Using folder structures as a cipher: technology without file storage

Every day, the issue of ensuring security when working on the Internet, reliably hiding files with personal information is becoming more and more relevant for the consumer market. Before specialists have time to create new technologies designed to form reliable protection for user devices, hackers intensify their activities and find ways to bypass all these restrictions. As a result, a kind of vicious cycle is created. Users have to constantly monitor software updates, perform appropriate installations to prevent or at least minimize the likelihood of hacker attacks on personal devices.
However, along with classic solutions in the field of computer security, a lot of work is being done to find more reliable and stable ways to ensure the protection of personal data. Thus, relatively recently, the Trustedsec organization conducted a study called Hiding in Plain Sight, which literally translates as “hiding in plain sight”. Here we are talking about a rather unusual fileless method of hiding data using a folder structure. The company's specialists managed to prove in practice that you can hide an elephant in an anthill.
As part of today's review, we will get to know this technology in more detail. We will tell you how you can organize the concealment of data without files and how it works in practice. We will tell you what limitations and difficulties you may encounter when performing these works. We will describe how decryption of information is performed in this case. We will tell you how to apply this technology in practice. This information will be useful for those who are thinking about such a question as Internet protection and would like to prevent unauthorized access to their device.
What is fileless data storage and how does it work
In its classic presentation, all antivirus software presented on the modern market, as well as all solutions implemented in the Data Loss Prevention system (DLP solutions) are focused on files, where information is directly stored in them. Trustedsec specialists completely destroyed this paradigm in their research. They bet on the fact that folders can be used as a kind of container for storing this very data. That is, in this case, the folders themselves will not contain information. Hence the name fileless storage - there is data storage, but no files. But their names will become the basis for data encoding.
As part of the study, a special folder structure was created in the form of a hierarchy. That is, one folder was located inside another, and so on. At the same time, each of them had its own unique name, which is one of the elements of this very data, which is planned to be safely stored. Imagine that you have a folder structure like this: “Folder.1/Folder.2/Folder.3/Folder.4/Folder.5”, and so on. Here we can continue almost indefinitely. But what happens if we remove the separators between these folders? As a result, we will have a continuous line “Folder.1 Folder.2 Folder.3 Folder.4 Folder.5”, which can essentially contain information.
Now imagine that we assign each folder a corresponding name. Alternatively, folder 1 will be called "This", folder 2 - "Autumn", folder 3 - "Pleases", folder 4 - "Us", folder 5 - "Warmth". In this case, the hierarchy of all these folders will look like this "This/Autumn/Pleases/Us/Warmth". We remove the slash between the folder names and get the phrase "This autumn pleases us with warmth". As a result, we provide data storage, but the folders themselves remain empty, that is, they do not contain files. Of course, in the process of implementation, everything looks a little more complicated, requires the use of additional tools, formats, identifiers. But we hope that you have grasped the essence of the fileless data storage technology.
To eliminate the use of special characters that could arouse additional attention and suspicion, the researchers decided to additionally use a Globally Unique Identifier (GUID). This is a standard format for identifiers that is currently quite actively used in systems. It is just one line containing 32 characters. They are all separated by hyphens. Since each of these elements is chosen randomly, it is impossible to identify a relationship between them, and, as a result, this does not arouse any suspicion.
The image shows a small fragment of text confirming this concept.

We would like to draw your attention to the fact that the text string is currently used exclusively for testing the possibility of organizing fileless data storage. But you can easily replace the source of water with your target file. By the way, we use the modern PowerShell command shell, where the developers managed to implement the best of the features that are presented in analogs, that is, in other popular shells today. With its help, you can easily and quickly read data from a file using the Get-Content tool. It turns out that initially we take all our input data and transform them into a byte stream. As a result, our string is transformed into the following element:
$data_bytes = [System.Text.Encoding]::UTF8.GetBytes($example_data)
After that, our byte stream is transformed into hexadecimal. Now it will look like this: $hexString = ($data_bytes | ForEach-Object { $_.ToString(“X2”) }) -join ‘’.

The next step is to transform the hexadecimal string obtained above into a set of paths that will include folders that use GUIDs (a statistically unique 128-bit identifier) as names. Now we directly create these paths.

