Robots.txt index file: what is it and why is it needed

Often, those who are involved in the promotion and promotion of Internet resources, who work on creating sites, who control the stability of their work, have to deal with such a thing as a robots.txt index file. Together with the xml-map, it carries the most important information about the portal: it tells search engine bots how to read this site correctly, which pages on it carry the most important information, and which ones can be skipped and thrown out of consideration. And it is this file that should be viewed by specialists in the event that, for some reason, traffic to your Internet resource has sharply decreased.
Now let's take a closer look at what the robots.txt file is and why it is needed. Also pay attention to how to create the index file as correctly as possible. We will also talk about the main symbols that are used in robots.txt, we will tell you the mistakes that are often made by specialists in the process. And let's also dwell on how to ensure the most stable and secure work on the Internet using mobile proxies.
Introducing robots.txt
Robots.txt index file — it is a plain text document created in UTF-8 encoding. It is relevant for HTTP, HTTPS, FTP protocols. It is intended to provide crawlers with recommendations in the process of scanning pages or files. The fact is that in the case when the file is not built on UTF-8 characters, but on some other encoding, search bots can make errors in their processing. Therefore, it is important to understand that all these rules that are given in the index file will only be relevant in relation to the hosts, port numbers and protocols where this file is located.
This file is located directly in the root directory as a regular text document. Regardless of what devices and systems you work with, it will be available at the standard address https://site.com.ua/robots.txt. In purely technical terms, the index file — this is a description in Backus-Noir form, based on the rules of RFS 822.
All other files should be marked with Byte Order Mark (BOM). They are a Unicode character designed to specify a sequence in bytes during parameter reading. Its code symbol looks like U+FEFF. Note: the byte sequence mark at the beginning of the robots.txt file — ignored. It is also important to know that the search engine Google set its own limits on the size of the index file within 500 KB.
Starting from crawling your site for subsequent indexing, search bots process the rules contained in the robots.txt file and receive one of three instructions from it:
- Granting partial access. Assumes the ability to scan only certain elements of the site.
- Granting a total ban. The crawler is not allowed to crawl any of the pages.
- Grant full access. A search robot can crawl absolutely all pages of an Internet resource.
In the process of crawling the crawler index file (read here what crawling is) can get the following responses:
- 2XX. Indicates that the scan was successful.
- 3XX. Indicate that the search bot will follow the redirect until it receives some other response. Basically, the system allocates 5 possible attempts to get a response, which will be different from 3XX. After this limit, a 404 error is logged.
- 4XX. In this case, the search robot gets the rights to scan the entire content of the Internet resource.
- 5XX. Such commands are evaluated as temporary server errors. In this case, scanning is completely prohibited. Periodically, the robot will return to this index file until it receives a response other than 5XX. Additionally, here the Google search bot will be able to determine the correctness of the response settings from those pages of the site that are missing. That is, the page will still be processed with a 404 response code.
There is no information yet on how the index file will be handled if it becomes unavailable due to internet connection issues.
Who needs the robots.txt file and why?
We said above that this index file — This is a tool for the work of specialists who monitor the performance of the site and its promotion in the search results. Use robots.txt when you want to prevent crawlers from crawling the following pages:
- with personal information of users on the site;
- with certain forms of sending data;
- with search results.
You can also set a ban on visiting mirror sites. It is also important to understand that even if the page is inside the robots.txt file, it can still appear in the search results. This is relevant for cases when there is a corresponding link to it either on some external resource or inside the site. It turns out that without an index file, all the information that needs to be hidden from prying eyes can still get into the search results. This can cause significant harm to both your resource and you personally.
In work, everything looks quite simple. As soon as Google stumbles upon a robots.txt file, it automatically understands that it needs to find the appropriate rules and crawl the site in accordance with them.
