Знакомимся с библиотекой Puppeteer

Puppeteer – одна из Node.js-библиотек, работа которых направлена на программный просмотр интернете. Ее повсеместно используют те, кто планирует с нуля создать парсер на Node.js. Puppeteer – ближайший аналог и конкурент библиотеки Cheerio. Сейчас мы более подробно познакомимся с тем, что представляет собой данная библиотека, какими функциональными возможностями она наделена, ее преимуществами и недостатками. Также пошагово рассмотрим процесс создания парсера на Puppeteer. Подскажем, как организовать безопасную работу при парсинге данных с использованием мобильных прокси.
Функциональные возможности библиотеки Puppeteer
У Puppeteer есть достаточно много особенностей, которые пользователи смогут оценить на практике. Вот основные функциональные возможности библиотеки:
- В Puppeteer предусмотрен набор инструментов для автоматизации браузера. Вы сможете получить доступ к движку поисковой системы (в своем большинстве используется Chromium. К слову, в Cheerio подобного не предусмотрено. Наличие доступа к протоколу DevTools для управления Chrome.
- Может выполнять JavaScript, что позволит выполнять парсинг даже динамических страниц, в частности одностраничных сайтов (SPA).
- Библиотека Puppeteer может напрямую взаимодействовать с сайтами. Это значит, что она сможет буквально нажимать кнопки, вводить данные, заполнять стандартные формы ввода и пр.
- Наличие передовой кривой обучения. Обеспечивается это очень широкими функциональными возможностями. Часто будет требоваться использование асинхронного кода, а именно обещания/ожидания (в асинхронном режиме).
- Быстрая и простая установка библиотеки при помощи npm или Yarn. Очень высокое быстродействие.
- Огромный набор инструментов для управления производительностью: запись производительности при выполнении и само нагрузки, регулирование производительности центрального процессора с целью имитации функционирования на мобильных гаджетах, создание скриншотов и многое другое.
Все это позволяет с уверенностью говорить, что Puppeteer имеет массу возможностей и удобств, которые смогут оценить специалисты в своей повседневной работе.
Преимущества и недостатки Puppeteer
Среди основных преимуществ, которые обнаружили для себя пользователи библиотеки Puppeteer стоит выделить:
- эффективное решение для работы с безголовым браузером Headless Chrome;
- простая, быстрая установка, несложное использование, логически выстроенный интерфейс;
- предусмотрена поддержка legacy-версий Node.js >= 6;
- есть поддержка расширений: как вариант, можно задать библиотеке настройки по использованию AdBlock и Puppeteer избавит вас от необходимости просмотра назойливой рекламы;
- наличие высокоэффективного API для управления большим количеством процессов.
Но, наряду с преимуществами есть и недостатки. В частности, в данной библиотеке нет таких top-level функций, как синхронизация паролей и закладок, аппаратное ускорение, поддержка профилей и пр. К существенным «минусам библиотеки относят также программный ребрендинг: все отрисовки и выселения осуществляются непосредственно на пользовательском центральном процессоре. Но есть информация, что специалисты сегодня активно работают над устранением данной проблемы. Также нет поддержки аудио- и видео.
Последовательность действий по созданию парсера в Puppeteer
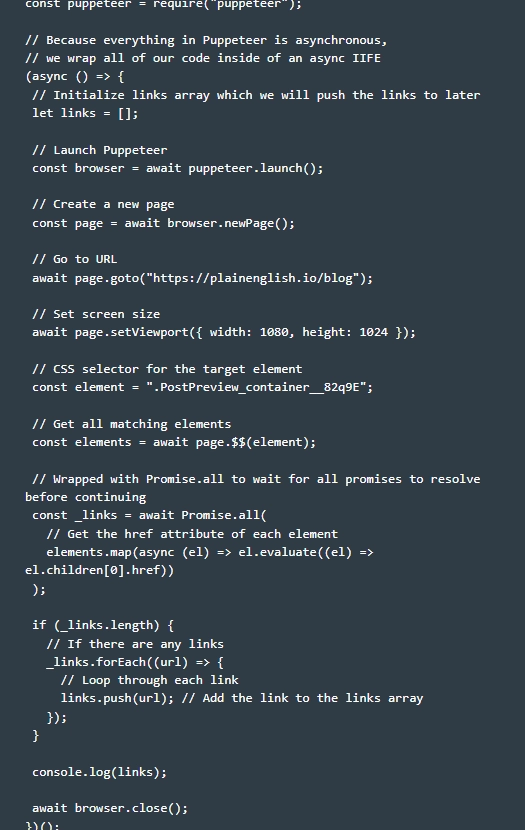
Работу по создания парсера в Puppeteer необходимо начать с создания папки для хранения данных кода, а также инициализации package.json. Папка создается классическим способом. Далее необходимо внутри парсера запустить npm init -y либо же yarn init исходя из того, на чем же остановился ваш выбор: на npm или yarn. На этом предварительные работы завершены: у нас есть папка для кода и активированный файл package.json. теперь можно переходить непосредственно к работам с Puppeteer. Здесь вам предстоит реализовать шаг за шагом следующие действия, следуя нашей инструкции:
- Устанавливаем библиотеку Puppeteer на своем компьютере. Выполняется это запуском следующих команд:

