Comprehensive Traffic Emulation in 2026: Acting Legally, Safely, and Effectively
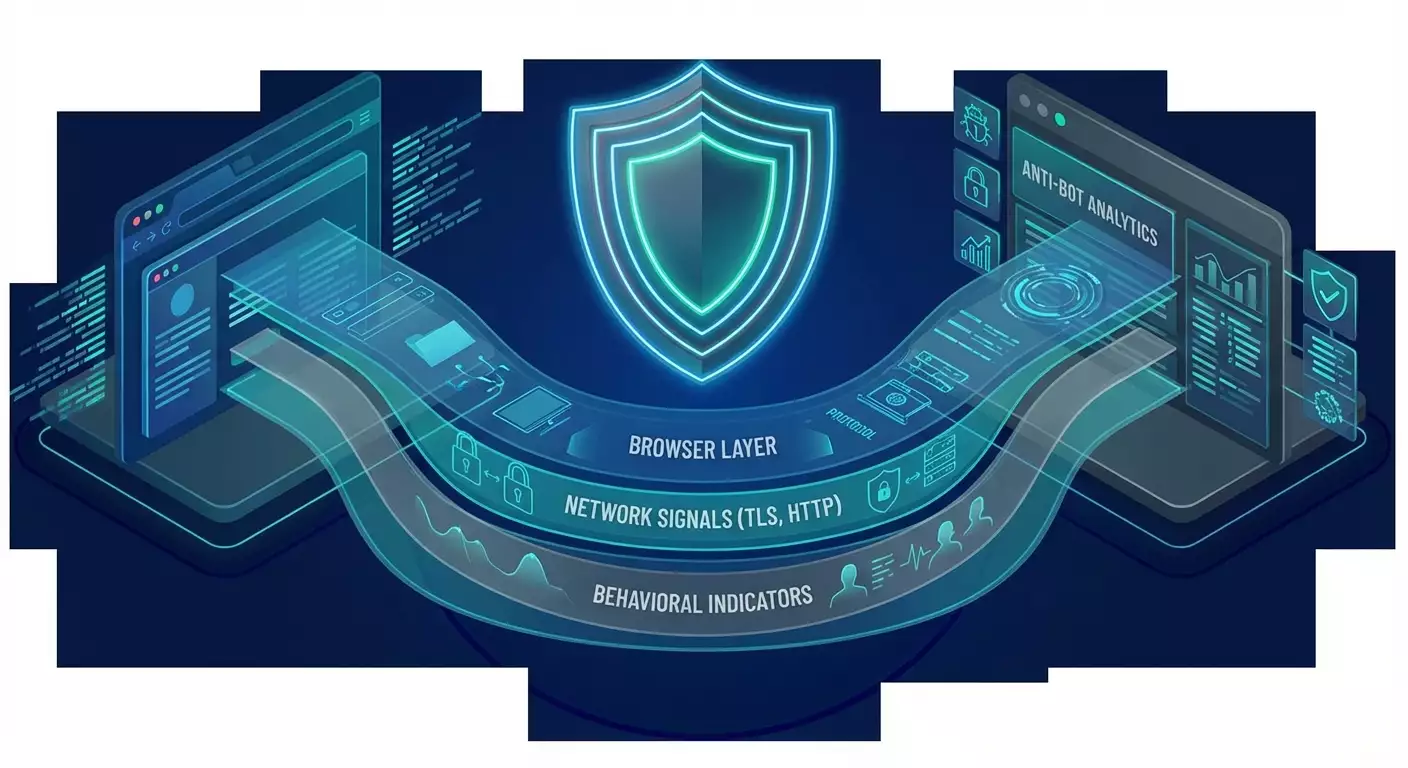
Table of contents
- Introduction: why this topic matters and what you'll gain
- Basics: fundamental concepts
- Diving deep: how anti-bot systems read your traffic
- Practice 1: legal and ethical framework
- Practice 2: designing an 'honest' client
- Practice 3: traffic hygiene and load
- Practice 4: infrastructure of trust, observability, and security
- Practice 5: engaging with site owners
- Practice 6: data quality and scheme resilience
- Common mistakes: what not to do
- Tools and resources: what helps you act right
- Case studies and results: how an ethical approach works
- Faq: frequently asked questions
- Conclusion: how to act next
Introduction: Why This Topic Matters and What You'll Gain
The year 2026 brings stringent demands for web automation: anti-bot systems, regulatory norms, and user expectations. The use of advanced behavioral profiles and network signals for risk assessment is on the rise. Simple ‘proxy plus script’ methods are no longer effective; at best, they are inefficient, and at worst, they violate laws and lead to blocks, legal claims, and reputational damage. This guide is for those creating legitimate and sustainable data collection and synchronization processes: marketing analytics, availability and price monitoring, QA and testing, open data research, and competitive intelligence within the legal framework.