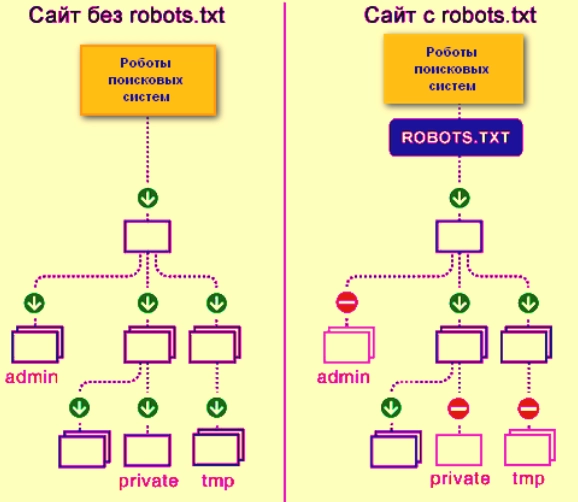
The picture clearly shows what site crawling looks like without the robots.txt file and with it:
Creating the index file properly
You can create a robots.txt file using any text editor, including copying. The content of this file should contain:
- Full User-agent statement.
- Disallow rules.
- Allow rules
- Sitemap rules.
- Rules for Crawl-delay.
- Clean-param rules.
Let's consider all these points in more detail.
User-agent like a business card for robots
User-agent — this is a rule that indicates which bot you need to look at the instructions given in the robots.txt file. Today there are over 300 search crawlers. Therefore, it makes no sense to prescribe all of them separately. A simpler and more reliable solution — using one entry for all. Google has its own master bot — Googlebot. At this stage, you can specify that the rules need to be viewed by this particular search robot. Other crawlers will crawl the site directly, assuming the index file is empty.
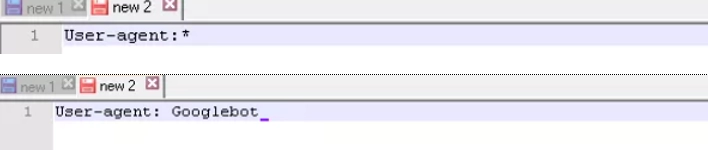
In the picture in the top line there is an option to write the User-agent rule for all search engines, and in the bottom line— only for Googlebot.
We also recommend that you pay attention to a number of other special bots optimized for scanning certain types of files:
- Mediapartners-Google — for the AdSense service;
- Googlebot Image — for working with images;
- AdsBot-Google — to check the quality of the landing page;
- Googlebot Video — for video files;
- Googlebot-Mobile — for the mobile version of the software.
Disallow rules
Disallow provides recommendations to search bots on which parameters they should exclude from crawling.
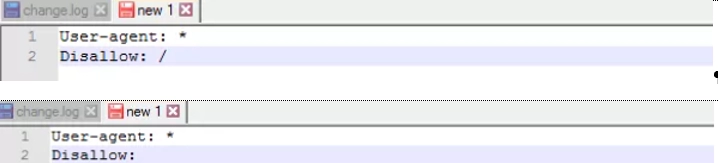
At the top line you see an example of how to prevent all material on the site from being crawled, and at the bottom— gives permission for a full site crawl. The first option should be used if your site is still under development, and you do not want it to appear in search results in this form. As soon as the work on setting up the resource is completed, it will be important to correct this rule, thereby making your site available to the target audience. This point must be taken into account by the webmaster.
It is also possible, through this rule, to provide robots with an instruction containing a ban on viewing the contents of a folder, a specific URL, a particular file, and even files of a certain extension.
Allow Rules
This rule involves granting permission to scan a specific file, page, or directive. Both Allow and Disallow are sorted by the length of the URL prefix, starting from the smallest to the largest. They are applied sequentially. In the event that several rules can be used for the same page, the search robot will focus on the one that turns out to be the last one in the sorted list.
As an example, let's show how to allow bots to view only pages that start with /catalog. At the same time, all other content will remain closed.

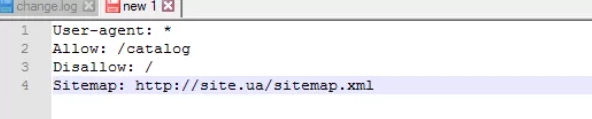
Sitemap Rules
Sitemap — it is a kind of medical site map. It tells the search bot all those URLs that will be required to be crawled. They are located at the standard address https://site.ua/sitemap.xml. Each time crawling, the crawler will check what changes were made to this document, and based on this it will add more recent and up-to-date information about the site to the browser database.