As a result, we get a file that is the output of encoded information. Here it is already hidden directly in the paths leading to the folders. And each of the lines presented in this file is a hierarchy of folders. All of them, without exception, will contain one of the elements of our common string that we encoded.
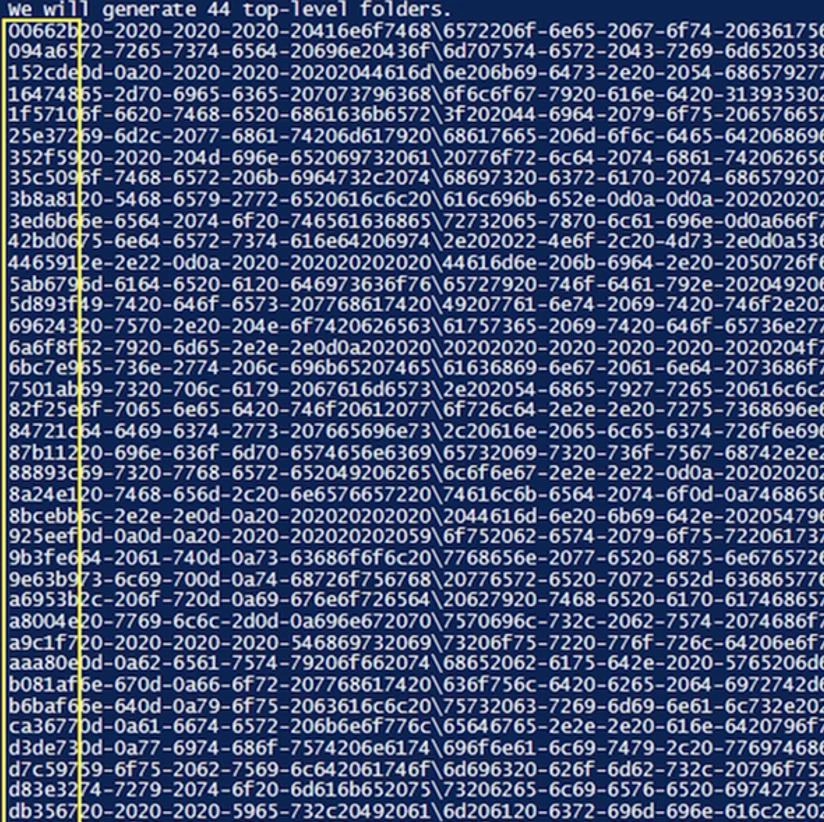
That is, in the end we got 44 folders already at the top level. We would like to draw your attention to the first 6 characters presented in each of the lines. This will be a 6-character randomized hexadecimal code. The system automatically sorts it in alphabetical order and immediately adds it to each line. Thanks to this solution, it became possible to configure sorting by name and output each line of code in the order in which it should originally be placed. But at the same time, the entry itself looks random and it is completely impossible to understand what information is presented in it.
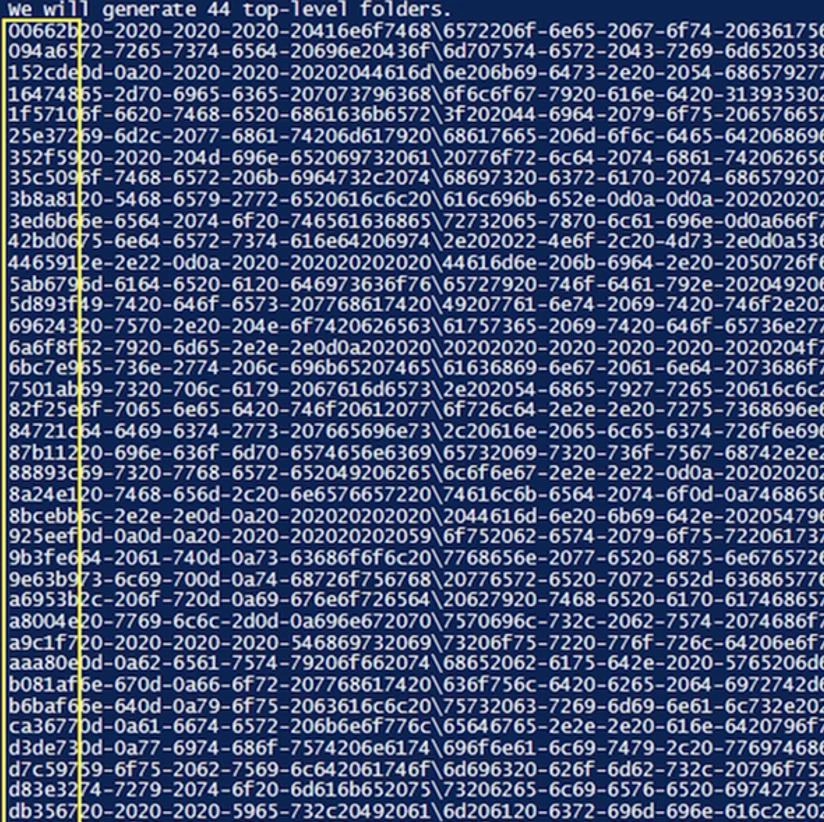
Limitations and problems that can be encountered when implementing this technology
Despite all its apparent simplicity, in practice the technology is quite effective and can give good results in ensuring data security. But still, like any other solutions, there are a number of problems and limitations that you can encounter in practice. And this must be known and taken into account in order not to end up in a difficult situation. Of the most important points, in our opinion, it is worth highlighting 2:
- The presence of restrictions on the path length. In particular, in Windows the current limit is 260 characters. This means that you will not be able to write long phrases in folder names. Here, everything depends on the total number of attachments. So, if you make only 10 folders, then you can come up with a name for each of them in 26 characters. But if there are 20 such folders, then the average name length will automatically decrease to 13. But in most cases, such a hierarchy is more impressive. This means that you need to set the folder names as short as possible. This way you will be able to fit into the specified limit.
