SEO crawling, crawl budget optimization: what you need to know about it

Crawling – to crawl – this is a technology for detecting new or updated pages, collecting information from them. The data obtained in this way will be loaded into the index of the search engine, on the basis of which the search results are generated. This procedure belongs to one of the methods of SEO optimization, in particular, it is the first stage of data collection. Its implementation – this is the task of special bots called crawlers. They are also called search robots, spiders, bots.
Now let's get acquainted in more detail with the crawling technology itself, tell you what tasks the search bot solves and what the crawling budget is. We will show you where you can find data on the budget of your site and how to optimize it. Let's dwell on such a moment as mobile proxies, in particular, we will tell you how to maximize the effectiveness of SEO-optimization thanks to additional connection to the operation of this server. But, first things first.
What tasks does crawling and search robot solve
The duties of a crawler include solving quite serious tasks in the field of search results:
- Continuous monitoring and comparison of indexed URLs with those already in the bot's list.
- Removing from the list of takes. This eliminates the possibility of downloading the same page several times.
- Adding to the list for re-indexing pages that have been updated.
Yes, the tasks that a search robot solves include everything that a person can do on their own when going through links, browsing Internet resources. But the speed of work in this case will be much higher. Moreover, data segmentation, processing of blocks in a certain sequence, as well as simultaneous work with huge data arrays will already be provided here. If you are interested in the topic of automating actions on the network for the purpose of business development, we suggest that you familiarize yourself with such a concept as browser automation.
Using – already a standard in networking. They are widely used by search engines. In particular, Google currently has 4 bots in service:
- Googlebot. This is the main search robot of the system.
- GooglebotImages. A bot focused on working with pictures.
- GooglebotNews. Its activity is aimed at scanning the news.
- Googlebot Video. Scans multimedia data, in particular video files.
Such a concept as crawling will also be relevant to all those who have their own website. But here we are talking more about such a thing as a crawl budget. Let's dwell on this moment in more detail.
What is a crawl budget and why is it important to manage it properly
Let's start with a term. So, the crawl budget – this is the limit that is given to each Internet resource for crawling by search robots. In simple words, this is how many pages of your site can be indexed in a given period of time. This budget is individually calculated for each resource, depending on how available its server is and user demand.
Unfortunately, not all website owners pay enough attention to this. If you are the owner of a small online store, a narrow-profile information portal and are independently engaged in its optimization and promotion, then you have no reason to worry about the crawling budget. But for the owners of large Internet projects, those who involve a large number of specialists in their promotion, it is very important to pay worthy attention to optimizing indexation limits. There is a possibility that some of the site's pages will simply be out of the attention of bots, that is, they will not get into the search results in principle.
That is, optimization of the search budget – it is a way to direct resources in the right direction, rather than wasting them. As an example: the Google search engine has set a limit of 150 pages for indexing your site. For a small resource, this is more than enough. But if you have a huge platform on which dozens or even hundreds of new pages appear every day, then this is catastrophically small: if all resources are directed to new pages, then what about those that were posted earlier? All this can lead to general problems with site indexing. Did you run out of budget on a page? This completes the work of the crawler – all other pages are automatically excluded from indexing.
Checking your site's crawl budget
Google keeps a history of the limits that sites are given. To find out the data for your resource, you will need to look at crawl statistics in the Google Search Console service. To do this, you need to go to the "Legacy Tools and Reports" menu tab. Here we select the option "Scan statistics".
