para coincidencias exactas y señales de autoridad. Después se activa la pipeline RAG (Generación Aumentada por Recuperación): la consulta se interpreta, se extraen candidatos del índice, se reevalúa, se construye un plan de respuesta, luego el modelo genera texto y lo "aterriza" en fuentes, formando un bloque de citas.
Por qué es crítico el aspecto GEO
La respuesta depende del país, idioma, moneda, normas y realidades locales. La misma consulta en diferentes regiones lleva a diferentes fuentes y formulaciones. Por lo tanto, GEO no es "traducción de la página", sino una adaptación sistemática de hechos, datos estructurados y señales de confianza para una región específica.
Diferencias entre LLMO y SEO
- La unidad de competencia no es un fragmento ni la posición en SERP, sino la inclusión en el conjunto de fuentes citadas dentro de la respuesta.
- El factor clave es la verificabilidad de los hechos y la estructuración del conocimiento para la extracción.
- El contenido debe ser answer-first: respuestas claras, luego base probatoria.
- El camino del usuario es más corto: menos clics, más confianza en la respuesta de IA. La importancia de la marca y la experticia aumenta.
Profundización: cómo están estructuradas las respuestas AI y los factores de citación
Pipelines típicos de la búsqueda AI
- Interpretación de la consulta: normalización, detección de intención, definición de idioma y región.
- Candidatos: búsqueda híbrida usando índice vectorial e índice clásico.
- Reevaluación: los modelos de ranking consideran precisión, exhaustividad, frescura, autoridad, y cumplimiento del GEO.
- Plan de respuesta: descomposición en subtemas (sub-queries), asignación a cada "fuente de referencia".
- Generación con aterrizaje: LLM escribe respuesta, cita fuentes y verifica hechos.
- Seguridad y filtros de calidad: eliminación de contenido controvertido, tóxico o dudoso.
- Cacheo y personalización por sesión, región, idioma.
Factores clave que aumentan la probabilidad de citación
- Veracidad y verificabilidad: formulaciones claras, cifras, marcas de tiempo, fuentes primarias dentro del contenido.
- Estructura y extracción: secciones de Q&A, listas, tablas, HowTo, FAQ, atributos de productos; correcta schema.org en JSON-LD.
- Autoridad y responsabilidad profesional: autores expertos mencionados, editor, fecha de actualización, metodología.
- Conformidad GEO: unidades de medida locales, moneda, teléfonos, direcciones, casos locales.
- Frescura y historial de actualizaciones: changelogs explícitos, fecha de última actualización, rápida reindexación.
- Accesibilidad técnica: velocidad, renderizado correcto sin bloqueadores JS, permisos para bots AI, sitemaps.
- Consistencia: ausencia de desincronización en la misma entidad en diferentes páginas.
Por qué es importante para las empresas
En muchas verticales, para 2026 del 35 al 45% de las consultas informativas y comerciales comenzarán con respuestas AI. Aparecer en citas significa un flujo de tráfico objetivo con alta confianza y un ciclo de decisión corto. No hacerlo, es perder atención, incluso si las posiciones SEO se mantienen fuertes.
Método 1. Contenido answer-first y arquitectura modular de páginas
Principio
Las páginas deben estar compuestas por módulos que LLM reconozca y extraiga fácilmente: "Respuesta corta" → "Desarrollado" → "Pruebas" → "Pasos/HowTo" → "Preguntas frecuentes" → "Fuentes/Metodología". Esta estructura aumenta las posibilidades de citación de diferentes segmentos para diferentes subconsultas.
Instrucciones paso a paso
- Descríbelo de forma concisa. ¿Qué debe ser encontrado y citado? ¿Un hecho, comparación, pasos, costo, definición, política local?
- Crea "Respuesta corta". 40–120 palabras, formulaciones precisas, sin lenguaje publicitario, con fecha de relevancia.