- The probability of arousing suspicion. Despite the fact that it is not possible to decipher all these codes hidden in the folder names, the use of pure hexadecimal code in practice can still raise suspicions. In order to minimize the occurrence of such problems, experts still decided to save all the names of all folders in GUID format. This will make them as inconspicuous as possible. And this means that with a high degree of probability they will not attract outside attention.
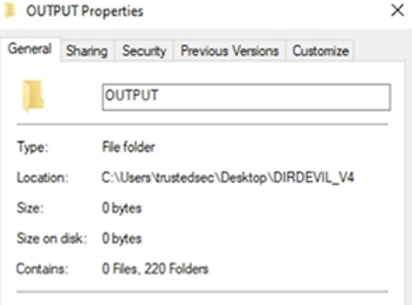
Another point that we would like to draw your attention to is the volume that the folder will occupy on your disk. In our example, 220 folders were used and they occupy 0 bytes on our disk. This means that the implementation of fileless data storage will not negatively affect the consumption of your device's resources.
Now let's talk about how to decrypt hidden information. Otherwise, not only third parties, but also you personally will not be able to use it.
How can you decrypt data stored without files?
Everything that was encrypted before must also be transformed back, that is, decrypted. In order to start the decoding process, we need to pay attention to all the folders located at the top level directly in the target directory. After that, we go into each top-level folder, sorted in the order we need. And then we extract our entire folder structure from them. In this case, our hexadecimal number will be automatically added to the string variable «hex stream». This is enough to read all the paths leading to the top-level folders. After that, the hex stream will be automatically transformed into bytes. After that, it will either be written to the appropriate file or displayed on your computer monitor.
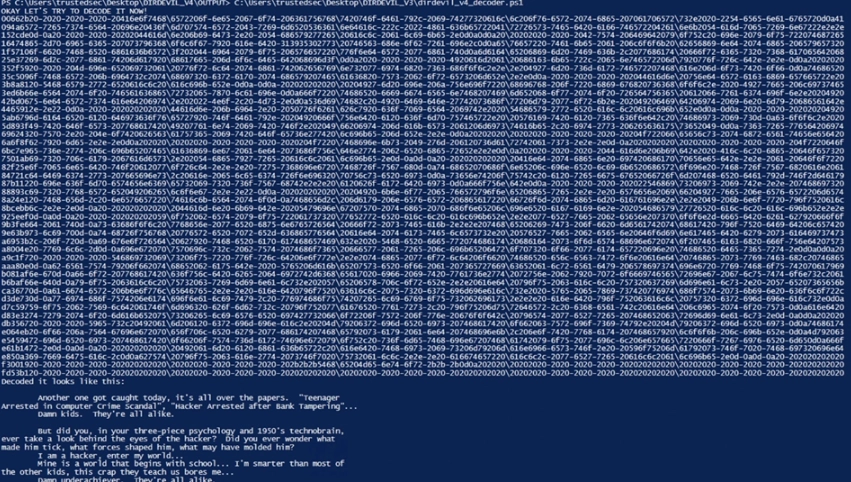
The decrypted text itself is presented below the code. As you can see, there is nothing complicated in decoding data stored without files.