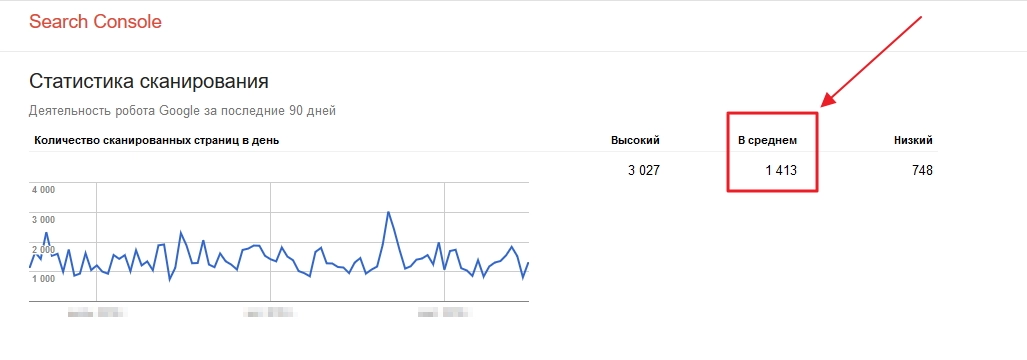
After that, graphs with statistics will open in a new window. You need to pay attention to the very first of them, in particular the "Number of scanned pages per day." This parameter will be the crawl budget of your site. We want to warn you right away that this indicator – not a static value. It can be seen from the graph that on one day this parameter will be higher, on the other, on the contrary, lower. Therefore, we would recommend paying attention to the average indicator – next to the chart, the indicators of the highest, lowest and average limits will be displayed separately.
Ways to optimize your crawl budget
We have already identified the fact that crawling is, in fact, the indexing of a site. That is, it is precisely the mistakes made when setting up the indexing of pages that will entail an accelerated waste of the budget. And their elimination – this is one of the important tasks that an SEO-specialist will face at the stage of website promotion. In particular, the following recommendations are recommended:
- Set up sitemap.xml and robots.txt files properly. These are the files that are actively used by search bots for the correct indexing of the site. It is they who help the robot to build a resource hierarchy for itself, to see the overall picture of the content organization. What do you need to do? First – clean sitemap.xml. Here garbage links are removed (contain scan errors, redirects), duplicates. The fact is that bots, among other parameters, also evaluate the quality of URLs. That is, you should leave only useful – pages in the sitemap. no trash. But in the robots.txt file, you will need to set the last-modified mark for pages to which you have not made any changes since the last indexing. So you exclude the possibility of re-indexing pages.
- Optimize redirects. You need to understand that every redirect – it's a waste of your crawl budget. Just imagine how many redirects your bot will need to go through in order to get to the page that needs to be indexed. There is a possibility that he simply does not have enough limits to get to her. That is, double-check all the redirects on your site to make sure you need them all. Everything superfluous – delete immediately.
- Maximum resource loading speed. The less time your site takes to load, the faster the crawler will index it. And this means that within the same number of connections, it will be possible to work out more pages. By the way, you have the opportunity to quickly and free of charge test Internet speed.
- Correct page linking. It is necessary to optimize it for higher efficiency of the bot. It is necessary to use diverse and unique links for keywords, add anchors to pages of similar topics.
- Pay attention to building external link mass. An established fact: the more external links that lead to your site, the more often a search robot will look at it.
- Include dynamic rendering in the job. We are talking about Google's own development, which involves the creation of a separate HTML version of the site specifically for the search robot. Often JavaScript is used. This can significantly speed up and simplify indexing.
What about mobile proxies?
Promotion of any Internet resource requires multi-threaded actions from SEO specialists, to which anti-fraud systems react extremely negatively. And only by ensuring the anonymity of working with each individual resource, you can bypass these prohibitions. Also, one should not forget about regional restrictions established at the legislative level. Mobile proxy servers will help you avoid all sorts of restrictions and ensure stable and efficient website promotion. In addition, they can positively affect the site loading speed, building up external link mass.
Using mobile proxies from the MobileProxy.Space service in your work, you get:
- Personal channel with unlimited traffic and access to almost a million IP-address pool;
- absolute security and anonymity of networking, the ability to effectively bypass regional blocking;
- higher connection speed, which is ensured by the use of the technical capabilities of cellular network operators, data caching;
- the ability to set up an automatic change of IP-address (by timer) or to change it forcibly, via a link, as soon as the need arises, and you can also choose any geolocation and cellular network operator;
- simultaneous operation via HTTP(S) and Socks5 protocols, which is ensured by their connection via parallel ports.
Moreover, at any time you can contact technical support specialists for additional advice and assistance in troubleshooting problems in the operation of mobile proxies. With such a reliable assistant, your actions to optimize your crawling budget and work on website promotion, in general, will be unlimited. Using the link https://mobileproxy.space/en/user.html?buyproxy you can learn more about the features and functionality of mobile proxy. We also offer a free 2-hour trial to make sure that there is no better solution for your work even before purchasing the product.
