Cheerio library for efficient and convenient web-scraping

The work of many specialists on the Internet involves collecting data from websites: marketers, SEO-specialists, SMM-managers, etc. Web scraping can be performed either by scraping or through a ready-made API. But doing this work on your own is not as easy as it might seem at first glance. The fact is that most sites react extremely negatively to the actions of scrapers, putting a lot of effort into blocking their work. We have already talked about how to avoid a ban and ensure stable data parsing – we suggest reading the article «Mobile proxies for Web Scraping».
Now we will dwell in more detail on ready-made tools that optimize, speed up and partially automate your actions. In particular, let's get acquainted with one of the Node.js library – Cheerio. Let's consider its functionality, and also describe step by step how to create your own parser.
Getting acquainted with the functionality of the Cheerio library
Cheerio – one of the libraries for programmatic web browsing. If you want to create your own Node.js parser from scratch, then this is the tool to choose. So, we are talking about an HTML-parser endowed with sufficiently broad functionality that will significantly expand your actions and allow you to get the desired result with minimal time and effort.
Among the main points worth knowing about the Cheerio library, we highlight:
- this library is a DOM parser that can work with files in HTML and XML formats;
- is an implementation of core jQuery built specifically to work with the server;
- Maximum efficiency when working as a parser is ensured by working together with the Node.js client library, alternatively Axios .
- it is not possible to load external resources, use CSS, that is, there is no such display of the site as the browser;
- if you need to parse data from resources created using React technology, it can be difficult: these are mostly single-page sites (SPA).
- this library does not have direct interaction with sites: it cannot literally "press buttons", access information hidden behind scripts;
- very simple and logical syntax: guarantees quick and easy learning;
- fast speed.
Now let's move on to an example of creating your own parser using the Cheerio library.
Sequence of steps for creating a parser in Cheerio
To show how to create a parser in Cheerio from scratch, let's take as an example the task of extracting links to all blogs from the fairly popular In Plain English programming platform.
We start by creating a folder where our code will be stored. Let's call it "Scraper". Inside the parser itself, run the "npm init" command if you chose "npm" to work, or "yarn init" if your choice is "yarn". With these steps, you have created a folder in which the corresponding data will be saved and initialized "package.json". Now we can move on to installing packages. We perform the following actions:
- Install the Cheerio library. This work will require a minimum of time and effort from you. It will be enough just to run the command.