We will explore how modern anti-bot platforms build visitor profiles by analyzing dozens of signals simultaneously, why simply changing your IP and User-Agent is insufficient, and why the strategy of 'full masking' is unsustainable. Instead of technical instructions for bypassing protections (we won’t provide those), you’ll receive practical architectural solutions: a legal and ethical framework, designing a 'honest' client, traffic hygiene, observability infrastructure, and resilience. The result is a stack that operates reliably, predictably, and does not conflict with resource owners.
Basics: Fundamental Concepts
What is Anti-bot Profiling? Services like Cloudflare Bot Management, Akamai Bot Manager, DataDome, and HUMAN Security combine network and behavioral signals to assign a risk assessment to requests. The resolution could be to allow, slow down, present a challenge, or block.
Key Signals in general terms: order and content of HTTP headers, characteristics of the TLS handshake (JA3, JA4, JA4H fingerprint families), protocol version (HTTP/2, HTTP/3/QUIC), ALPN, supported ciphers, as well as browser characteristics (Canvas/WebGL, AudioContext, font list, timezone, language, screen size), behavior (scrolling speed, cursor movement, pauses between events), network context (ASN, geo, IP reputation), session history, and cookies.
Good Faith Automation means data collection in compliance with the law, site terms, and user expectations. Yes, automation is a dual-use tool. But it is the boundaries of application that determine what is permissible. We only discuss legal scenarios and safe practices.
Why This Matters: Attempts to 'emulate a real user' to bypass protections are becoming not only technologically more complex but also riskier legally. However, a well-designed process with permissions and transparent identification provides stability, partnerships, and higher data reliability.
Diving Deep: How Anti-bot Systems Read Your Traffic
Network Signals
TLS Fingerprinting reflects a set of supported ciphers, extensions, field order, and handshake behavior. The JA3 and JA4/JA4H families allow systems to match clients with typical implementations (browsers, libraries). Discrepancies between TLS characteristics and the declared User-Agent are bright indicators of automation.
HTTP Stack offers a rich ground for profiling: header order, formats, the presence of rare or, conversely, missing standard headers. The shift to HTTP/3 (QUIC) has enhanced client distinguishability through transport features and timings.
Browser and Behavioral Signals
Canvas/WebGL, AudioContext, font properties, screen sizes, pixel density, timer precision—these help correlate sessions and distinguish a real browser from automation tools. Behavior (scrolling dynamics, clicking rhythm, reaction to content) allows for assessing the 'naturalness' of interactions.
Integrity and Validation
Challenges and Validation: Private Access Tokens (the evolution of Privacy Pass), risk-adaptive challenges without CAPTCHAs, device security signals, and OS. Device attestation and ecosystem integrations confirm that the client is honest and unmodified.
Correlation and Reputation
Systems link events into a graph: IP, cookies, device parameters, rate of network changes, and repeatability of routing patterns. Reputation feeds and negative indicators (including 'gray' residential networks) increase risk.
Conclusion
Anti-bot is not a single test. It is an ensemble of signals plus a risk model. Replacing one characteristic is not enough. Inconsistencies in patterns increase suspicion. Thus, betting on 'masking' fails compared to betting on legitimacy, partnership, and the technical quality of traffic.
Practice 1: Legal and Ethical Framework
Start not with code, but with permissions and frameworks. This saves months and prevents blocks.
Checklist Before You Begin
- Define the legal basis: public data, licenses, consent, contract.
- Review the site’s terms of use: is automation allowed, to what extent?
- Check robots.txt and meta directives. Respect prohibitions and rate limits.
- Conduct a Data Protection Impact Assessment (DPIA) if personal data is involved.
- Designate a contact person for escalations and site owner requests.