Difficulties with practical application
In practice, fileless data storage can be used in different ways. Here are just a few potential solutions:
- Reliably hide data important to you in the system. In this case, there will be no obvious files on your computer, they will not take up free space and memory.
- Departure from the classic analysis of antivirus programs, which today can rightfully be called static.
- Formation of complex multi-tiered structures that cannot be identified on the user's device or decrypted without the appropriate knowledge and tools.
Despite the presence of quite significant advantages and, one might even say, an advanced solution, there is still one significant drawback that you must be aware of and take into account before planning your work. In particular, the entire process of encoding data in the folder structure on your device will automatically lead to an increase in the total volume of information during the archiving process. Thus, even a regular text file can noticeably increase in size. In the picture you can see how the same text file grew from 1,071 KB to 21,688 KB after the folder structure was applied to it.
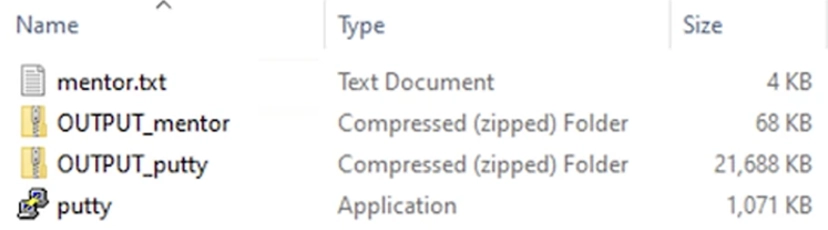
Perhaps this problem will find a solution in the foreseeable future, but for now it looks like this.
Let's sum it up
As you can see, the very idea of using folders, or rather their names, to hide important information is a rather interesting and unusual approach to solving the problem of data protection. But whether this method will be used in practice is deeply questionable, at least today. And the main problem here is that this method is primarily focused on bypassing detection of security tools, and not on solving the main problem - hiding data.
The possibility of using the fileless data storage method in practice is even more questionable because there are already technologies on the modern market that can provide fairly high levels of protection for user devices from all sorts of external threats. In particular, one of the most advanced tools here will be mobile proxies. They are intermediary servers that will pass the entire data flow through themselves, providing the substitution of your real IP-address and geolocation for their own technical parameters. As a result, a completely secure connection to the Internet is formed. Neither the system nor any third parties will be able to identify your device and, accordingly, will not be able to connect to it to gain access to your personal information. Along with providing protection, mobile proxies will also help:
- maintain high confidentiality and anonymity of actions on the network;
- organize work in multi-threaded mode, as an option multi-accounting for the most effective promotion of business in social networks without any risks and restrictions;
- ensure the ability to use programs that automate actions, without fear of running into penalties from the system;
- bypass all sorts of regional restrictions established in a particular country at the legislative level, gain access to any sites.
But in this case, it is very important to choose the most reliable mobile proxies for work. Those that would provide you with maximum functionality of interaction on the network. And one of the best solutions in this market segment today is offered by the MobileProxy.Space service. In this case, you will be provided with a personal channel with unlimited traffic, as well as access to a huge number of IP addresses from real mobile network operators. Thanks to this, your connection will look as natural as possible for the system and will not raise any suspicions. To change the address, you can use a special link stored in your personal account or set a timer to automatically change the IP in the range from 2 minutes to 1 hour. You will also be able to choose the most suitable geolocation for yourself, a mobile network operator, which will become the basis of your new digital identity.
Follow the link https://mobileproxy.space/en/user.html?buyproxy to get to know this mobile proxy in more detail, as well as take advantage of free testing for 2 hours. You will also have a 24/7 technical support service at your disposal, which will immediately respond to user requests and eliminate problems that arise when working with proxies quickly and efficiently. If you have additional questions, with a high degree of probability you will find answers to them in the FAQ section.