- Bloque desarrollado. 200–400 palabras. Aclaraciones, contexto, límites de aplicabilidad.
- Base probatoria. Métricas, fórmulas, datos de origen, metodología de cálculo. Para comercio: condiciones, garantías, parámetros.
- HowTo/Pasos. Pasos numerados claros con resultados materiales de cada paso.
- FAQ. 6–10 preguntas comenzando con "cómo", "cuándo", "por qué", "cuánto", "qué hacer si".
- Localiza. Moneda, números de teléfono, direcciones, ejemplos locales.
- Fecha de actualización y propietario. Autor experto, editor, fecha, versión, contacto.
Lista de verificación de calidad de módulo
- Hay "respuesta corta" con fecha.
- Hay cifras/rangos con unidades de medida.
- Hay atributos locales (moneda, leyes, direcciones).
- Hay una lista HowTo en estructura evidente.
- Hay FAQ con preguntas directas.
- Author, reviewedBy, dateModified están marcados en JSON-LD.
Marco APEX
- Answer: formula una respuesta en un párrafo.
- Proof: adjunta cifras y fuentes primarias.
- Expand: expande excepciones, comparaciones, alternativas.
- Xecute: añade pasos de acción y listas de verificación.
Método 2. Schema.org y datos estructurados como "idioma" para LLM
Por qué JSON-LD resuelve
Los buscadores LLM utilizan activamente datos estructurados como señal de veracidad y "mapa" para la extracción de hechos. Un correcto y rico marcado schema.org ayuda a los modelos a asociar hechos con entidades, autoría, tiempo, geografía y estatus legal.
Tipos clave de schema.org para LLMO
- WebPage y Article: headline, description, datePublished, dateModified, inLanguage, isPartOf.
- Organization: name, legalName, logo, contactPoint, sameAs, foundingDate, address.
- Person (autor/revisor): name, affiliation, jobTitle, alumniOf, sameAs.
- FAQPage: lista de preguntas/respuestas en estructura evidente.
- HowTo: steps, supply, tool, estimatedCost, totalTime.
- Product: name, sku, brand, offers (price, priceCurrency, availability, priceValidUntil), aggregateRating.
- QAPage: para páginas con estructura de pregunta-respuesta con votación/moderación experta.
- BreadcrumbList: contexto en jerarquía.
- ClaimReview: para la verificación de afirmaciones específicas, cuando sea aplicable.
Reglas prácticas
- Utiliza JSON-LD en cada página relevante; evita conflictos entre el marcado y el texto visible.
- Indica atributos geográficos: addressLocality, addressCountry, priceCurrency, applicableLocation, areaServed.
- Gestiona la autoría: author, reviewedBy, publisher; para páginas expertas, indica la calificación.
- Mantén identificadores estables: @id para entidades, para que los LLM vinculen páginas entre sí.
- Actualiza dateModified en cambios significativos y lleva un changelog en formato legible.
- Marca tablas y bloques fácticos como HowTo/FAQ/QuantitativeValue donde sea posible.
Verificación de corrección
Verifica JSON-LD con validadores, asegúrate de la consistencia con los metatags y el contenido. Cualquier desincronización reduce la confianza del modelo y puede hacer que tu página sea eliminada del conjunto de candidatos.
Método 3. Entidad centrada en GEO: cómo sincronizar conocimientos y regiones
Entidades y Gráfico de Conocimiento
Los buscadores AI piensan en entidades: empresas, productos, ubicaciones, servicios, procesos. Si tu empresa y ofertas clave no están estructuradas como entidades con identificadores y atributos estables, el modelo se "confundirá" y seleccionará otras fuentes.
Pasos para la implementación
- Crea "páginas de inicio para entidades" para la empresa, productos, tarifas, metodologías. Deben tener atributos canon: nombres, descripciones, parámetros, límites, precios actuales y monedas.
- Conecta entidades entre sí a través de enlaces internos y @id en JSON-LD, para que el gráfico esté interconectado.