- Set up 'safe brakes': the ability to immediately stop traffic upon complaints.
Transparent Identification
Verify yourself: use a recognizable agent identifier and a reverse communication channel. This increases trust and chances of whitelisting. Clarify acceptable activity windows, frequency, and format of requests. Yes, this is less flashy than 'masking', but it wins strategically.
Working Through Official APIs
If an API is available—use it. Even paid channels are often cheaper and more reliable than fighting blocks and reconstructing outlines. When there’s no API, discuss partner export.
Practice 2: Designing an 'Honest' Client
Instead of imitation—focus on consistency and quality. Build automation on full-fledged browsers, and handle state and data carefully.
Browser as the Engine
- Use modern browser engines (Playwright, Selenium, Puppeteer) in configurations that closely match standard user environments.
- Avoid hiding automation and interfering with integrity signals. This reduces the risk of conflicts and traps.
- Plan 'human' activity windows: daytime hours per the relevant time zone, reasonable pauses, no flat 'machine' frequency.
Locale and Settings Consistency
- Align Accept-Language, timezone, and proxy geography with the subject area and jurisdiction.
- Fix a stable configuration per session, avoiding random parameter fluctuations.
Cookies and Sessions
- Manage the cookie jar according to the rules: save the session where permitted, isolate contexts.
- Adhere to requirements for retention and deletion: encrypt, limit lifespan, comply with data deletion requests.
Parsing Without Fragility
- Operate on data through robust selectors, semantic markers, data attributes.
- Build a plan B: if the structure changes, reduce frequency, send notifications, do not increase pressure on the site.
Practice 3: Traffic Hygiene and Load
Clean, predictable, moderate traffic is a signal of good faith and a guarantee of stability.
Rate Control
- Define thresholds: RPS, parallelism, volume per hour/day. Implement token buckets and adaptive backoff.
- Add jitter to intervals, avoid rigid periods and sharp spikes.
- Respect site restrictions: dynamically read robots rules and public directives.
Networks and Proxies
- Use only legal, transparent networks. Avoid 'gray' residential sources that pose a risk of malicious nature.
- Align IP geography with business logic. Better to have fewer but higher quality.
- Ensure IP stability for sessions when justified.
Request Efficiency
- Cache results, respect ETag and Last-Modified, honor Cache-Control.
- Do not request excess: narrow samples, incremental updates, diff strategies.
- Minimize loading heavy media if the goal is text data.
Practice 4: Infrastructure of Trust, Observability, and Security
Technological maturity distinguishes sustainable automation from the 'until blocked' tactics.
Observability
- Metrics: RPS, p95 latency, error types, retry attempts, frequency of 4xx/5xx errors, deviations from the baseline.
- Logs: structured events, session correlation, anonymization when necessary.
- Tracing: end-to-end tracking of scenarios and dependencies.
Risk Management
- Alerting on thresholds and anomalies (CAPTCHA spikes, increased failures).
- Emergency stop button and degradation policies: less parallelism, more pauses, pauses on specific domains.
- Regular compliance reviews: legal, technical, operational.
Security
- Secrets in vaults, key rotation, the principle of least privilege.
- Environment isolation, access control, secure updates of browsers and drivers.
Practice 5: Engaging with Site Owners
Make the resource owner an ally.
- Discuss windows, limits, priorities, formats of data delivery.
- Propose to enter through allowlists, API keys, signed tokens.
- Agree on caching policies and load minimization.
- Provide contact information and responsible response policies.
Practice 6: Data Quality and Scheme Resilience
The goal is not just to 'scoop' but to 'obtain quality and repeatability'.
- Quality control: deduplication, schema validation, monitoring structural drift.
- Parser versioning, canary releases, automated rollbacks.
- Cataloging sources, attributing data lineage, auditing changes.
Common Mistakes: What Not to Do
- Try to hide automation and replace low-level client integrity signals. This increases escalation risk and violates terms.
- Sharp rotation of User-Agent and geo without logic and consistency. This appears unnatural.
- Ignore robots.txt and public instructions. This undermines trust.
- Use 'gray' proxies and 'cheap' residential networks. The reputational risks are enormous.
- Collect personal data without a basis and DPIA. The legal consequences can be critical.
- Escalate aggression upon blocking: increase load, multiply requests. Instead, you need to decrease pressure and contact the owner.