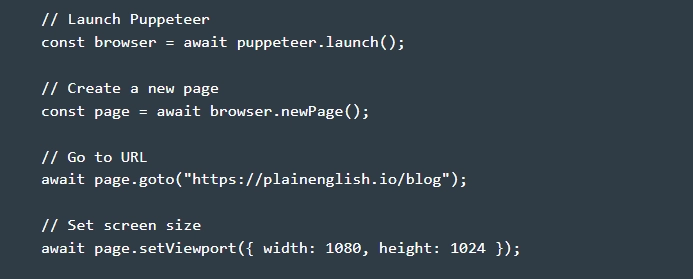
- Готовим парсер к работе. Заходим в папку, которую мы создали на предыдущем этапе и в ней создаем файл, присваивая ему имя puppeteer.js. Для того, чтобы начать парсинг интернет-страниц при помощи библиотеки Puppeteer, вы можете воспользоваться базовой структурой кода. Обратите внимание: работы выполняются после того, как библиотека будет уже установлена.
- Создаем IIFE – выражение функции с немедленным выводом. Обратите внимание: работа с библиотекой ведется в асинхронном режиме, то есть в самом начале необходимо будет вставить опцию async. На практике это будет выглядеть следующим образом:
- Теперь внутри асинхронного IIFE создаем пустой массив ссылок. Это необходимо для того, чтобы в последующем можно было бы реализовать захват линков из блога, из которого вы планируете собирать данные. Для этого выполняем следующую команду:
- Хотите контролировать работу библиотеки в режиме реального времени? Тогда вам необходимо передать в качестве параметра опцию headless: false. Сделать это можно следующим образом:
- Запрашиваем данные. На этом этапе необходимо задать то, на какой селектор будет направлен ориентир. В данном случае это будет выглядеть так:
- Выполняем его запуск. Это некий эквивалент querySelectorAll() для нашего целевого элемента. Выглядит он как
- Выполняем обработку данных. На данном этапе наши элементы уже находятся на хранении внутри основных элементов, нам необходимо все их сопоставить для того, чтобы в итоге извлечь свойство href. Выполняется это следующими командами:
- Обратите внимание: в рассматриваемом примере у нас присутствует такой параметр, как el.children[0] – это первый дочерний элемент из целевого элемента, представленный в виде тега – того тега, который в результате мы и хотим получить. Теперь переходим по отдельности к каждому из отображаемых элементов и перемещаем в наш массив ссылок уже их значения. Данная работа будет выглядеть так:
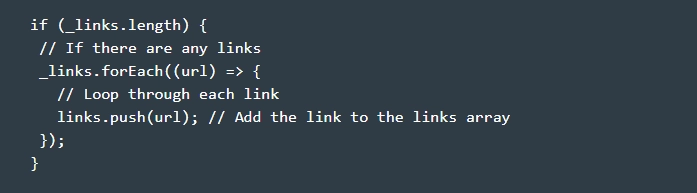
- Выводим ссылки в консольный журнал console.log командой console.log(links), а далее закрываем браузер командой await browser.close(). Закрыть браузер стоит обязательно! В противном случае вы просто спровоцируете зависание терминала.
- Выводим конечные результаты. После того, как все описанные работы будут выполнены, вам останется открыть терминал из папки парсера и запустить node.js puppeteer.js. Данная команда запустит на выполнение весь код, хранящийся в папке puppeteer.js. Обратите внимание: при этом на консоль должны быть выведены URL-адреса из нашего массива ссылок. То есть на своем экране вы должны увидеть нечто подобное:





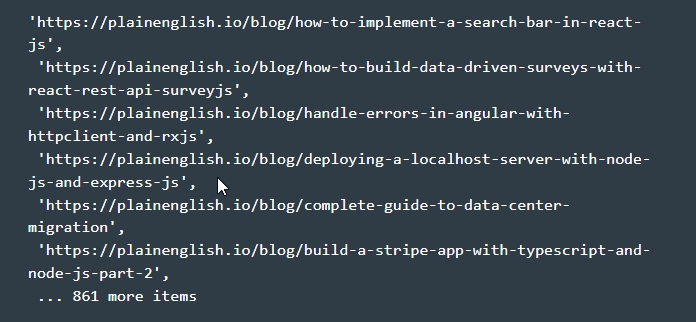
На этом работы по парсингу данных с использованием библиотеки Puppeteer завершены. Еще раз хотим обратить ваше внимание на то, что в вашем распоряжении действительно мощный инструмент для сбора данных. В нем содержится огромный набор API для Web Scraping, а также автоматизации многих браузерных задач. С его помощью у вас появятся неограниченные возможности для извлечения информации с различных сайтов, формирования скринов, в том числе и PDF-файлов, а также решения множества иных производственных задач.
Вот только надо понимать, что неограниченные возможности для работы вы получите только в том случае, если дополнительно к работе подключите мобильные прокси. Этот инструмент обеспечит вам анонимность и безопасность работы в сети, позволит избежать бана в результате многопоточных действий, а также поможет обойти региональные блокировки, установленные тем или иным государством на региональном уровне. Вот только в работе стоит использовать исключительно приватные мобильные прокси – бесплатные серверы ввиду общей доступности с поставленной задачей никак не справятся. От них вы получите больше проблем, чем решений.
Выбираем лучшие мобильные прокси для работы с Puppeteer
Если вы находитесь в процессе поиска надежных приватных мобильных прокси для работы с библиотекой Puppeteer и интернетом, в целом, рекомендуем обратить внимание на предложение от сервиса MobileProxy.Space. Клиенты компании получают:
- приватный выделенный канал с неограниченным трафиком и доступом почти что к миллионному пулу IP-адресов.
- быструю и простую настройку автоматической смены IP-адреса по таймеру в интервале от 2 минут до 1 часа или же принудительную смену адреса по ссылке с личного кабинета;
- одновременную работу по протоколам HTTP(S) и Socks5, что обеспечивается подключением к параллельным портам;
- возможность в рабочем процессе менять геолокацию, оператора сотовой сети.
- круглосуточную техническую поддержку.
Больше информации о мобильных прокси MobileProxy.Space, актуальных тарифах предлагаем узнать здесь.