In the picture you see an example of how this instruction should be written in this file.
Crawl-delay rules
Crawl-delay – this is a parameter that allows you to set the interval through which the pages of the site will be loaded. This rule will be especially relevant in the case when you work from a rather weak server, that is, there may be significant delays in the process of the bot accessing the resource pages. Please note that this parameter must be set in seconds. It is also important to know that today Google no longer supports this directive, but it remains relevant for other search engines.
An example of setting a stopwatch for weak servers:

Clean-param rules
Clean-param. This rule provides an effective fight against GET parameters in order to avoid duplicate content. You can find it at different dynamic addresses (there is a question mark in the name). such addresses will appear if the site has different sortings, including session IDs.
The picture shows the addresses where a certain page will be available, as well as what the robots.txt file will look like for this case.
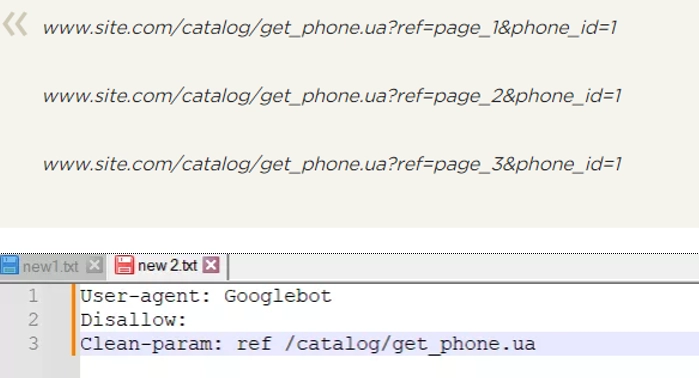
Please note that the REF option is written at the very beginning here, as it indicates where exactly this link comes from.
A little about the symbols in the index file
There are basically four different types of character used when working with an index file:
- Slash. It is used to share what we want to hide from being discovered by search bots. If there is only one slash, then Disallow is supposed to prohibit a full site scan. If you highlight a separate directory on both sides with a slash, it means that it is forbidden to scan it.
- Asterisk. Points to any sequence of characters in a file. Placed after each rule.
- Dollar sign. Assumes a limitation of the effect of the "asterisk" sign. Used when you want to prevent scanning of the entire contents of a folder, but you cannot prevent URLs containing the name of this folder.
- The hash mark is for writing comments. With its help, the web master can leave notes both to himself and to his colleagues. Search robots will not take them into account when crawling the site.
Some things to consider when working with an index file
After you fill in the robots.txt file, it needs to be checked for correctness. For this, a special online tool from the masters of the Google search engine is used. You will need to go to it and enter a link to the site being checked.
When filling out an index file, specialists often make a number of mistakes. Most of them are associated with haste or inattention. Most common:
- messed up instructions;
- record in one Disallow instruction of several folders or directories: each must be written in a new row;
- correct — only robots.txt, not Robots.txt, ROBOTS.TXT or other variations;
- leaving the User-agent rule empty: be sure to specify which robot should take into account the rules specified in your file;
- the presence of extra characters in the file, including slashes, asterisks, etc.;
- adding pages to the file that a priori should not be indexed.
How to ensure stable work of a webmaster on the Internet?
The work of webmasters is often associated with increased risks. There is a high probability of catching virus software, becoming a victim of malicious hacking, etc. In addition, it is important for them to ensure multi-threaded actions in order to develop the most comprehensive strategy for the development of a particular resource mobile proxies from the MobileProxy.Space service will effectively cope with these tasks. With their help, you can:
- Effectively bypass regional locks;
- Ensure yourself complete anonymity and confidentiality of the network;
- protect against any unauthorized access, including hacker attacks;
- work in multi-threaded mode, including using programs to automate actions.
Follow https://mobileproxy.space/en/user.html?buyproxy to learn more about it functionality and tariffs of mobile proxies, as well as take advantage of a free two-hour testing of the product before buying it.