- Agrega sameAs a perfiles externos oficiales y catálogos que incrementen la confianza (sin redundancia ni duplicación).
- Localiza atributos: utiliza hreflang, inLanguage, priceCurrency, areaServed, métodos de pago aceptables y datos de contacto locales.
- Armoniza información legal: legalName, datos de registro, condiciones de oferta y políticas en perspectiva regional.
Estrategia de contenido GEO
- Idioma y terminología: evita calcos directos, utiliza terminología local y estándares de la industria.
- Datos y ejemplos: casos de la región objetivo, estudios locales, rangos de precios y tiempos considerando la logística local.
- Servicio al cliente: zona horaria local y canales de comunicación.
Método 4. Idoneidad técnica para bots AI y aceleración de recuperación
Acceso e indexación
- Robots y bots AI: no bloquees agentes AI legítimos; asegúrate de una presentación correcta de versiones cacheables sin barreras dinámicas.
- Sitemaps: distribuye contenido por tipos (artículos, productos, ayuda), manten un sitemap-index, y soporta lastmod.
- Señales HTTP: utiliza ETag, Last-Modified, códigos correctos para reducir costos de recrawl.
- Renderizado: evita contenido crítico cargado solo por JS post-facto; asegúrate de una mejora progresiva.
Puntos finales y documentos
Para entidades con parámetros tabulares, crea "endpoints de datos" livianos (por ejemplo, páginas JSON con precios y parámetros) accesibles para indexación. Para PDFs, utiliza capas de texto y un índice; agrega versiones HTML.
Frescura y señal de actualizaciones
- Publica changelog en las páginas.
- Actualiza dateModified y refleja actualizaciones puntuales (por ejemplo, recuento de precios).
- Un feed separado de actualizaciones que indique a robots y sitemaps.
Errores comunes: qué no hacer
- Preeoptimización bajo palabras clave sin hechos y estructura: LLM los ignora.
- Autoría oculta o falta de cualificación del experto: disminuye la confianza.
- Duplicación de entidades con diferentes nombres y parámetros: el gráfico se "descompone", el modelo se irá a fuentes consistentes.
- El mismo contenido para todas las regiones: no considera normas locales y costos.
- JS-placas para datos clave que los bots no ven: no hay indexación de hechos.
- Falta de validación schema.org: errores en JSON-LD rompen la capacidad de extracción.
- Ignorar el monitoreo: es difícil gestionar lo que no mides.
Herramientas y recursos: qué utilizar
Monitoreo de posiciones en respuestas AI
Aún no existe un "AI-SERP" estandarizado, pero podemos construir un sistema funcional.
Principio
- Define un conjunto de consultas (informativas, comerciales, de marca).
- Ejecuta en buscadores AI objetivo a través de interfaz web o API, si está disponible.
- Guarda la respuesta completa y el listado de fuentes citadas, fijando el orden y la función (punto principal, secundario, nota).
- Mide la cuota de cobertura: porcentaje de sesiones donde nuestro dominio es citado y la posición promedio entre citas.
- Repite de diferentes regiones y lenguas para ver la distribución GEO.
Por qué son críticos los proxies móviles
Las respuestas AI dependen de GEO y contexto de red. Diferentes regiones utilizan diversas fuentes locales, precios locales y marcos legales. Para obtener resultados válidos en el monitoreo, se necesitan direcciones IP de países objetivo y redes operadoras. Los proxies móviles proporcionan un entorno de red autorizado de SIMs reales, lo cual es vital para una correcta geolocalización y capas de cache de servicios AI.
Práctica con MobileProxy.Space
Para un monitoreo distribuido, es conveniente utilizar proxies móviles con opción de rotación y selección de país/operador. El servicio MobileProxy.Space ofrece 218+ millones de IP en 53+ países en SIMs reales de operadoras, protocolos HTTP(S) y SOCKS5 simultáneamente, rotación flexible por temporizador, API o enlace, 3 horas de prueba gratuita y soporte 24/7. Esto permite recopilar de manera estable instantáneas de respuestas AI por regiones y horarios. El código promocional YOUTUBE20 otorga un 20% de descuento en la primera compra.