Tools and Resources: What Helps You Act Right
Browser Automation
- Playwright, Selenium, Puppeteer—in standard, transparent configurations.
- Profile management: stable profiles, predictable session lifespan.
Orchestration and Load
- Queues and schedulers: resilient task distribution, limiting parallelism, jitter.
- Rate limiting and backoff as built-in mechanisms.
Observability
- Metrics and logs with request and session context, alerting on CAPTCHAs and blocks.
- Synthetic monitoring window of low intensity for early change detection.
Legal Compliance
- Data retention policies, DPIA processes, consent logs.
- Incident processing and data deletion request standards.
Note: There are tools and research available for TLS profiles and browser fingerprints. Apply them only for your own security and compatibility tests, not for bypassing others' protections. Our guide focuses on sustainable, permitted approaches.
Case Studies and Results: How an Ethical Approach Works
Case 1: Monitoring Inventory with Permission
A retail company negotiated with suppliers for nightly windows and limits of 0.3 requests per second per domain, using Playwright, ETag caching, and diff updates. Result: 99.5% successful passes without CAPTCHA, a 4.7 times reduction in source load, and stable data SLAs.
Case 2: Open City Data
A research team worked only through the API of an open data portal. Where the API did not cover the case, a daily CSV export was agreed upon. Result: zero share of blocks, legal purity, reproducibility of research.
Case 3: QA Testing Behind WAF
The testing team agreed on an allowlist by IP and User-Agent with the website owner. Load windows were scheduled for low traffic, and an emergency stop was in place. Result: predictable test runs, absence of noise in the anti-bot system.
Case 4: Price Analytics Through Partnership
An analytics provider abandoned shadow proxies and 'masking', establishing agreements with 12 marketplaces. Data arrives via API, including historical slices. Result: field quality increased by 18%, update speed improved by 2.3 times, no blocks.
FAQ: Frequently Asked Questions
Can you fully emulate a ‘real user’ to avoid being blocked?
No. Modern systems evaluate dozens of coordinated signals and behavior over time. Additionally, bypassing protections often violates terms and laws. The sustainable way is permissions, transparency, and quality engineering.
Are residential proxies necessary?
Only if it complies with the law, terms, and ethics of the source. In most legitimate scenarios, stable corporate IPs and agreement on limits are sufficient.
Do you need to rotate User-Agent?
There’s no point in chaotic rotation. Consistency and agreement with other client parameters are more important. For transparent automation, use a stable, descriptive User-Agent and provide contact information.
What to do with cookies?
Store them securely, encrypt, limit lifespan, do not share among unrelated projects. Comply with data deletion requests. And use them only where allowed by terms.
What to do in case of blocking or CAPTCHA?
Reduce load, cease retries, contact the website owner. Offer windows, limits, identification options, or transition to API. Do not complicate signals and avoid 'outsmarting' the protection.
Can CAPTCHAs be solved through services?
This may violate terms and ethics. If you frequently see CAPTCHAs, it indicates your scenario is not aligned. Go to the source for permission or adjust frequencies and volume.
How to account for privacy and regulators?
Conduct DPIAs, classify data, minimize field sets, maintain consent logs. Comply with local laws: GDPR, CCPA, and other applicable norms.
Should the timezone and language be adjusted to the IP?
Logical consistency is useful, but not as masking. The main principle is transparency and configuration stability, not trying to deceive profiling.
How to ensure resilience to page changes?
Semantic selectors, version control, canary launches, anomaly alerts, live review of changes. And—quick communication channels with the site owner.
How to assess the load on the source?
Set limits, monitor p95 metrics, error responses, content delivery speed. If performance worsens, reduce frequency and discuss alternatives (caching, snapshots, exports).
Conclusion: How to Act Next
The world of 2026 has made the ‘masking for access’ strategy expensive, risky, and fragile. Modern anti-bot systems see the picture as a whole—from TLS and HTTP stack to dynamic behavior and device attestation. In these conditions, a different approach wins: permissions, transparent identification, moderate load, quality engineering, and partnership. Build a legal framework, establish observability and 'safe brakes', work through full-fledged browsers without attempts to hide automation, and respect source rules and infrastructures. The result—resilience, predictability, and trust. And trust over the long haul always beats masking.