- Install the Axios library. This is a popular solution designed to run in Node.js to make HTTP-requests to the site we plan to scrape. By the way, it will be useful to read the difference between HTTP and SOCKS5 protocols. This library is best suited for making API-calls, receiving data from various Internet resources, etc. As a response from the site, we will receive an HTML-document, which can then be analyzed and retrieved the necessary information using Cheerio. To install Axios, run the following command in the terminal.
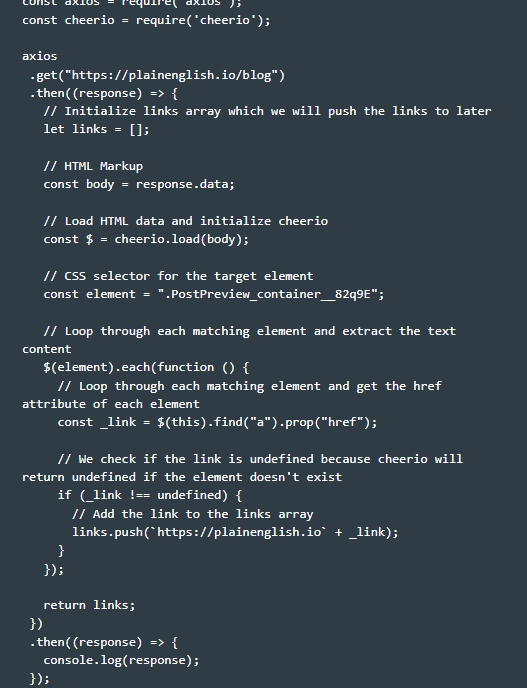
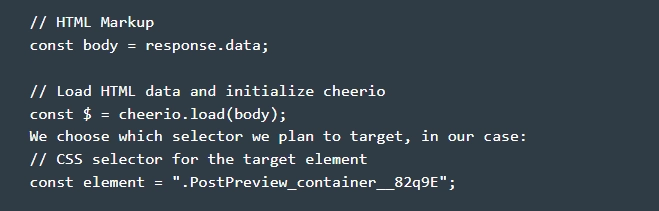
- Preparing the parser for work. To do this, we go to the folder we created earlier, and already in it we form a file called «cheerio.js». The picture shows the basic code structure, using which you can start parsing pages from sites using the Cheerio and Axios libraries.
- Requesting data. To do this, we need to run a Get-request. We send it to the site plainenglish.io/blog. Please note: Axios library – asynchronous, so we need to bind the Get (…) function to the Then (…) function. By doing this, we initialize an empty array of links in order to collect all those links that we plan to parse at the moment. Now all that's left is to drag and drop the «response.data» from the Axios library in Cheerio. To do this, execute the command.
- Processing the received data. We carefully look through all the elements in which the "a" tag is present. and pull out from the properties «href» corresponding value. Each found match is immediately moved to our array with links. Note that after these steps are completed, we return the references and run another chain of then(…) and console.log of the response. In practice, the actions at this stage will look like this.
- We get the final results. Now, after completing the first five steps, we can directly open the terminal from the parser folder and run "node.js"; and "cheerio.js". This will execute the complete code from our working "cheerio.js" file. The correctness of the actions you performed will be confirmed by the appearance on the console of all the URLs from the array of links that we used in the work. In general, you should see something like this on your screen.



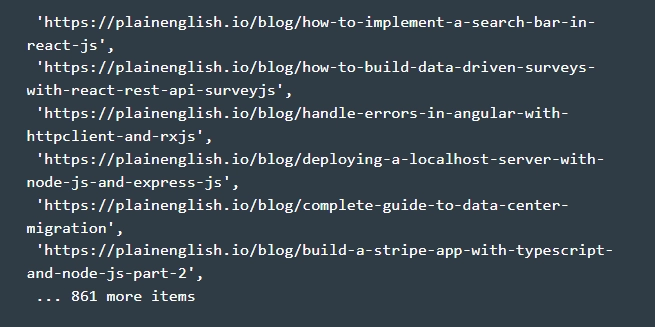
This completes data parsing using the Cheerio and Axios libraries from the In Plain English website. If necessary, the received data can be saved as a file in order to subsequently return to working with them again without resorting to re-parsing. As you can see, just a couple of lines of simple code, and you were able to extract data from sites that will become the basis of your future work. As an alternative to Axios, you can consider another HTTP-client – library Unirest.
Summing up
So when should you use the Cheerio library in your work? It will be the best solution when you are faced with the task of parsing data from static pages without direct interaction with them. That is, clicks, form submissions, link collection – this is something Cheerio can handle quickly and efficiently. But if you have to work with sites that use JavaScript to embed content, then you will have to look for another solution.
You also need to understand that the maximum efficiency of data scraping can be achieved through the use of different IP-addresses in the work. How to ensure it? Add dynamic mobile proxies to work. This way you can set an automatic change of addresses on a timer or use a Get request each time to force the change of the active address to another one. If you opt for mobile proxies from the MobileProxy.Space service, you will get access to almost a million pool of real addresses that mobile network operators allocate to their customers. You can also change the geolocation and operator at your own discretion, which will allow you to bypass any regional restrictions.
And these mobile proxies work simultaneously on the HTTP(S) and Socks5 connection protocols, providing absolute anonymity and confidentiality of network activities, protection from any unauthorized access. You can easily automate your actions on the Internet without fear of getting banned for it. More details about the features of MobileProxy.Space mobile proxies, as well as current tariffs, can be found at the link https://mobileproxy.space/user.html? buyproxy. The service also provides the possibility of a free 2-hour test. Use it to see how convenient and efficient working with reliable private mobile proxies can be.