Pila técnica para monitoreo
- Navegadores headless con tiempo, idioma y zona horaria controlados.
- Huella digital única del navegador para repetibilidad. Para diagnósticos, utiliza el generador de huellas en MobileProxy.Space y el mapa de latencias para escoger puntos óptimos.
- Verificación del entorno: antes de comenzar cada ejecución, registra IP y verifica fugas DNS a través de herramientas integradas "Verificación de IP", "Prueba de fuga de DNS" y "Comprobador de Proxies".
- Almacenamiento de resultados: guarda respuestas sin procesar, normaliza citas, versiona.
- Analítica: métricas de cobertura, posición en citas, frecuencia de menciones de entidades, por regiones y lenguas.
Herramientas de calidad en el sitio
- Validadores schema.org y pruebas automáticas de consistencia entre JSON-LD y contenido visible.
- Registro de bots AI por User-Agent y ASN; análisis de profundidad de crawl, frecuencia y códigos de respuesta.
- Calculadora de proxies en MobileProxy.Space para planificar el perfil de proxies según la cantidad de consultas y regiones.
Optimización de la disponibilidad en red
Utiliza el mapa de latencias de MobileProxy.Space para elegir regiones de salida, equilibra rutas de peering, y controla la estabilidad RTT — esto influye en la probabilidad de obtener cache actualizado y velocidad al cargar páginas en el momento de la recuperación.
Casos y resultados: ejemplos reales de aplicación
Caso 1: B2B SaaS — aumento de citaciones del 6% al 34% en 90 días
Tarea: la página del producto y el centro de conocimiento no aparecían en citas AI para consultas clave. Acciones: implementamos la estructura APEX, añadimos HowTo y FAQ, formalizamos la autoría y reviewedBy, ampliamos el JSON-LD (Product+HowTo+FAQPage), creamos un changelog. GEO: localización de terminología en 3 idiomas, moneda según la región. Monitoreo desde 8 países a través de proxies móviles. Resultado: la participación de respuestas donde se cita el dominio aumentó del 6% al 34%, y la posición promedio de citación mejoró de 3.1 a 1.7; conversión del tráfico AI +22%.
Caso 2: Catálogo de comercio electrónico — logro de "respuestas con precios"
Tarea: los buscadores AI mencionaban precios de competidores, ignorando nuestro surtido. Acciones: marcado de producto con offers, priceCurrency y validez, endpoint JSON con precios, indicación de applicableLocation, areaServed. Añadimos FAQ sobre envíos y devoluciones. Monitoreo de respuestas sobre precios en 5 regiones. Resultado: inclusión en bloques de respuestas con precios en 3 regiones en 45 días; retorno de usuarios desde respuestas AI +18%.
Caso 3: Servicio local — fortalecimiento de la confianza regional
Tarea: consultas "cerca de mí" y leyes regionales. Acciones: páginas de destino locales con direcciones, teléfonos, horarios y marcado localBusiness; en FAQ — leyes y plazos locales. Resultado: citación en YandexGPT y Gemini en respuestas regionales, leads desde fuentes AI +29% en un trimestre.
FAQ: 10 preguntas profundas
¿Cuál es la estructura mínima de la página para que LLM comience a citarnos?
Respuesta corta con fecha, HowTo con 2-7 pasos, FAQ de 6-10 preguntas, autoría clara y reviewedBy, fecha de actualización vigente, JSON-LD (WebPage+FAQPage+HowTo o Product). Además, identificadores estables @id y atributos locales.
Si ya tengo un tráfico SEO fuerte, ¿necesito LLMO?
Sí. Las respuestas AI acortan el camino del usuario y redistribuyen clics. Incluso con un SEO fuerte, la ausencia de citaciones en la búsqueda AI reduce la cuota de atención y el reconocimiento de la marca.
¿Con qué frecuencia actualizar "respuestas cortas"?
Al cambiar hechos: 1) nuevas cifras, 2) nuevos plazos o precios, 3) actualización de normas. De lo contrario, se recomienda una auditoría trimestral con fijación de dateModified y changelog.
¿Interfieren el paywall y la autenticación en la recuperación?
Parcialmente. Mantén los datos clave y la sección de ayuda en acceso abierto. La analítica profunda puede quedarse bajo autenticación, pero proporciona un resumen público y datos estructurados.
¿Se requieren páginas separadas para cada país?
Si las reglas, precios, plazos o idioma varían — sí. Utiliza hreflang, inLanguage, priceCurrency, localBusiness, applicableLocation, areaServed y datos de contacto locales.
¿Cómo manejar datos contradictorios en la industria?
Describe rangos y condiciones, menciona fuentes, y señala claramente la metodología de cálculo. Tal transparencia incrementa la confianza y la probabilidad de citación.
¿Qué es más importante: enlaces o datos estructurados?
En LLMO, es más importante la capacidad de extracción y verificabilidad de los hechos. Los enlaces y menciones siguen siendo relevantes como señales generales de autoridad, pero sin estructura, el modelo no considerará el contenido en la respuesta.
¿Cómo acelerar la inclusión de actualizaciones en respuestas AI?
Mantén sitemaps frescos y un feed de cambios, indica dateModified, utiliza endpoints con parámetros importantes, y asegúrate de tener códigos de respuesta correctos y ETag/Last-Modified.
¿Por qué el monitoreo requiere proxies de diferentes regiones?
Porque los buscadores AI personalizan las respuestas según GEO: fuentes, precios, unidades, restricciones legales. Resultados de un solo país no son representativos de otros. Los proxies móviles proporcionan el contexto de red requerido de subredes operadoras reales.
¿Cómo controlar la estabilidad del monitoreo?
Registra IP y región al inicio de cada ejecución, verifica el entorno usando herramientas de "Verificación de IP", "Prueba de fuga de DNS" y "Comprobador de Proxies", utiliza una huella digital de navegador única (generador en el sitio), selecciona regiones de salida a partir del mapa de latencias. Rota IP según un horario o a través de API, como en MobileProxy.Space.
Conclusión: resumen y próximos pasos
LLMO es un nuevo escritorio para los equipos de contenido y producto. Para aparecer de manera consistente en citas de buscadores AI en 2026, necesitamos: 1) adoptar una estructura de páginas answer-first y modular, 2) comunicarnos con los modelos usando el lenguaje de schema.org y entidades estables, 3) asegurar idoneidad técnica y frescura, 4) localizar hechos y atributos según GEO, 5) establecer monitoreo de diferentes regiones utilizando proxies móviles. Prácticamente: toma un clúster prioritario de consultas, organiza páginas según el marco APEX, implementa JSON-LD con autoría y atributos GEO, establece un feed de cambios y analiza los registros de bots, lanza un monitoreo de respuestas en ChatGPT, Perplexity, Claude, Gemini, YandexGPT a través de un navegador headless. Para obtener cortes regionales confiables, utiliza proxies móviles con rotación por temporizador, API o enlace. El servicio MobileProxy.Space ofrece una amplia selección de IP y países, HTTP(S) y SOCKS5 simultáneamente, 3 horas de prueba gratuita y soporte 24/7; el código promocional YOUTUBE20 proporciona un 20% de descuento en la primera compra. No busques "trucos mágicos": ganan la sistematicidad, hechos, transparencia y contexto local. Cuanto más fácil sea para el modelo verificar tu página y extraer de ella una respuesta exacta, mayor será la probabilidad de ver tu dominio entre las citas de los buscadores AI.
